What is MLOps?
Versioning of features and models using an MLOps platform
This blog explores MLOps principles, with a focus on versioning, and provides a practical example using Hopsworks for both data and model versioning.

Introduction
Getting started with machine learning models is relatively easy, but the process of deploying them can be quite challenging. In fact, a staggering statistic reveals that a significant amount of projects (87% of data science projects) never make it into production. The reason for that is quite straightforward. In traditional software engineering, your main concern revolves around code, but in ML engineering the concern extends to include both the data and the model as well.
The maintenance required of data and models creates new challenges for data scientists. For example, monitoring of deployed models, automated testing and upgrade/adaptation of code, model and/or data. MLOps provides comprehensive solutions for these challenges. The most common problem is that the real world is in a state of constant flux. Adapting the code and data pipelines to accommodate new data sources, feature changes, or updated business requirements without causing any disruption is a substantial challenge.
MLOps solves this problem by introducing versioning that allows a data scientist to keep track of data and model versions. Versioning allows for the data persistence, facilitates rollbacks from incorrect updates, and simplifies the debugging of working models. This makes it one of the crucial parts of the model development life cycle. This blog will give a comprehensive explanation to what MLOps is and how versioning is used in the ML lifecycle for creating model iterations.
What is MLOps?
Machine Learning Operations (MLOps) is a set of best practices to streamline the process of taking ML models to production and then monitoring and maintaining them. MLOps makes collaboration and deployment easier as it unites ML development and operation.
MLOps is based on three principles, which are
-
Observability refers to the ability to watch the performance and behavior of ML models already in production. The performance of the model in the real world has to be continuously monitored to identify anomalies and issues, which makes the model much more reliable to the users.
-
Automated testing enables you to build ML systems with confidence that will catch any potential bugs in your data or code. This helps reduce the unanticipated requests from the users by knowing models' capabilities and constraints.
-
Versioning refers to creating and registering multiple versions of the model in an iterative process. It allows developers to compare performance across various models and roll back to a stable version while accommodating ongoing improvements.
In this article, we will cover versioning in detail. This article will also show a practical example of versioning using Hopsworks**.**
What is Versioning and Why Is It Important in MLOps?
Versioning in computer science tracks and controls all changes applied to a software application. It allows easy rollback to a previous, stable version when needed. In the present IT ecosystem, this concept has spanned the data science space, allowing versioning of data, features, and ML models.
In the figure below, when the model is upgraded from version 1 to version 2, the features are changed from transaction_v1 to transaction_v2. This means it’s the requirement for the model fraud_v2 to have the correct features on deployment, and If there is any problem with the newer model, we can easily roll back to previous versions.
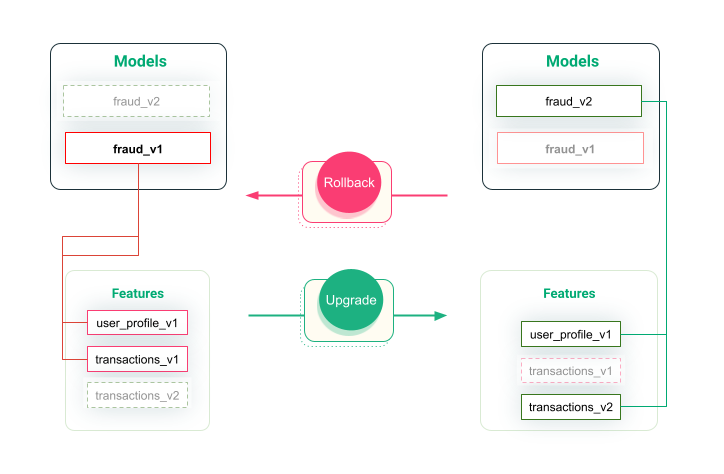
Figure 1: Versioning Models and Features
Versioning in MLOps vs DevOps
Both DevOps and MLOps are advocates of versioning, but their objectives are different. DevOps, as a holistic approach, emphasizes collaboration across the software development lifecycle, which ensures that the application runs smoothly by using tools like automated testing, deployment, setting up the necessary infrastructure, and managing configurations.
On the other hand, in the realm of MLOps, versioning takes on a more specialized role, concentrating specifically on machine learning models and their deployment. MLOps focuses mainly on versioning of data and models. It also prioritizes model performance in production, with an emphasis on monitoring, hyperparameter tuning, feature selection, model interpretability, and fairness.
Why is Versioning Important?
Versioning has become an integral part of the machine learning development cycle. It allows data scientists to register multiple versions of their trained models. The multiple versions can be used to compare performance against various training methodologies, perform A/B testing, and revert to previous versions in case of sudden performance loss.
These use cases help developers determine effective training techniques and features for the best performance. They also ensure stability and high performance in the production environment for enhanced user experience.
Introduction to Hopswork Feature Store & Model Registry
Hopswork is on a mission to build and operate feature pipelines, training pipelines, and inference pipelines (FTI pipelines) easily. For versioning in MLOps, we will glance at the feature store for data versioning and the model registry for model versioning.
Feature Store
Hopsworks Feature Store provides the HSFS ( Hopswork Feature Store ) API to enable clients to write features to feature groups in the feature store and to read features from feature views. You can access these features using a low-latency Online API for operational models or a high-throughput Offline API for creating training data and retrieving batch data.
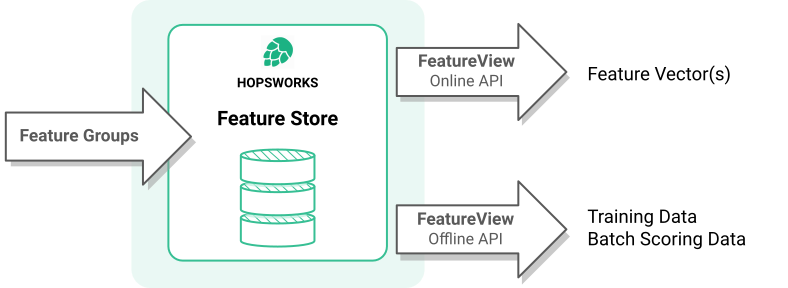
Figure 2: Overview of Hopsworks Feature Store
- Feature Group: A variable associated with an entity containing a value that is useful in training a model is called a feature e.g area in sq/ft for predicting house prices. A feature group is a table of features, where each feature group has a primary key, and optionally an event_time column and a partition key.
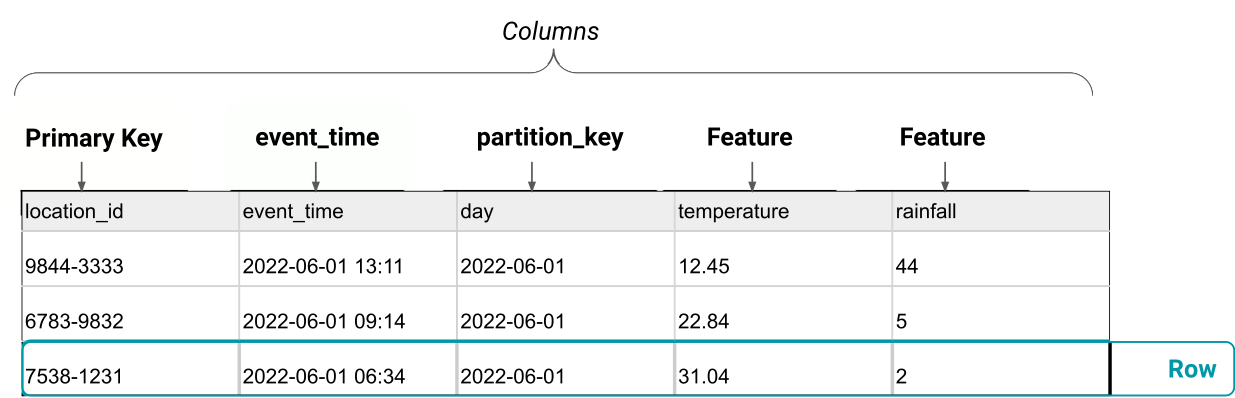
Figure 3: Example of a Feature Store
The concept of versioning in Hopsworks works on two dimensions: metadata versioning (e.g. schemas) and data versioning.
-
Metadata versioning: The feature group schema is versioned. If you make a significant schema change, you must increase the version and backfill the new feature group. This includes dropping a column, adding a new feature without a default value, or altering how a feature is computed, making old and new data incompatible. These changes are called breaking schema changes. For example, let’s make a new version for a dataset with added features:
-
Data versioning: Data versioning in Hopsworks records various data commits added to a feature group, ensuring uniformity in schema structure and feature definitions within the same schema version. This capability is available for offline feature groups, while online feature groups store only the latest values for a primary key. Data versioning is less vital for training datasets, which represent point-in-time snapshots of specific features. Here’s how to retrieve a previous commit from feature group:
Model Registry
Hopsworks Model Registry is built to support KServe (Standard Model Inference Platform on Kubernetes, built for highly scalable use cases) and MLOps, emphasizing version control. It allows developers to publish, test, monitor, govern, and collaborate on models with other teams. During experimentation, developers use the model registry to publish and, later, share models with their teams and stakeholders.
HSML is the library to interact with the Hopsworks Model Registry and Model Serving. The library makes it easy to export, manage and deploy models. After connecting to Hopsworks, versioning the model is just a few lines of code:
Implementing A Feature Pipeline using Hopsworks
In this practical example, we will be using an income census which is an open source dataset and the task is to train a model to predict whether an individual income will be greater than 50k. The plan is to make two different versions of data and train a model on them. The first version of the dataset will contain only numeric variables. In the second version, the dataset will include some categorical variables, and we will version a different model for it as well.
The notebook used for this example can be found here.
Feature Pipeline Version 1
Data Ingestion: Download the dataset from kaggle and load it in the working environment.
The columns for the dataset are as follows:
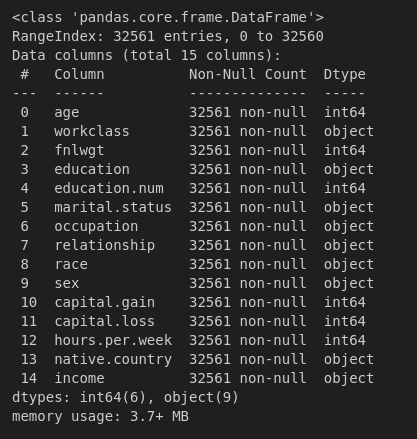
Figure 4: Information of the Dataset
The dataset has a few problems. It contains duplicates, missing values, and income is an object rather than binary for classification. In the next few steps, we will clean the dataset.
-
Removing Duplicates: Some of the rows are repeated, so we are required to remove them. To achieve this, pandas has a function drop_duplicates to remove the duplicates.
-
Mapping Labels: The problem is to predict whether the person will have income greater or less than 50k. So, it is required to map the income column to binary [0,1] making it suitable for binary classification.
-
Handling Missing Values: The dataset contains missing values as ?, there are many ways to handle it. We can replace it with the average or median of the entire column values. Here for simplicity, We will remove them.
Integration with Hopsworks Feature Store: We need to establish a connection to the Hopsworks Feature Store, enabling access to its functionalities. First, we would require a Hopsworks account. If you don't have it already, hop on to their login page, It's free. Make sure to pip install hospwork first.
After it runs successfully, It will ask for api_key, which can be generated by following the link it provides.
Feature Group Creation and Integration: Before we create a feature group and insert income dataset into it, we need to perform feature engineering. To keep it simple, In the first version of data, we will check the prediction accuracy by only considering numerical features. In the second version of data, we will further explore the data by analyzing both categorical and numerical features and we will engineer the features accordingly in the hope of getting better accuracy.
Now, we are ready to insert the first version of data into the feature store. Since each feature group has a primary key, we need to create a primary key for the dataset. Let’s add a column of index for it.
Also, some of the names of the columns are not formatted according to the guidelines of hopsworks. For example education.num should be education_num.
To create a feature group, we simply need to define the name, version, description and primary key of the dataset to be included.
Let’s insert the dataset into the feature group:
The first version of the dataset is created.
Specify Data Transformation Logic: In order to preserve the shape of the distribution of the dataset, we need data transformation logic. Hospwork supports custom functions as well as built in functions for data transformation. Here we will use min max scaler for transforming the numerical features.
Generate Feature Views: A feature view serves as a structured interface to a collection of features, which could originate from various feature groups. You create a feature view by joining together features from existing feature groups. A feature in a feature view is not only defined by its data type (int, string, etc) or its feature type (categorical, numerical, embedding) but also by its transformation. Here’s how to create the feature view:
Firstly, get the feature group:
Second, we specify which columns to include in the feature view. The index is neglected since it does not provide any useful information.
Third, simply pass the transformation function and query to the feature view to create one.
Model Training Pipeline Version 1
Prepare Training Dataset: Since we have created the feature view, It is possible with 2 lines of code to construct a training dataset for training, validation, and testing. For this dataset, the partition is 80% training set and 20% test set. Here’s how to create the train test split using feature view.
Provided the version of the corresponding feature view the training and testing set is created. After this we are ready to train our model.
Model Training: For the first version of the model we will go with logistic regression. Let’s see that in action
The accuracy for the model is 73.8. Now, we will use the hsml API to access the model registry and record the first version of the model.
Record Model Version 1: In order to record the version of the model, a model schema is required to describe its inputs and outputs. It can be generated by training examples as follows:
To save the model:
Now we will get the model registry and create the model repository. Hopsworks support different integrations like tensorflow, scikit-learn and much more.
This will save the first version of the model.
Feature Pipeline Version 2
In the second version, we will also consider categorical variables which will be a breaking change for the previous feature group.
Feature Engineering: Through the visualization of numerical and categorical features, it becomes evident that valuable insights can be gleaned from the dataset through effective feature engineering. As this article focuses on versioning, we aim to keep the explanation straightforward. Upon visualization, we observed the exclusion of the fnlwgt feature and the encoding of sex and workclass, as detailed in the notebook.
-
Fnlwgt
-
Sex
-
Workclass
So, we have added two features and removed one. Let’s drop everything else from the data.
Just like before we will add the index as primary key and rename according to the guidelines of hopswork.
Version Feature Group: Modify the existing feature groups and integrate them into the Feature Store to reflect updates in a newer version of the data. Since we have already connected the feature store, we just need to increment the version.
Specify Data Transformation Logic: This is the same step as before, but with added features:
Generate Feature Views: Simply increment the version number with the same name of the view as before.
Model Training Pipeline Version 2
Prepare Training Dataset: After creating the feature view, it is very easy to create a train test split and we will do the same as for V1.
We can easily retrieve the training and test set as follows:
Different Model Training: Training a different machine learning model using the prepared dataset. This time, we will use xgboost. Make sure to pip install xgboost first.
This time the accuracy of the model is 84.8 which is better than the previous model. Now we will record it in the model registry.
Record Model Version 2: Store and register the second version of the trained model in the Hopsworks Model Registry. We will create the schema just like before and save the model. To save in the model registry:
Summary
The deployment of ML models is a significant concern in the field of AI. Throughout this blog, we sought to answer the question of what MLOps is and how versioning is used in MLOps. In its simplicity, MLOps is a set of best practices that makes it easier to deploy models. Versioning is one of the practices of MLOps that is supported in Hopsworks and can be used for both data versioning and the model versioning.
Data Versioning: Hopsworks ensures data consistency by tracking changes in feature group schemas, making it perfect for training datasets that require stable snapshots of features.
Model Versioning: Hopsworks Model Registry simplifies collaboration by enabling the versioning of models. This feature is essential for publishing, testing, monitoring, and debugging models.
We have also seen the complete example of versioning features and models. Now, if one model fails despite having better accuracy ( The second model may generate gender bias results due to the inclusion of gender as a feature ), we can quickly switch to another model.