Automated Feature Engineering with FeatureTools
An ML model’s ability to learn and read data patterns largely depend on feature quality. With frameworks such as FeatureTools ML practitioners can automate the feature engineering process.

Introduction
Features are the data points input to a machine learning (ML) model. They are extracted from extensive datasets and contain vital information that describes the original data. In many cases, the original columns of the data might be the features as it is. However, in more complicated cases, features are engineered by passing data points via statistical algorithms.
An ML model's performance largely depends on the quality and quantity of these features. The better quality of features, the easier it is for our model to learn the data patterns. This article will discuss how ML practitioners can utilize automated feature engineering to rapidly create meaningful features and enhance the MLOps pipeline.
Why Engineer Features?
A machine learning model should be trained on a diverse set of features for it to perform well in practical scenarios. One way for diversification is to collect more data. However, data collection can be expensive and time-consuming.
Feature engineering uses aggregation techniques and data analysis to extract additional, yet vital, information from an existing dataset. This additional information helps ML models learn new patterns to achieve better performance.
Automated Feature Engineering
Deep learning automates feature engineering but requires large volumes of labeled data to work effectively. When insufficient training data is available for deep learning, explicit feature engineering can be used to create features from data sources. Feature engineering requires technical and in-depth domain knowledge for appropriate feature creation. In practical scenarios, the source data for features is often spread across various data tables and needs to be combined to create effective features. The overall process is labor-intensive and prone to errors, requiring iterative development approaches where new features are created and tested before being adopted by models.
There are, however, automated feature engineering tools to simplify the feature engineering process for tabular data. These libraries, such as FeatureTools, provide a simple API to carry out all necessary feature processing in an automated fashion. Furthermore, these libraries can be integrated into feature pipelines for production usage.
FeatureTools: Automated Feature Engineering in Python
FeatureTools is a popular open-source Python framework for automated feature engineering. It works across multiple related tables and applies various transformations for feature generation. The entire process is carried out using a technique called “Deep Feature Synthesis” (DFS) which recursively applies transformations across entity sets to generate complex features. The FeatureTools framework consists of the following components:
-
Entity Set
An entity is a data table holding information. It is the most fundamental building block of the framework. A collection of such entities is called an Entity Set. The entity sets also include additional information like schemas, metadata, and various entities' relationships. -
Feature Primitives
Primitives are the statistical functions applied to transform the data present in the entity set. The functions include aggregations, ratios, percentages, etc. Primitives may process multiple data entities to create a single value, such as sum, min, or max, or apply a transformation on entire columns to create a new feature. -
Deep Feature Synthesis (DFS)
DFS is the algorithm used by the framework for the automated extraction of features. It uses a combination of primitives and applies them to the entity sets to generate the features. The primitives are applied so that the new features result from complex operations applied across various dataset parts.
FeatureTools Implementation
FeatureTools allows users to input their datasets, create EntitySets, and use the sets for automated feature engineering. For demonstration purposes, the framework includes dummy datasets that allow users to explore its functionality.
Let's test it. First, we have to install the framework. Run the following command in the terminal.
After installation is completed, we can load the library and the relevant data in the following manner.
Let’s view the data.
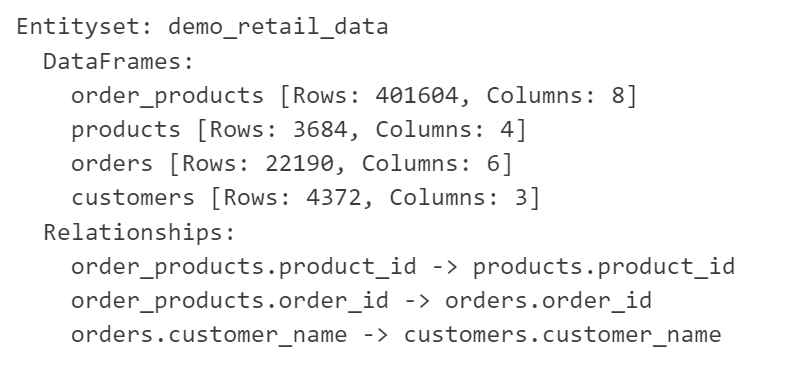
Figure 1: EntitySet: Demo retail data
We can see that EntitySet contains information about individual entities and the relationship between them. Using this, we can create features by calling a single function.
The code snippet calls the `.dfs` function from the library. The function takes the EntitySet, the main dataframe name, and the type of transformations required to build the features. Let’s take a look at what the output looks like.
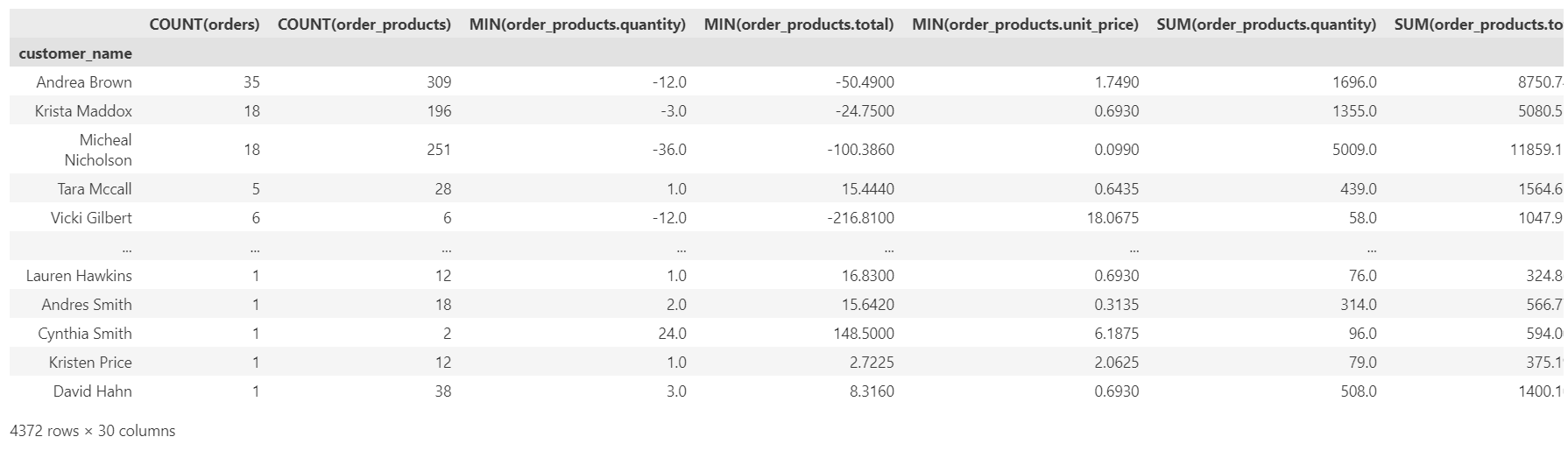
Figure 2: Feature matrix
The dataframe contains all the relevant features that can be used to train a well-performing ML model.
Custom Dataset
Ingesting multiple tables and establishing relationships is a vital part of FeatureTools. Let’s see how we can work with a custom dataset. For this exercise, we will use the Home Credit Default Risk dataset.
The dataset consists of 8 key tables, each related to the other via a common field. Our first step is to load these datasets into memory.
We have separate training and testing datasets for the application data. We need to combine it first.
Next, we need to perform some data analysis. It is important to note that several processing techniques can be used in the dataset, such as asserting data types or data imputation, but that is beyond the scope of this article. We will only assess the dataset for NaN values.
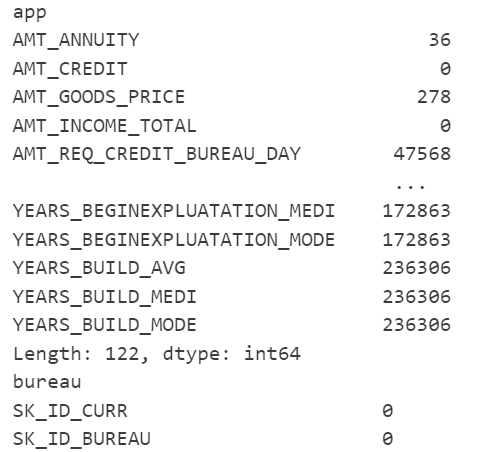
Figure 3: Columns with NaN values
There are several columns that contain NaN values. For this demonstration, we will fill them with zeros.
Now let’s drop some columns that will not be used.
Finally, we create the EntitySet using the data loaded from the CSV files.
Note above that, to be part of an EntitySet; every table must have a column as a unique identifier. Our `app,` `bureau,` and `previous` data frames already have these columns, but for the rest, we set the `make_index` flag to True so FeatureTools creates an identifier itself.
Figure 4: EntitySet
All our data is loaded into a single EntitySet, but no relationships are still established. FeatureTools needs information regarding relationships between the tables. All the tables in our dataset are linked to one another via column fields. Now we need to create these relationships within the FeatureTools EntitySet.
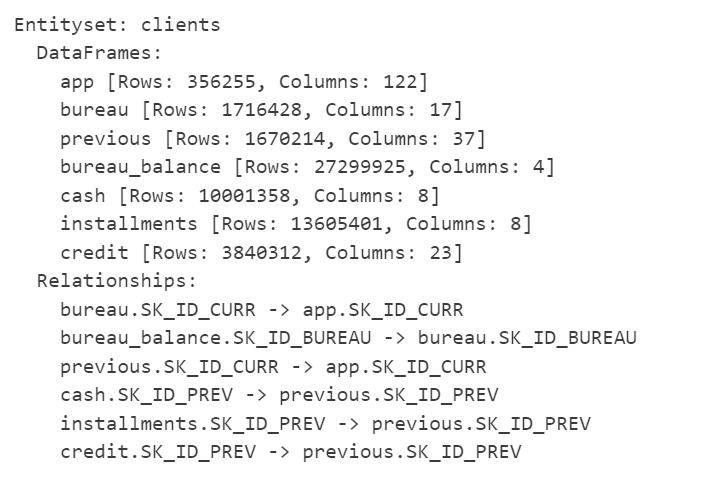
Figure 5: EntitySet after creating relationships
The EntitySet contains all relevant entities and relationships. The set is ready for creating features using deep feature synthesis. We can use the same code as our previous example.
Figure 6: Engineered Features
And just like that, within a few seconds, we were able to generate several features that can be used for model training. The extracted features can be stored in a feature store.
Storing Features
Feature stores are a convenient way of storing calculated features. Whether using automated methods or manual calculations, the feature vectors need to be stored in a secure location for later use.
Hopsworks For Feature Storage
We can store the features we generated earlier in the Hopsworks feature store in a few lines of code. First we install the library.
Once the installation is successful, we can proceed to creating the feature store and saving our dataframe.
Summary
Engineering features is a tiresome process which is why many engineers opt for automated feature engineering. They use frameworks like FeatureTools to engineer new features within seconds. The framework treats datasets as EntitySets and uses the Deep Feature Synthesis technique for feature processing. DFS works across various related data tables and applies primitives like average, sum, count, etc., to create new features.
The engineered features are finally stored in a feature store. The feature store is a centralized storage for features from various business domains. It is an access point for ML engineers who use these for model training and enable effective team communication.