End-to-end Deep Learning Pipelines with Earth Observation Data in Hopsworks
In this blog post we demonstrate how to build such a pipeline with real-world data in order to develop an iceberg classification model.

Introduction
In the blog post AI Software Architecture for Copernicus Data with Hopsworks we described how Hopsworks, the data-intensive AI platform with a feature store, brings support for scale-out AI with Earth observation data from the Copernicus programme and the H2020 ExtremeEarth project. This blog post is a continuation of the previous one as we dive into a real-world example where we describe how to build and deploy a machine learning (ML) model using a horizontally scalable deep learning (DL) architecture that identifies if a remotely sensed target is a ship or iceberg.__
An extended version of this blog post is available as deliverable “D1.8 Hops data platform support for EO data -version II” of the H2020 ExtremeEarth project published in June 2021.
Pipeline
In order to develop and put in production a machine learning model, the input data needs to be processed and transformed through a series of stages. Each stage serves a distinct purpose and all the stages chained together transform the input Earth observation data into an ML model that application clients can use. For the ship/iceberg classification model described in this example, these stages are listed below and described in detail in the following sections:
- Data ingestion and pre-processing
- Feature Engineering and Feature Validation
- Training
- Model Analysis, Model Serving, Model Monitoring
- Orchestration
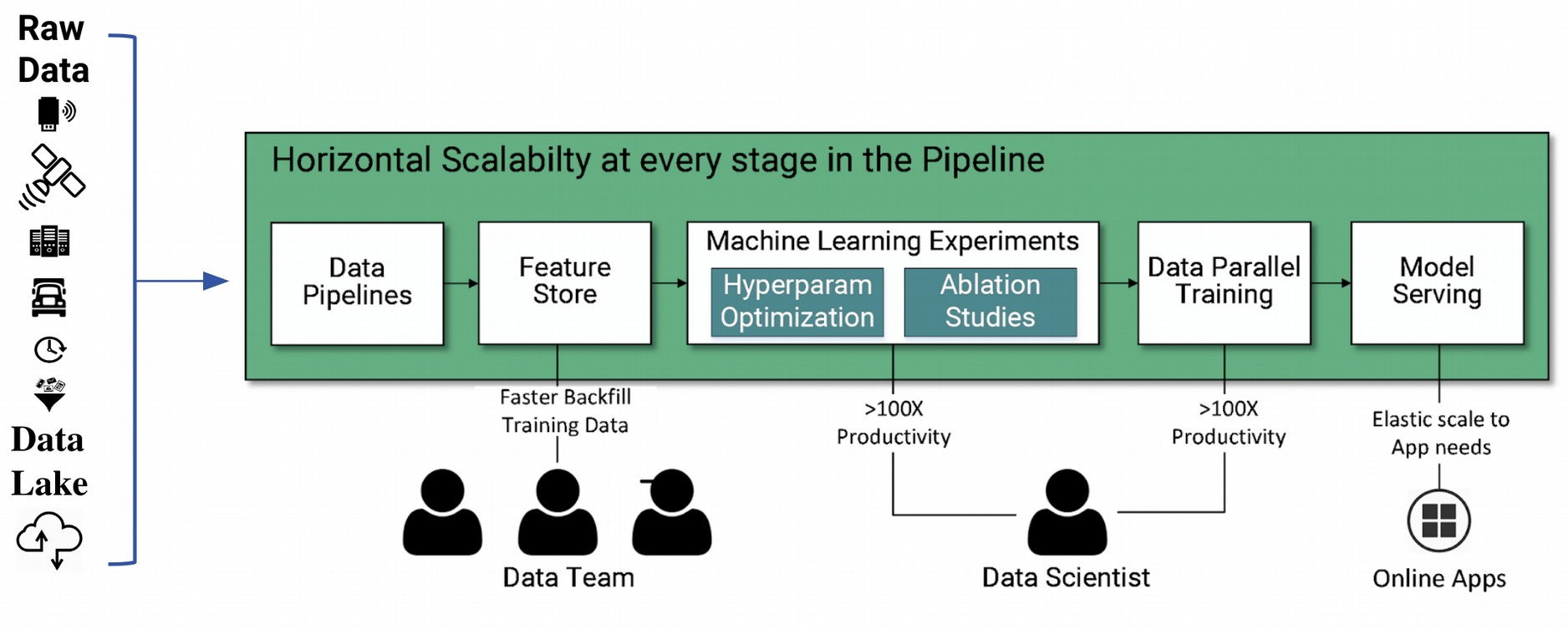
End-to-end ML pipeline stages
Dataset
A requirement for this example is to use a free and publicly available dataset in the Earth observation domain. As such, we opted for the “Statoil/C-CORE Iceberg Classifier Challenge - Ship or iceberg, can you decide from space?” [1] hosted by Kaggle which is an online community of data scientists and machine learners, and is distributed for free.
The schema for the Statoil dataset is presented in the figure below. The data is in json format and contains 1604 images. For each image in the dataset, we have the following information:
- id - the id of the image.
- band_1, band_2 - the flattened image data. Each band has 75x75
- pixel values in the list, so the list has 5625 elements. Band 1 and Band 2 are signals characterized by radar backscatter produced from the polarizations to HH (transmit/receive horizontally) and HV (transmitted horizontally and received vertically).
- inc_angle - the incidence angle of which the image was taken.
- is_iceberg - set to 1 if it is an iceberg, and 0 if it is a ship.
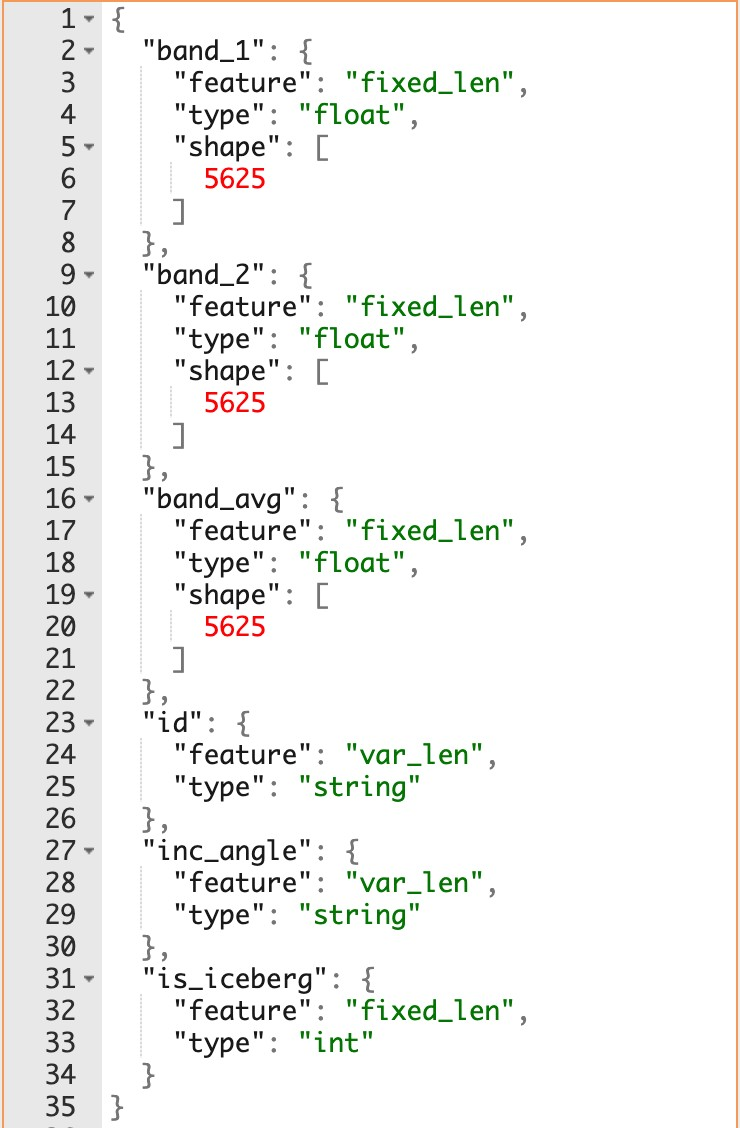
Schema of the Statoil demonstrator dataset
Data ingestion and preprocessing
Hopsworks can ingest data from various external sources and it is up to the users to decide the most efficient approach for their use cases. Such data sources include object stores such as Amazon AWS S3 or Azure EBS, external relational databases that can be accessed via protocols such as JDBC and of course the data that resides in the local filesystem. Another option, which has followed for the purposes of this article, was to upload the input data via the Hopsworks UI which makes use of the Hopsworks REST API. This way, day is readily available to applications running in Hopsworks from within the project’s datasets.
Often times data needs to be pre-processed, that is transformed into data ready to extract ML features from and eventually use it as training/test data. In the Earth observation domain, such preprocessing steps might involve applying algorithms implemented in arbitrary languages and platforms. For example, the European Space Agency (ESA) is developing free open source toolboxes for the scientific exploitation of Earth Observation missions. ESA SNAP [2] is a common architecture for all Sentinel Toolboxes. To make it easier for developers to work with SNAP, the toolbox has been containerized and is made available by different organizations such as mundialis [3] to be run as Docker containers. Hopsworks as of version 2.2.0 supports running docker containers as jobs in Hopsworks. That means users can seamlessly integrate running Docker containers as part of their pipelines built in Hopsworks [4].
Feature Engineering and Feature Validation
After having ingested the input data into the platform and applied any preprocessing steps, we proceed by engineering the features required by the deep learning training algorithm. Feature engineering in this example is done within Hopsworks by using Jupyter notebooks and Python. Feature engineering can also be performed by an external service and the curated feature data can then be inserted into the Hopsworks feature store. The latter is the service that allows data scientists to store, organize, discover, audit and share feature data that can be reused across multiple ML models.
In the iceberg classifier example above, we use the band_1 and band_2 features to compute a new feature called band_avg. All the features are then organized into a feature group and inserted into the feature store as shown in the code snippets image below.
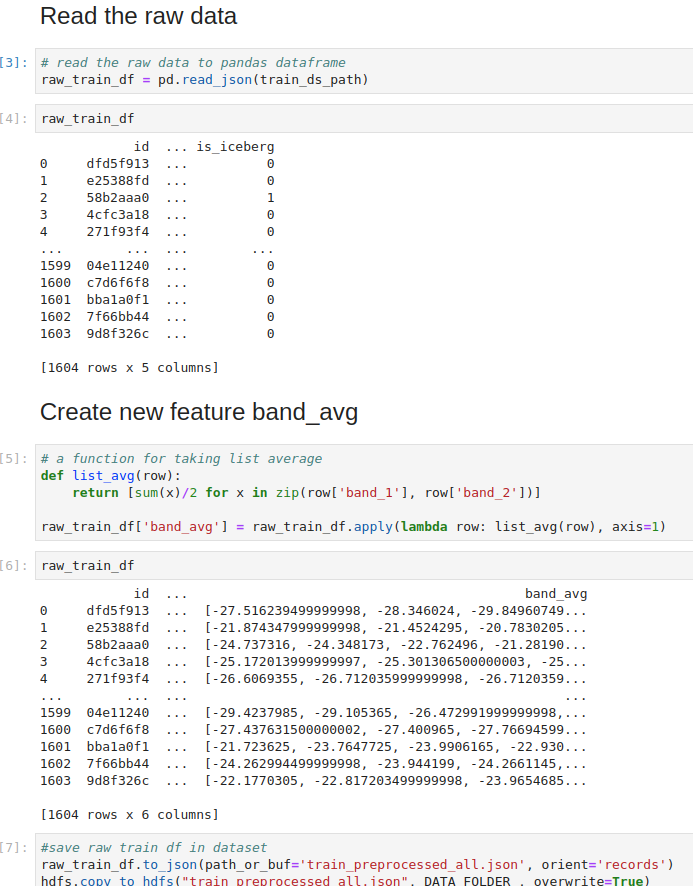
Create a new feature band_avg
Input data often contain noise, for example missing feature values or values of the wrong data type. Since the feature data needs to be ready for use by the ML programs, when inserting data into the feature store developers can make use of the feature validation API which is part of the feature store Python and Scala SDKs [5]. This API provides a plethora of rules that can be applied on data as that is being inserted into the feature store.
In the iceberg feature group example we chose to apply three validation rules:
- HAS_DATATYPE: Asserts that the feature id of the iceberg feature group does not contain null values. This is asserted by setting the max allowed null values to zero. Additionally, the is_iceberg label is also expected to only contain numbers by setting the threshold for required numeric values of is_iceberg to 1.
- HAS_MAX: Assertion on the maximum allowed value of the is_iceberg label, which is set to 1.
- HAS_MIN: Assertion on the minimum allowed value of the is_iceberg label, which is set to 0.
These rules are grouped in feature store expectations and can be set during the feature group creation call as shown in the image below.
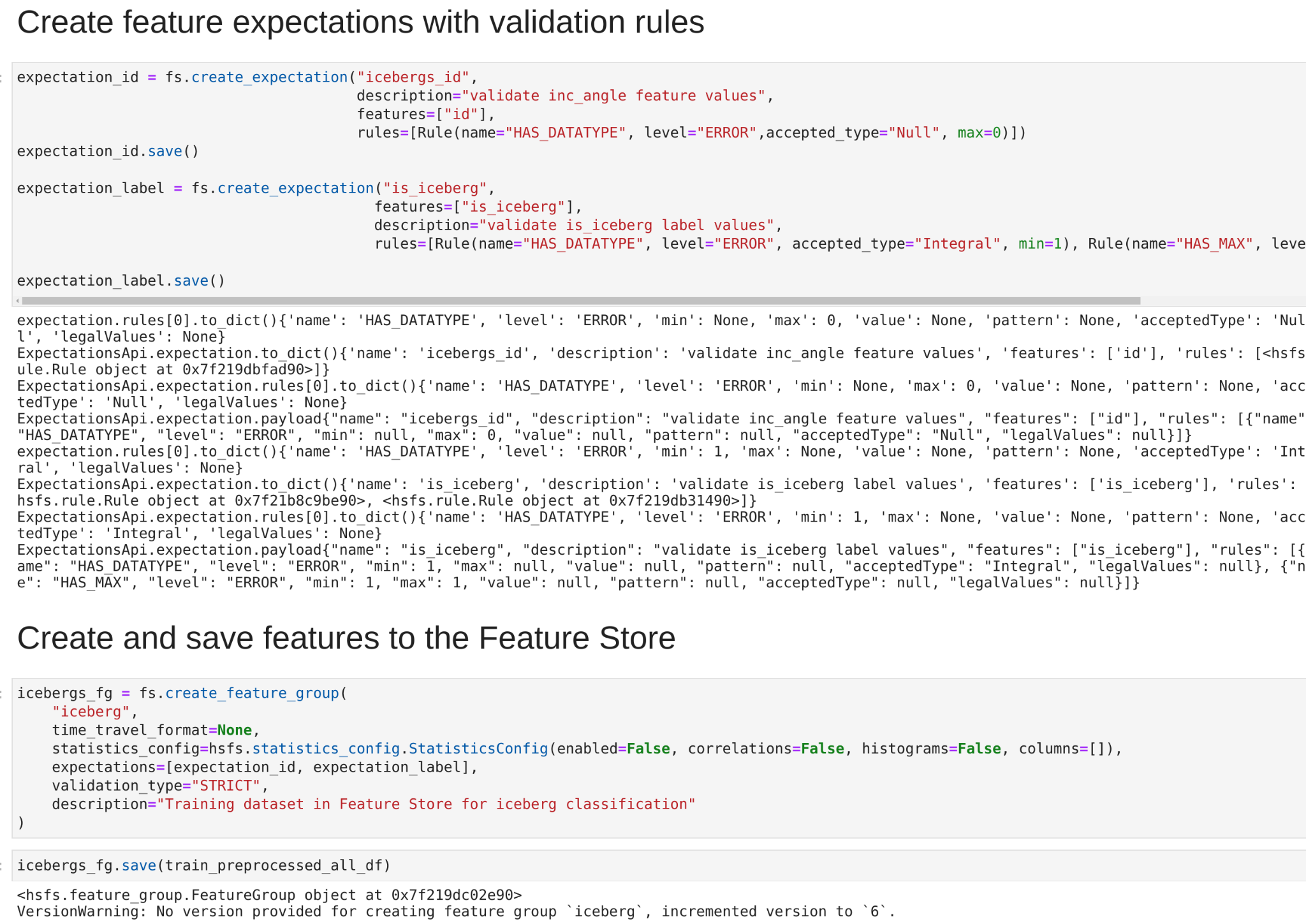
Feature expectations Python API example
Training
Hopsworks comes equipped with two Python frameworks, namely experiments [6] and Maggy [7], that enable data scientists to develop machine learning models at scale as well as manage machine learning experiment metadata. In particular, these frameworks enable scalable deep learning with GPUs across multiple machines, distribution transparent machine learning experiments, ablation studies, and writing core ML training logic as oblivious training functions. Maggy enables you to reuse the same training code whether training small models on your laptop or reusing the same code to scale out hyperparameter tuning or distributed deep learning on a cluster.
This example uses TensorFlow version 2.4 for developing the model. When launching a machine learning experiment from Hopsworks, the Jupyter service provides users with different options depending on what type of training/experimentation is to be done. As seen in the image below, these types are Experiment, Parallel Experiments, Distributed Training. Experiment is used to conduct a single experiment while Parallel Experiments can significantly speed up the process of exploring hyperparameter combinations that work best for the ML model. Distributed Training automates the process of setting up and launching workers that will develop the model based on the selected distributed training strategy.
For example the screenshot below shows how to perform hyperparameter optimization with Maggy for the iceberg classification example.
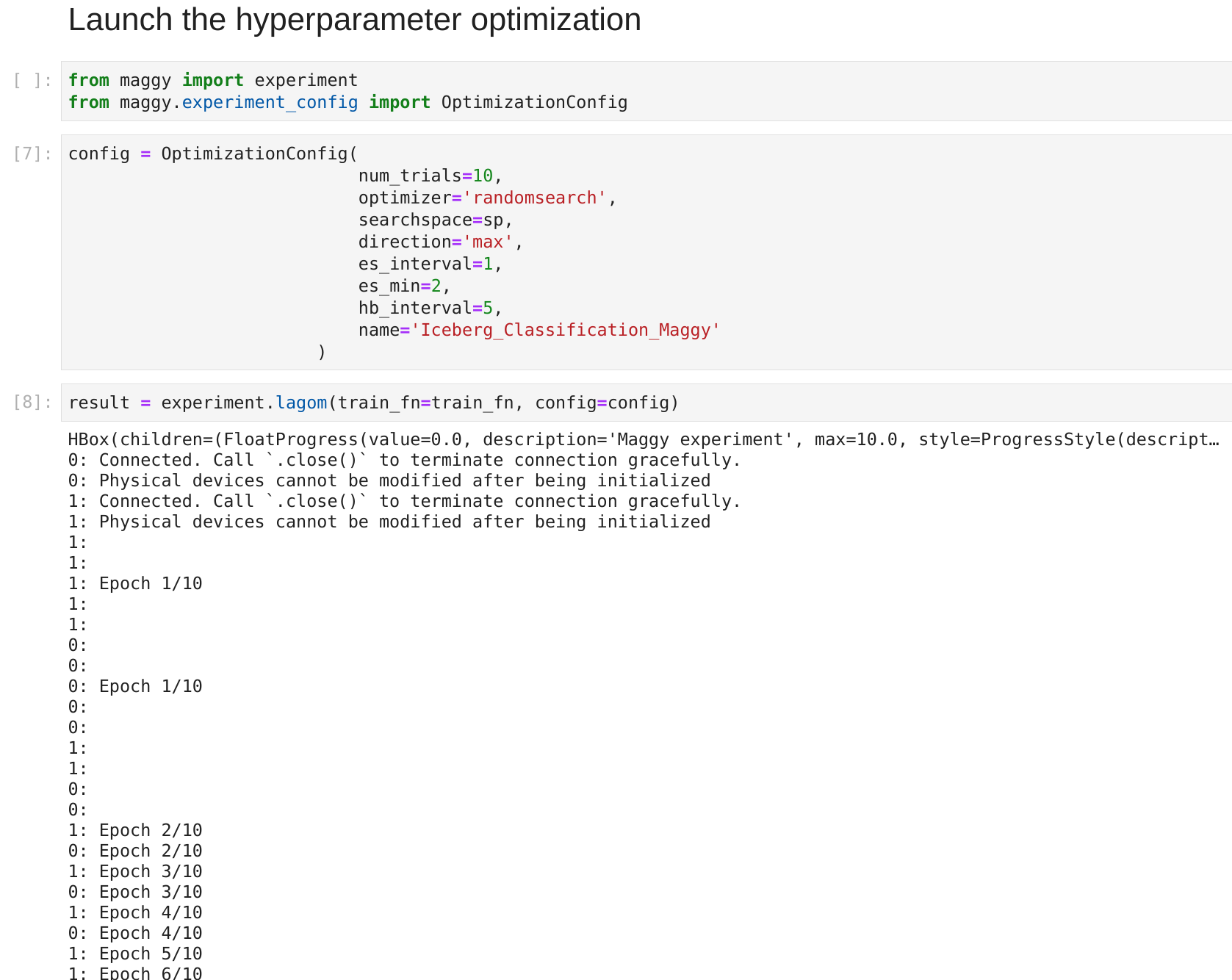
Iceberg hyperparameter optimization with Maggy - launch
Once all trials are executed, a summary of results is printed as the final output.
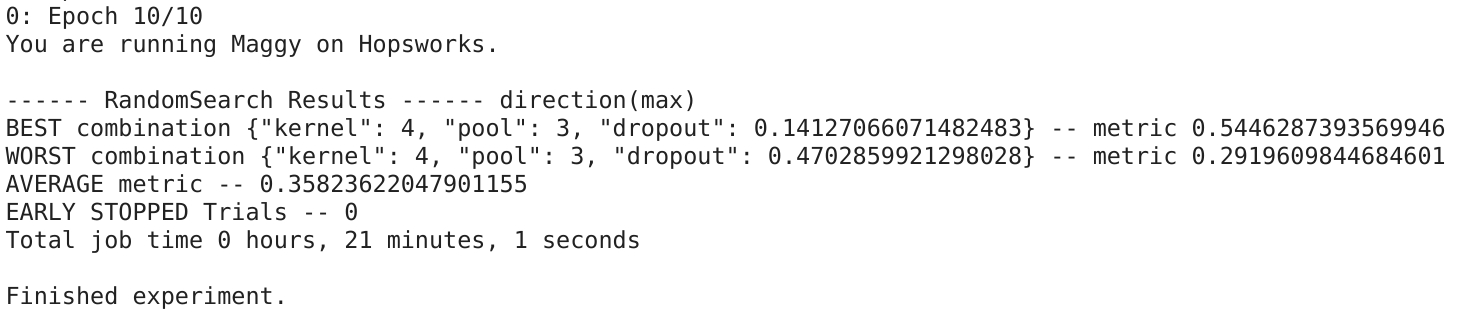
Iceberg hyper-parameter optimization with Maggy - results
For distributed training, the same model was used as in the previous sections, however, Jupyter was started with the Distributed Training configuration.

Iceberg distributed training function

Iceberg distributed training experiments API launch
In the context of machine learning, we can define an ablation study as “a scientific examination of a machine learning system by removing its building blocks in order to gain insight on their effects on its overall performance”. With Maggy, performing ablation studies of machine learning or deep learning systems is a fairly simple task that consists of the following steps:
- Creating an AblationStudy instance,
- Specifying the components that you want to ablate by including them in your AblationStudy instance,
- Defining a base model generator function and/or a dataset generator function,
- Wrapping your TensorFlow/Keras code in a Python function (called e.g., the training function) that receives two arguments (model_function and dataset_function), and
- Launching your experiment with Maggy while specifying an ablation policy.
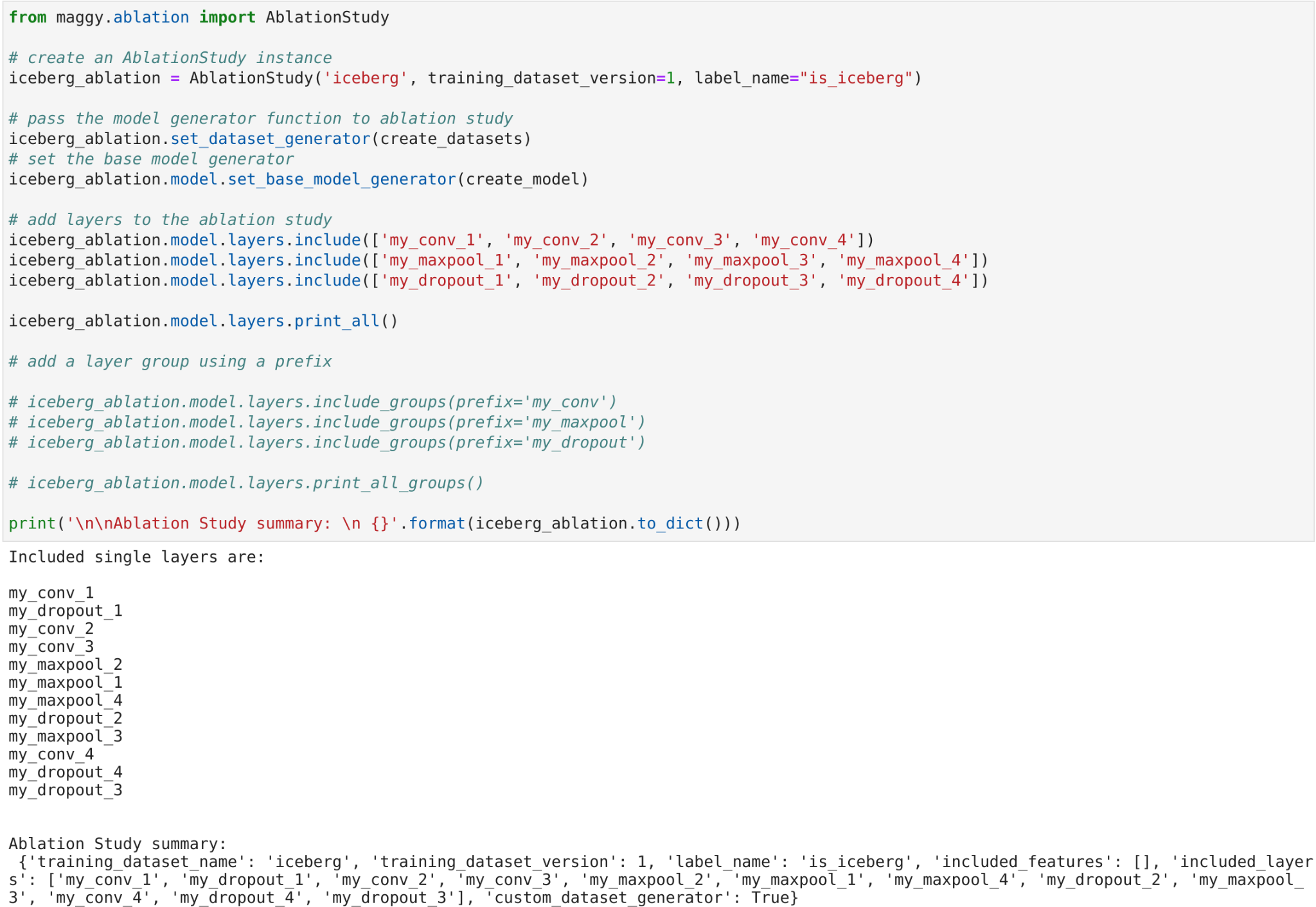
Maggy ablation studies notebook example - ablations
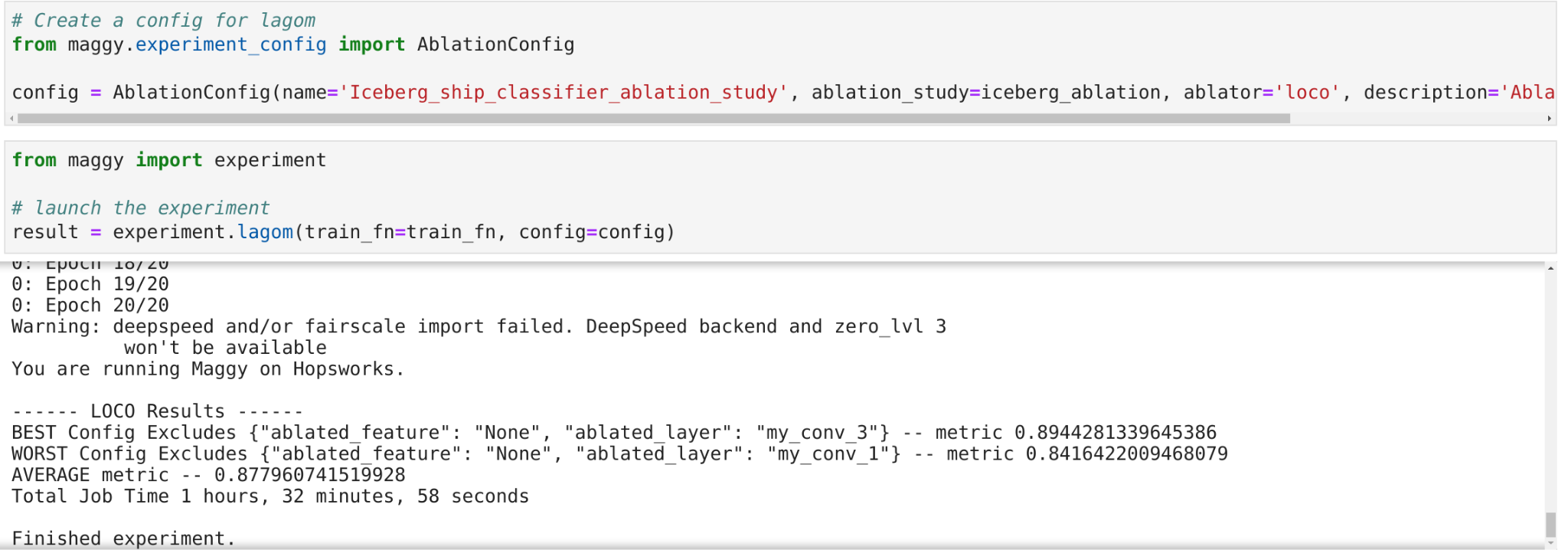
Maggy ablation studies notebook example - results
Model: Analysis, Serving, Monitoring
Data scientists working with Hopsworks can make use of the What-If [8] tool to test performance in hypothetical situations, analyze the importance of different data features, and visualize model behavior across multiple models and subsets of input data, and for different ML fairness metrics. The What-If tool is available out of box when working within a Hopsworks project.
Below you can see the code snippet used to perform model analysis for the sea iceberg classification model developed with the demonstrator dataset in this deliverable. Users set the number of data points to be displayed, the test dataset location to be used for analysis of the model, and the features to be used.

Model analysis what-if tool code snippet
The next screenshot depicts the performance and fairness of the model based on a particular feature of the model.
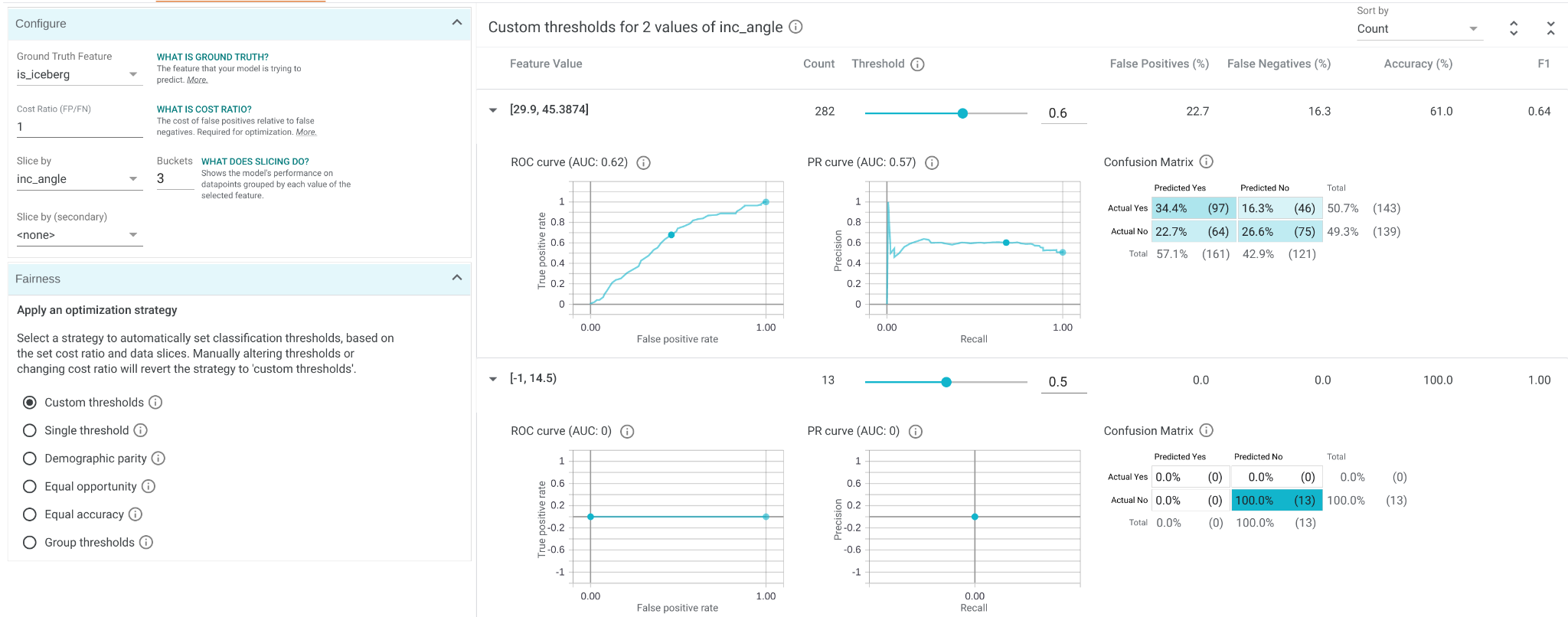
Performance and Fairness of the model
After a model has been developed and exported by the previous stages in the DL pipeline, it needs to be served so that external clients can use it for inference. Also as the model is being served, its performance needs to be monitored in real-time so that users can decide when it would be the best time to trigger the training stage. For the iceberg classification model, Hopsworks uses TensorFlow Model Server on Kubernetes to serve the model in an elastic and scalable manner and Spark/Kafka for monitoring and logging the inference requests. Users can then manage the serving instances from the Hopsworks UI and view logs as shown in the screenshot below.
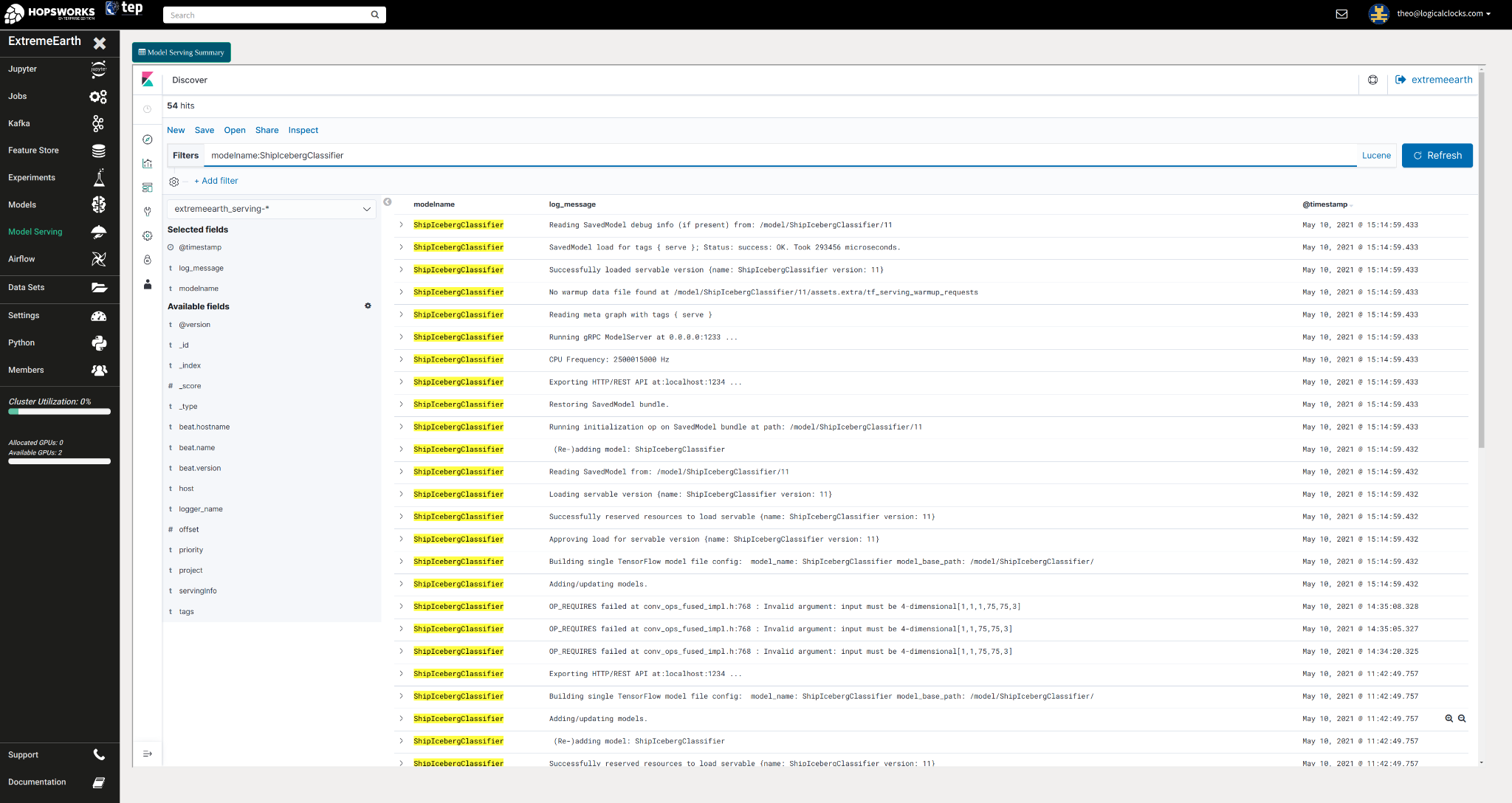
Model serving logs in Kibana
Orchestration
All previous sections have demonstrated how to apply transformations and processing steps to data via a Deep Learning pipeline, in order to go from raw data into an ML model. So far all steps had to be manually executed in a proper order to produce the output model. However, once that process is established it can then be quite repetitive in nature. That means it decreases the efficiency of data scientists whose primary focus is on improving the accuracy of the models by applying novel techniques and algorithms. Such a repetitive process should then be automated and managed easily with the help of software tools.
One such tool is Apache Airflow [9], a platform to programmatically schedule and monitor workflows. Hopsworks provides Airflow as one of the services available in a project. Users can either create an orchestration pipeline with the Hopsworks UI or implement it themselves and then upload it to Hopsworks.
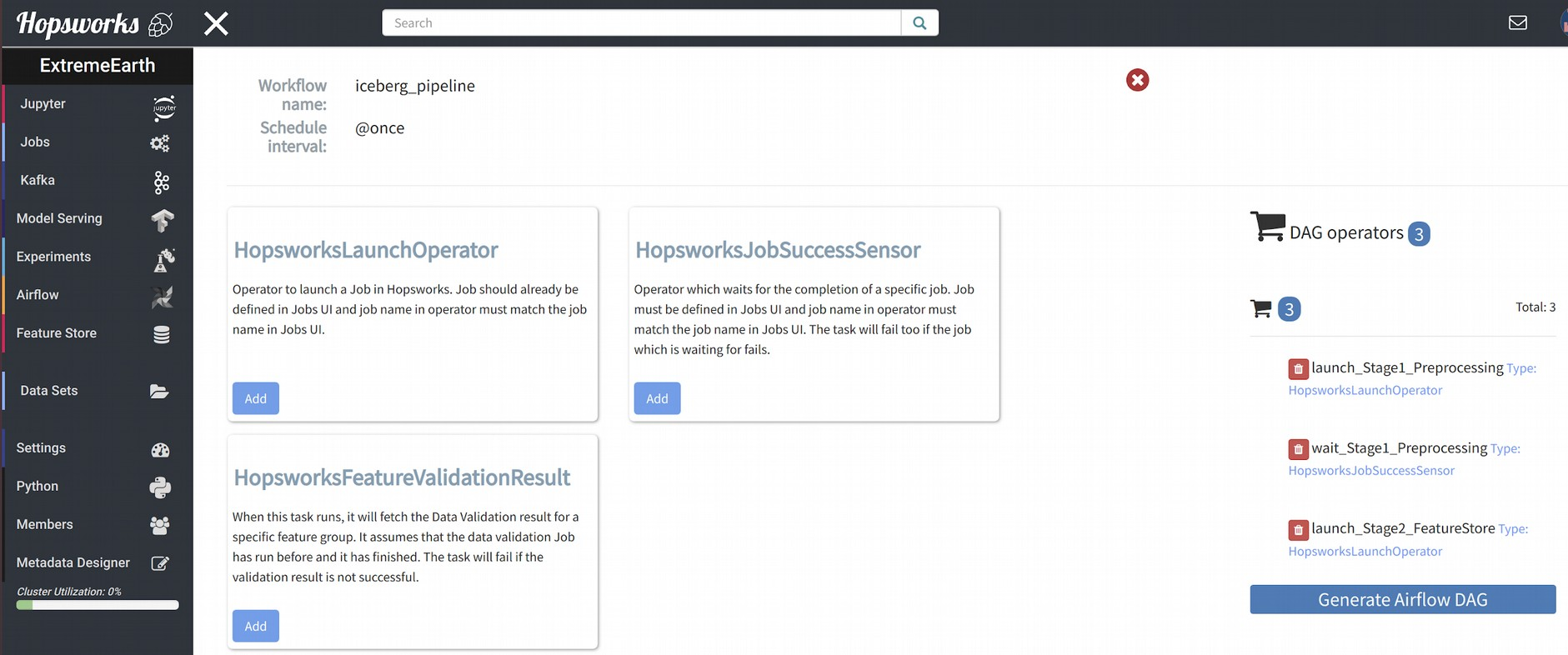
Airflow service UI in Hopsworks
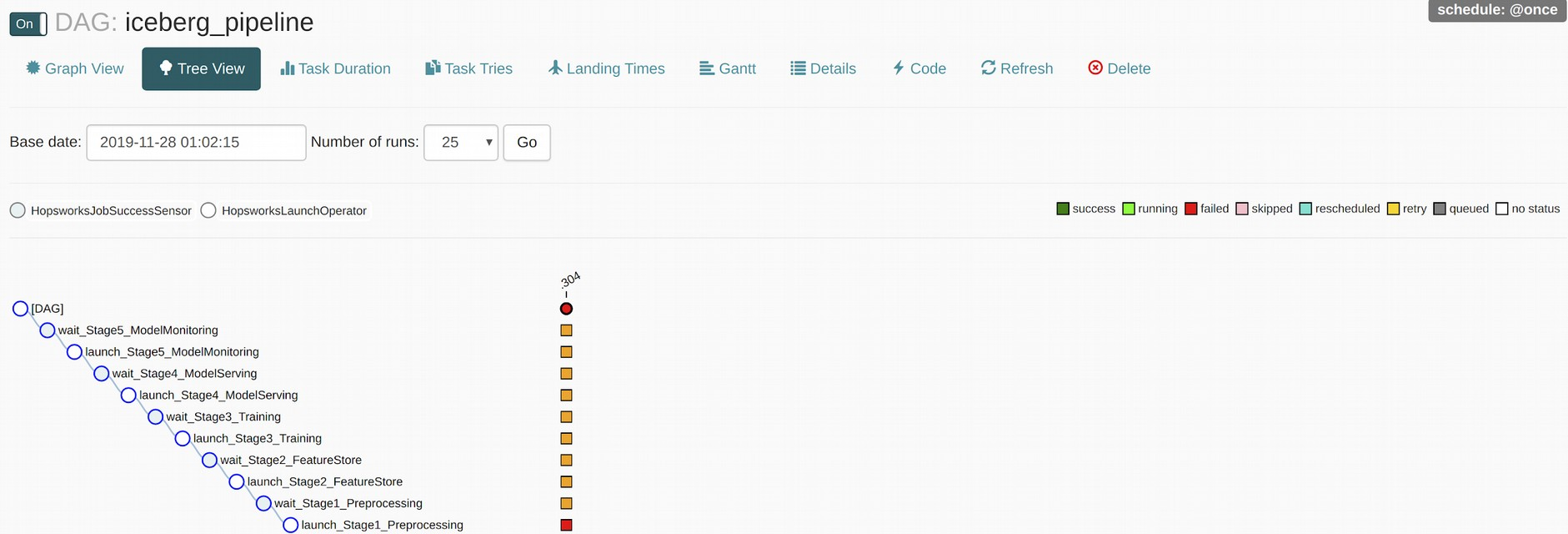
Airflow tree-view tasks for the iceberg classification pipeline
Conclusion
In this blog post we presented a real-world example of developing an end-to-end machine learning pipeline for performing iceberg classification with Earth observation (remote sensing) data. The pipeline is developed using tools and services available in Hopsworks and the example’s code is available in the ExtremeEarth project GitHub repository [10].