Hopsworks 3.0: The Python-Centric Feature Store
Hopsworks is the first feature store to extend its support from the traditional Big Data platforms to the Pandas-sized data realm, where Python reigns supreme. A new Python API is also provided.

Introduction
Feature stores began in the world of Big Data, with Spark being the feature engineering platform for Michelangelo (the first feature store) and Hopsworks (the first open-source feature store). Nowadays, the modern data stack has assumed the role of Spark for feature stores - feature engineering code can be written that seamlessly scales to large data volumes in Snowflake, BigQuery, or Redshift. However, Python developers know that feature engineering is so much more than the aggregations and data validation you can do in SQL and DBT. Dimensionality reduction, whether using PCA or Embeddings, and transformations are fundamental steps in feature engineering that are not available in SQL, even with UDFs (user-defined functions), today.
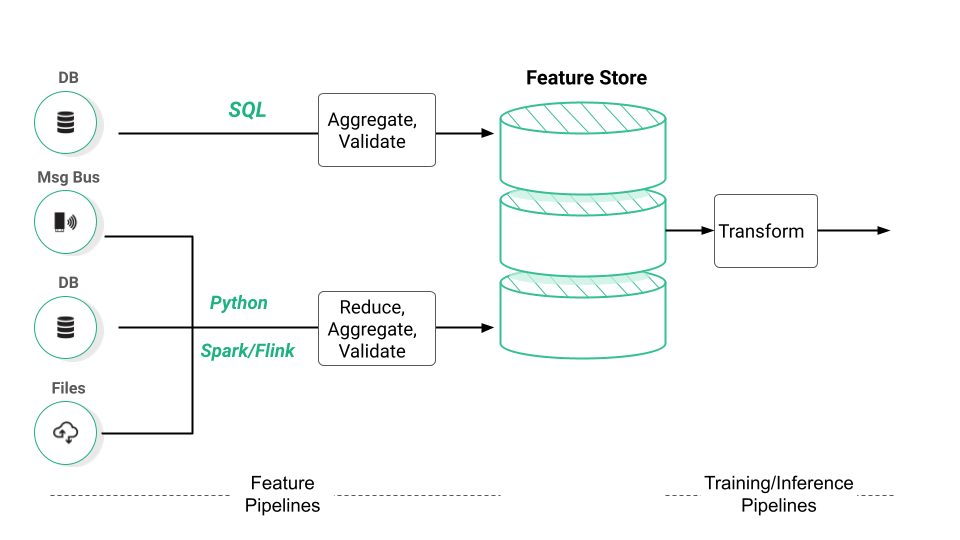
Figure 1. Modern Data Stack
Over the last few years, we have had an increasing number of customers who prefer working with Python for feature engineering. Typical feature pipelines and training pipelines use frameworks such as:
- Pandas to compute aggregations,
- Scikit-Learn, PyTorch, and TensorFlow to transform features and perform dimensionality reductions,
- and Great Expectations to validate their feature data.
Hopsworks supported Python and Pandas for these tasks, but there were gaps between the prototype in Python and final production pipelines.
What’s new?
In Hopsworks 3.0, we have removed any gaps between Python pipelines and production, tightening the development feedback loop for writing both feature pipelines and training pipelines. You can run your feature pipeline in any Python environment, and materialize your features faster and in the background, enabling more interactive development. Your features will be available in the online feature store in seconds, enabling you to quickly inspect your features and move on to your next task quicker. You can validate your feature data with Great Expectations. We have introduced a new abstraction to read features - a Feature View that provides a consistent, logical view of the features used by a model for both training and inference, including any transformation functions applied to features. You can now retrieve training data directly as Pandas DataFrames, split into train/test/validation sets. We even now have a serverless version of Hopsworks, which means you only need to pip install our library and register for an account to read/write directly from your private feature store. Hopsworks serverless has a free forever tier, enabling you to build your features in confidence today, knowing they will be there in the future.
Use your Python Environment of Choice
You can write your feature pipelines, training or inference pipelines in any Python environment using our Python SDK. You can orchestrate your pipelines using your orchestration engine of choice: Airflow, Github Actions, Dagster, Azure Data Factory, MetaFlow, Kubeflow Pipelines, and more. Hopsworks also provides bundled Airflow for your convenience.
Write to Feature Groups, Read from Feature Views
In Hopsworks, the end result of a feature pipeline is a Pandas DataFrame that you insert into a Feature Group. A Feature Group is a table, containing all the Pandas DataFrames written to it over time. When you write to a Feature Group, the rows in your Pandas DataFrame are appended to the Feature Group. Rows in your Feature Group can also be updated or deleted. Feature pipelines write to the mutable Feature Groups, and from there, the features can be reused across many different models by creating a Feature View to read the training or inference data for your model. Built-in or custom transformation functions (user-defined functions in Python) can be attached to a feature view to enable untransformed data to be stored in the Feature Store, important for reusability of features, EDA, and consistent transformations to be applied across training and inference data read from a Feature View. The training data created from a Feature View is immutable - a reproducible snapshot of the features you selected that includes a time range and any filters you apply (such as limiting to specific geographic region). Feature Groups, Feature Views and Training data are all versioned and their lineage is tracked, enabling A/B testing of features and one-click recreation of training data.
Data Validation with Great Expectations
Hopsworks now supports Great Expectations for feature pipelines and feature logging. You can define your data validation rules in Great Expectations, and data validation results will be stored in your Feature Group in Hopsworks, from where you can browse the history of data validation runs. You can also write alerts in Hopsworks, notifying team members in Slack, email, or pager duty, of problems with data quality.
MLOps Support
DevOps emerged as a set of software engineering practices that tighten the deployment time between development and operations by providing structured methods for testing, versioning, communication, and collaboration. Similarly, MLOps enables incremental changes to your feature, training, and inference pipelines, and your pipelines are continuously built, tested, and deployed to production. MLOps requires versioned assets - features and models - to automate Continuous Integration pipelines that run unit/pipeline tests for any changes, build the software artifacts, and ensure the correctness of the data validation tests. Continuous deployment ensures that pipelines are deployed to production in stages (dev, staging, prod) with fast failure and rollback to working versions. Hopsworks enables complete feature pipelines and training pipelines to be tested and run locally before being deployed to staging and production environments.
Hopsworks also enables A/B testing of features. Just as you can deploy a new model to improve your prediction performance, you can also deploy new features to improve your prediction performance. This is commonly known as data-centric AI. Hopsworks supports A/B testing of features through comprehensive versioning support for schemas and data. From raw data to model inputs, Hopsworks manages versioned schemas of Feature Groups, and Feature Views - the inputs to models. Writes to Feature Groups are also versioned, enabling the reproduction of training data and the provenance of data used to train models.
Hopsworks 3.0; also serverless
If you want to write prediction services, not just train models, Hopsworks serverless is a great option. It is the easiest way to manage your features for training and inference, and even store and serve your models from Hopsworks serverless. It runs on the network, you just create an account, and you use it. Hopsworks Serverless offers many advantages:
- Start in seconds - immediate productivity;
- No Operation/Installation/Upgrading;
- Always Available - use your features and models anytime, from anywhere;
- Seamless Scalability;
- Cost Efficiency.
However, Hopsworks Serverless may not be the perfect fit for everyone. Firstly, data ownership might be a requirement for you, and you may have high performance or resource requirements. You may love development and compute on Hopsworks. In any of these cases, you can use Hopsworks in your own cloud account, managed by Hopsworks.ai. All data and services run in your account, but you auto-scale your cluster, or press a button to upgrade, backup your cluster, or stop or start your cluster. If you are not yet in the cloud, you can also deploy Hopsworks on your own data center, even in secure air-gapped environments.