What is Distributed File Systems (DFS) and why you need it for Deep Learning
Why HopsFS is a great choice as a distributed file system (DFS) in a time when DFS is becoming increasingly indispensable as a central store for training data, logs, model serving, and checkpoints.

What is DFS?
As the name suggests, Distributed File System (DFS) is a file system that is distributed across multiple platforms or locations. Using this technology, applications can access or store isolated files just like local files, allowing programmers to access files from any network or computer. The primary function of the Distributed File System (DFS) is to enable users of physically distributed systems to share resources and data. Distributed File System (DFS) has two components: Location transparency (using the namespace component) and Redundancy (using the file replication component). By allowing shares in several locations to be logically grouped under one folder, these components provide data availability in the event of failures or heavy loads.
Prediction Performance Improves Predictably with Dataset Size
Baidu showed that the improvement in prediction accuracy (or reduction in generalization error) for deep learning models was predictable based on the amount of training data. The decrease in generalization error with increasing training dataset size follows a power-law distribution(as seen by the straight lines in the log-log graph below). This astonishing result came from a large-scale study in the different application domains of machine translation, language modeling, image classification, and speech recognition. Given that this result holds true in vastly different application domains, there is a good chance the same result holds true for your particular application domain. This result is important for companies considering investing in distributed file systems (DFS) for deep learning - if it costs $X to collect or generate a new GB of high quality training data, you can predict the improvement of prediction accuracy for your model, given the slope, Y, of the log-log graph you have observed while training.
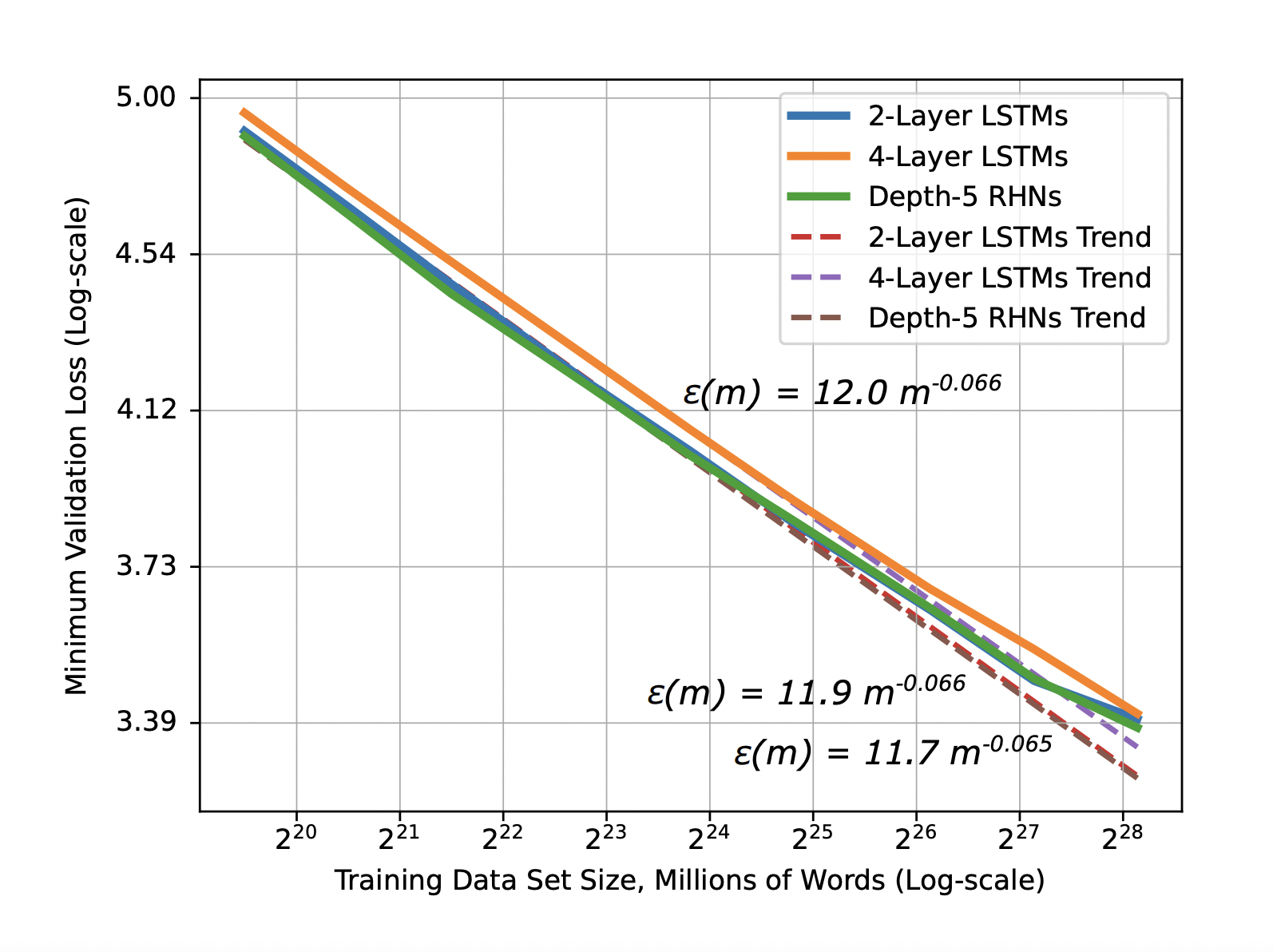
Figure 1. Learning curve and model size results and trends for word language models - Baidu Research
Predictable ROI in the Power-Law Region
This predictable return-on-investment (ROI) for collecting/generating more training data is slightly more complex than the one described above. You first need to collect enough training data to get beyond the “Small Data Region” in the diagram below. That is, you can only make predictions if you have enough data that you are in the “Power-Law Region”.
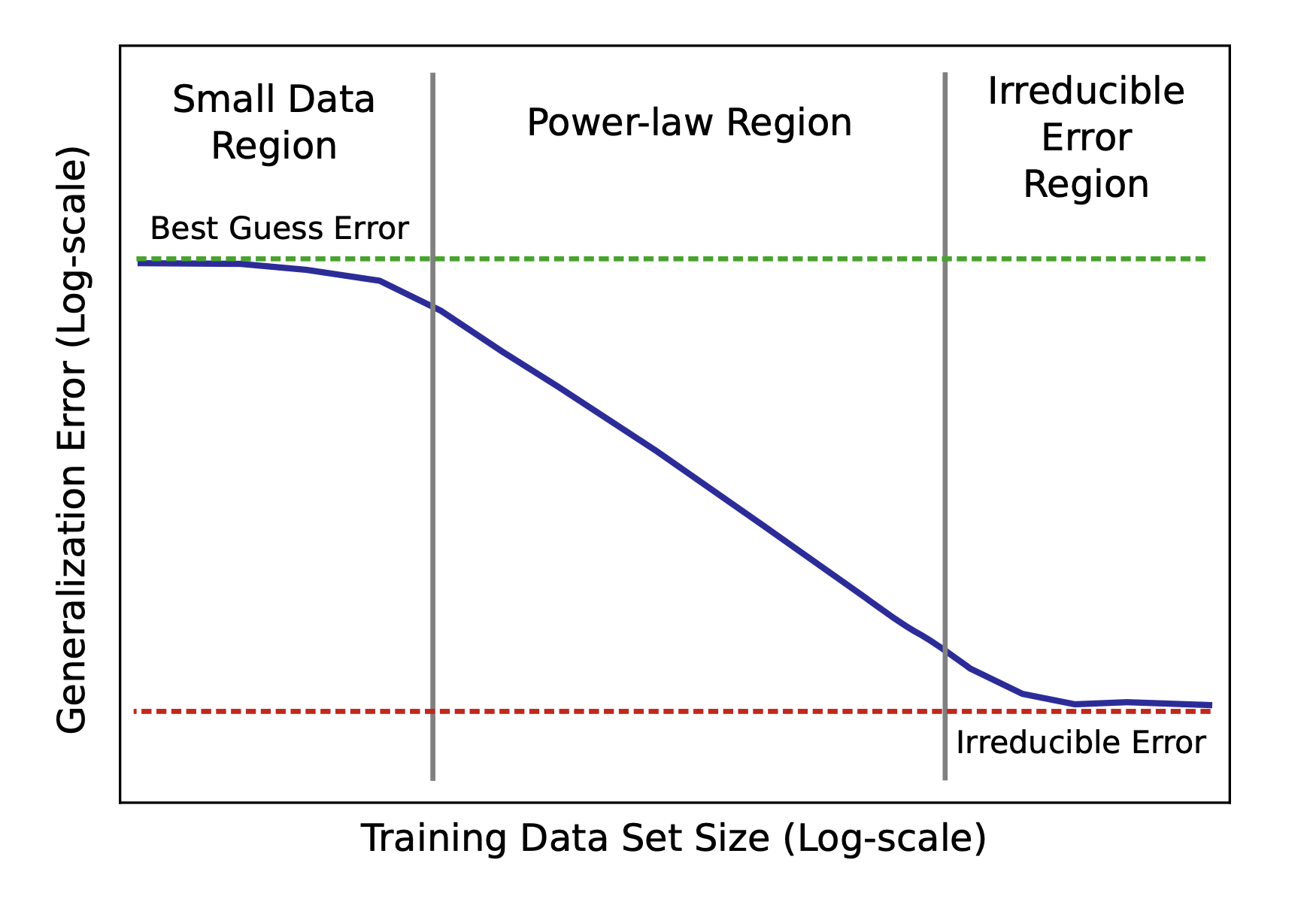
Figure 2. Sketch of power-law learning curves - Baidu Research
You can determine this by graphing the reduction in your generalization error as a function of your training data size on a log-log scale. After you start observing the straight line on your model, calculate the exponent of your power-law graph (the slope of the graph). Baidu’s empirically-collected learning curves showed exponents in the range [-0.35, -0.07] - suggesting models learn real-world data more slowly than suggested by theory (theoretical models indicate the power-law exponent is expected to be -0.5).
Still, if you observe the power-law region, increasing your training data set size will give you a predictable decrease in generalization error. For example, if you are training an image classifier for a self-driving vehicle, the number of hours your cars have driven autonomously determines your training data size. So, going from 2m hours to 6m hours of autonomous driving should reduce errors in your image classifier by a predictable amount. This is important in giving businesses a level of certainty in the improvements they can expect when making large investments in new data collection or generation.
Need for a Distributed Filesystem (DFS)
The TensorFlow team say a distributed filesystem is a must for deep learning. Datasets are getting larger, worker GPUs need to coordinate for model checkpointing, worker GPUs need to coordinate for hyperparameter optimization, and/or model-architecture search. Your system may grow beyond a single server, or you may have different servers for serving your models from the servers you have for training your models. A distributed file system (DFS) is the glue that holds together the different stages of your machine learning workflows, and it enables teams to share GPU hardware. What is important is that the distributed file system (DFS) works with your choice of programming language and deep learning framework(s).
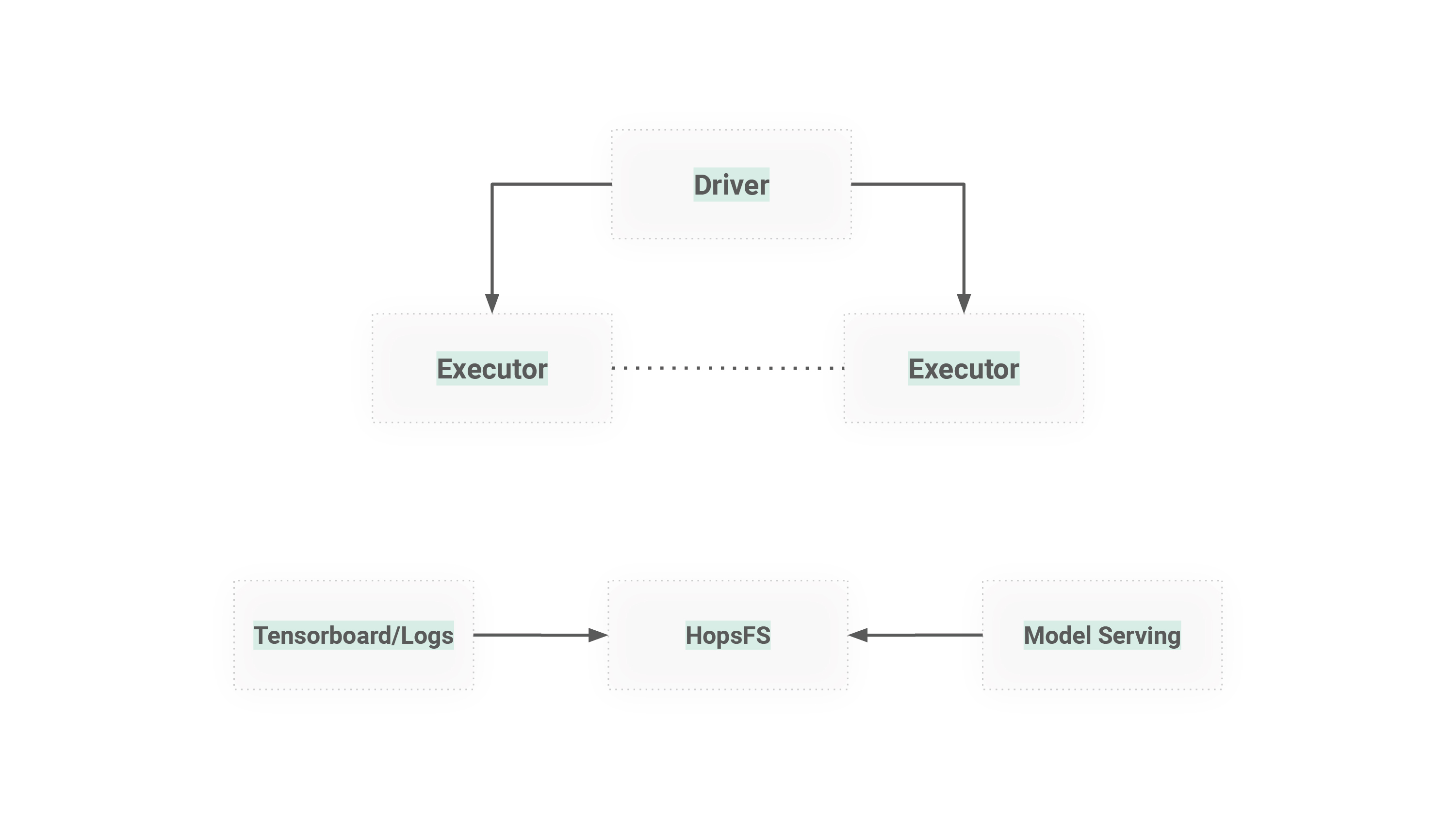
Figure 3. A distributed file system (DFS) is needed for managing logs, tensorboard, coordinating GPUs for experiments, storing checkpoints during training, and storing/serving models.
HopsFS is a great choice as a distributed file system (DFS), due to it being a drop-in replacement for HDFS. HopsFS/HDFS are supported in major Python frameworks: Pandas, PySpark DataFrames, TensorFlow Data, and so on. In Hops, we provide built-in HopsFS/HDFS support with the pydoop library. HopsFS has one additional feature that is aimed at machine learning workloads: improved throughput and lower latency reading/writing for small files. In a peer reviewed paper at Middleware 2018, we showed throughput improvements of up to 66X compared to HDFS for small files.
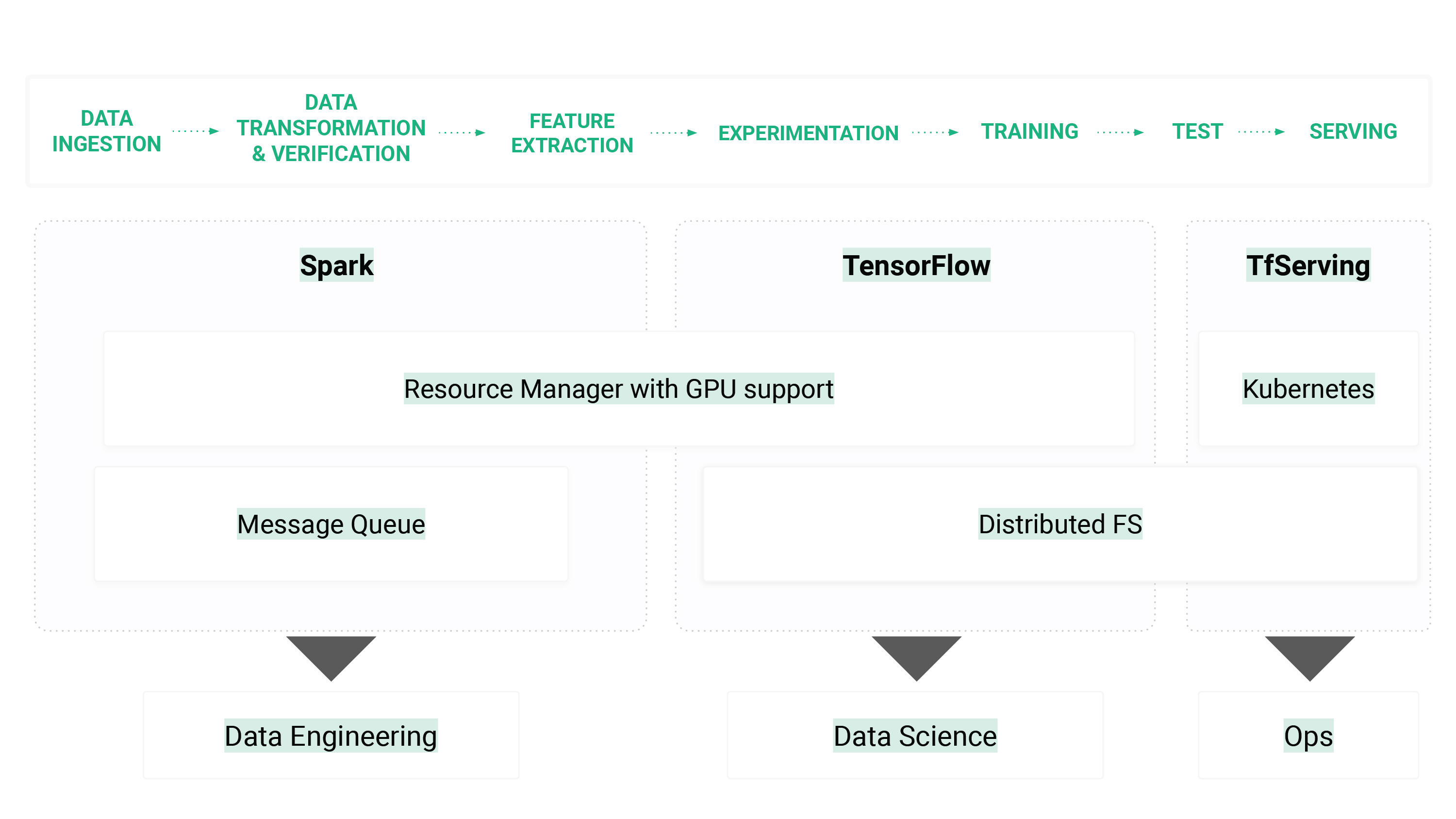
Figure 4. HopsFS Additional Features
Python Support in Distributed File Systems (DFS)
As we can see from the table below, the choice of distributed file system will affect what you can do.
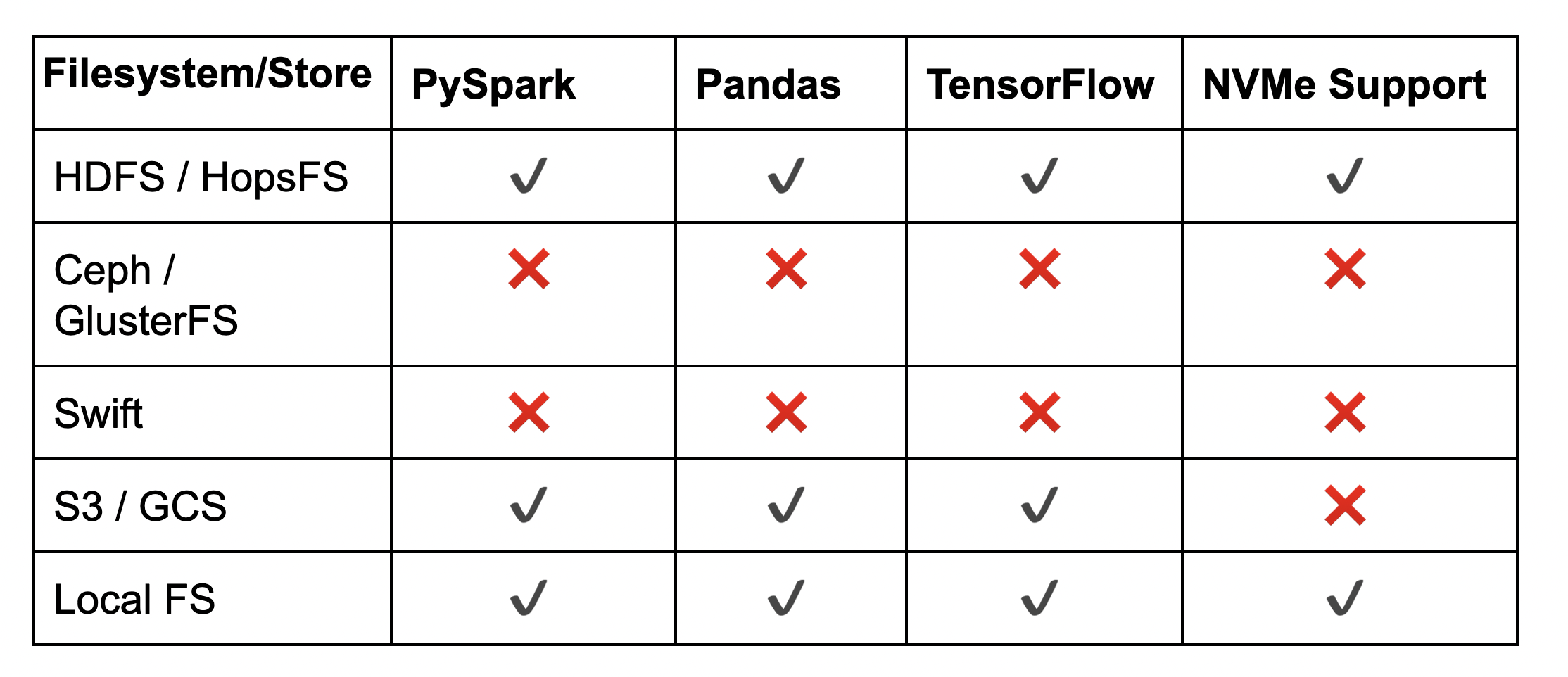
Figure 5. Python Support in Distributed File Systems (DFS)
Python Support in HopsFS
We now give some simple examples of how to write Python code to use datasets in HopsFS. Complete and up to date notebooks can be found on our examples repository in github
Pandas with HopsFS

In Pandas, the only change we need to make to our code, compared to a local filesystem, is to replace open_file(..) with h.open_file(..), where h is a file handle to HDFS/HopsFS.
PySpark with HopsFS

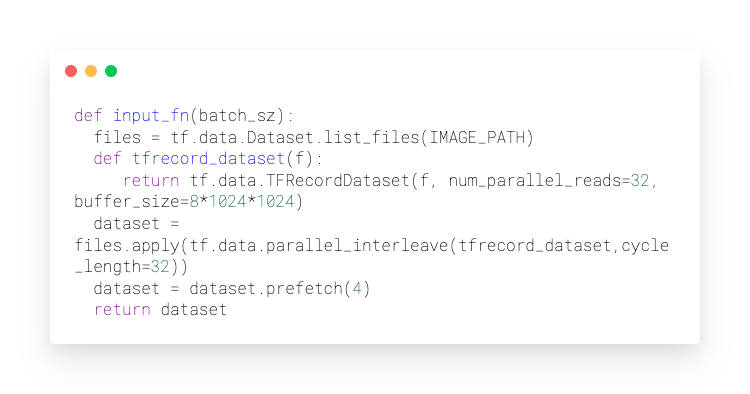
TensorFlow Datasets with HopsFS