Build Your Own Private PDF Search Tool
Using both RAG and Fine-Tuning in one Platform
A summary from our LLM Makerspace event where we built our own PDF Search Tool using RAG and fine-tuning in one platform. Follow along the journey to build a LLM application from scratch.

This is a transcripted summary from our LLM Makerspace event where we built our own PDF Search Tool using RAG and fine-tuning in one platform. Follow along the journey to build a Large Language Model (LLM) application from scratch. This isn't just any application; our goal is to index private PDFs, creating a searchable database for you - think of having your version of pdf.ai, but with a twist.
Why Build an LLM Application and Who Should Care?
If you've dealt with private PDFs, you know the struggle. Uploading to services like pdf.ai could clash with compliance requirements, leaving you in a dilemma. Our solution? An open-source path you control. This is for anyone who wants an inside view of building LLM applications or has a specific need for privacy in their document handling.
Diving into Vector Databases and Embeddings
Sometimes, to innovate, we need to deviate from the norm. While vector databases like Pinecone are fantastic for vector embeddings, we'll take a different route using Hopsworks Feature Store. Ever chopped a PDF into sentences or paragraphs? That's exactly what we'll do, then we'll create 'embeddings' - think of them as digital fingerprints of text to search for similarities later.
Enhancing with Hopsworks Feature Store
Forget the norm. Instead of a typical vector database, Hopsworks 3.7 now supports Proximity's nearest neighbor search and ANN index - meaning our embeddings will be searchable. And It's all done within the comfort of pandas DataFrames.
Instructions Dataset and the RAG Aspects
What's even cooler is creating an instruction dataset. We give existing models like GPT-4 chunks of our PDFs and ask them to generate Q&A pairs. This gives us training data for fine-tuning, ensuring consistent and structured responses - scale this, and you have a highly sophisticated LLM application at hand.
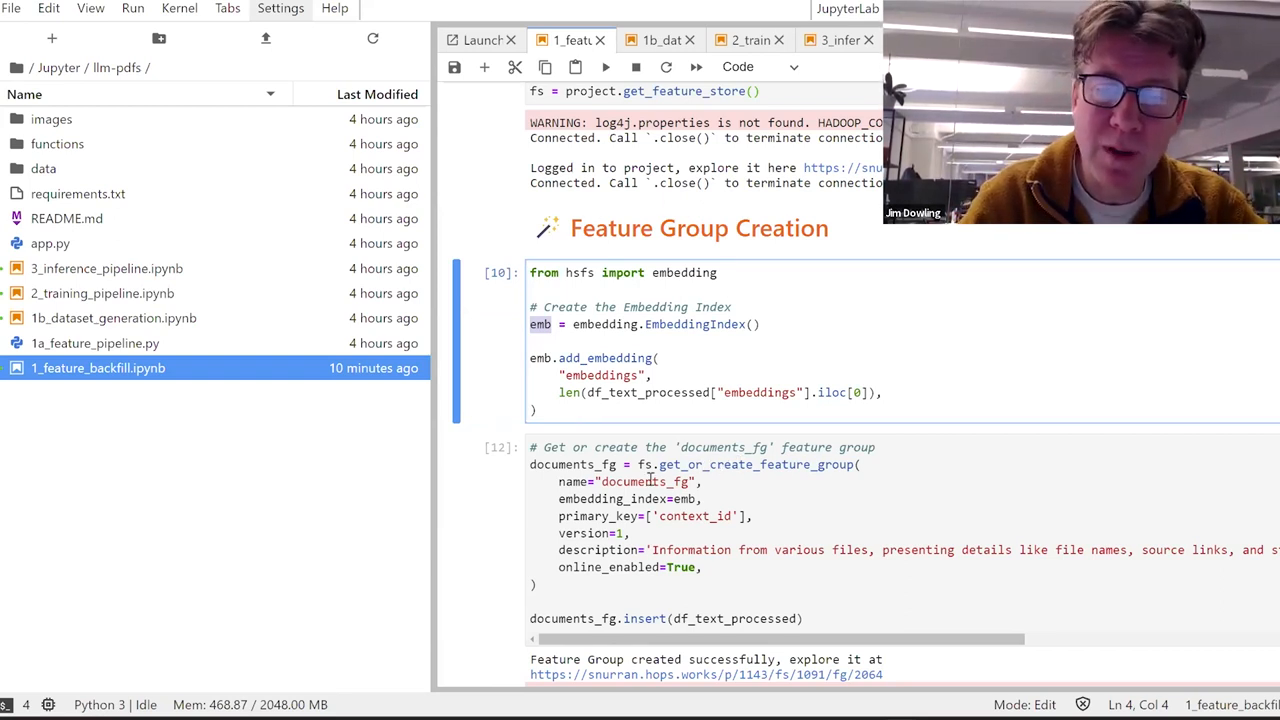
The Project: Inspired and Functional
Inspiration can come from anywhere, and for me, it was teaching at KTH, where two students indexed my lectures. Today, we take those lessons to build a comprehensive system - modularity is our mantra here. Transforming large PDF collections into searchable, enriching data ready for LLM integration, this code is not just code; it's a blueprint for autonomy in data handling.
Setting it in Motion: The Feature Pipeline
The process kicks off with a feature pipeline, coded in Python, that regularly checks for new PDFs in your Google Drive, extracts text, computes embeddings, and uploads ever-fresh data to Hopsworks. This seamless updating guarantees your application stays current, always ready with the latest info.
Going Beyond: Fine-Tuning Mistral
Arriving at fine-tuning, we use Mistral, a reliable open-source LLM. With the 7 billion parameter model, we've streamlined it, shrinking its size without compromising its prowess. By feeding it our instruction dataset, we personalize responses, creating an application that's not just intelligent but resonant with our distinct needs.
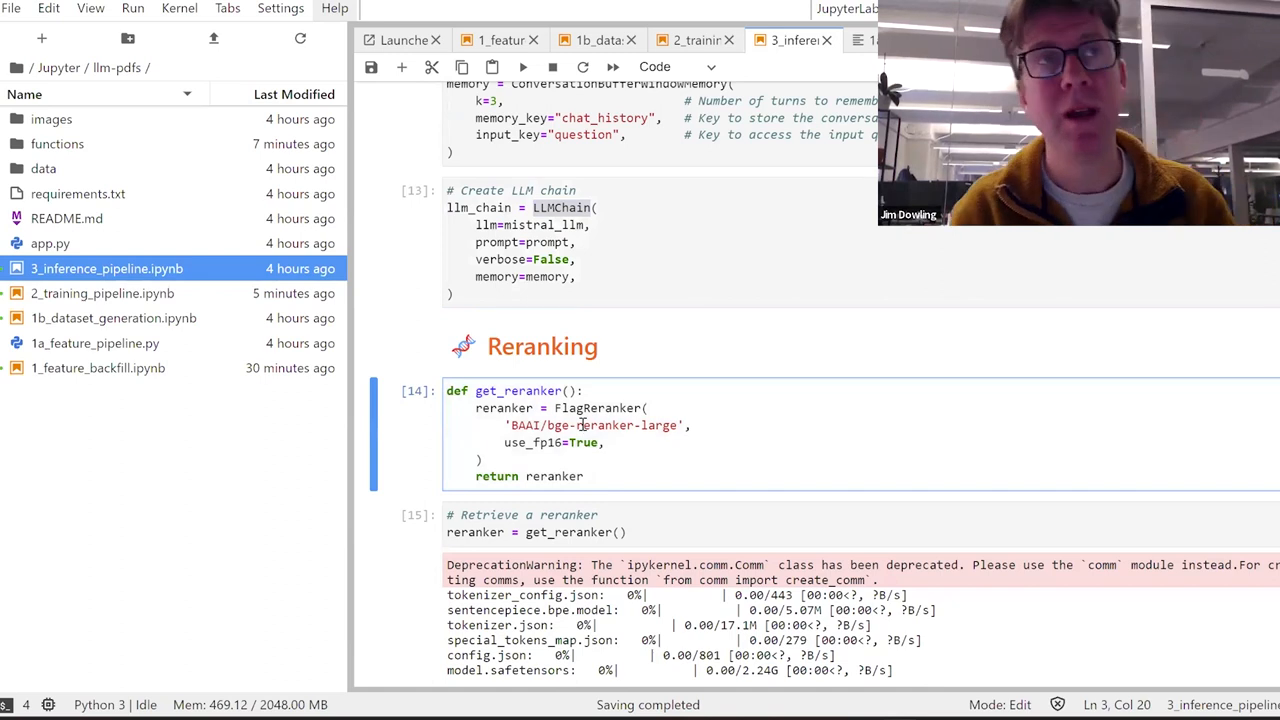
The Inference Pipeline and Insights
Once trained, we need to ensure the model's predictions are accurate. That's where the inference pipeline comes in, integrating our fine-tuned model with a feature store to fetch the nearest neighbor documents based on queries, lending precision to the answers the system generates.
The Power of Response Logging
Never underestimate data. Response logging is the step that completes our circle. Recording queries and their responses equips us with rich data to evaluate and refine the LLM - this granularity paves the path for an application that evolves, becoming more potent with every interaction.
Closing thoughts
And if you're itching to try it out, the entire code is available on the Logical Clocks GitHub. Roll up your sleeves, because with Hopsworks, either self-hosted or the upcoming serverless version at run.hopsworks.ai, you're in for a technology dive that promises both deep understanding and powerful results.
As we wrap up this deep dive into building your very own searchable PDF index with LLM, remember, this is much more than a technical exercise. It's a statement about control, privacy, and the incredible potential when open-source meets inspired application. Whether for compliance, curiosity, or both, the stage is set for you to take this knowledge and march towards a future written by you - in searchable PDFs and beyond.
Watch the full episode of LLM Makerspace: