Agents Are the New Product's Interface
Or you just don't have a product
For thirty years software competed on surfaces: UIs, CLIs, SDKs, APIs built for humans. Agents change that. Increasingly the user does not learn the surface, the agent does, and the platform that wins is the one that puts the least friction between the agent and the work.

Summer 2024, during a VC event in central Stockholm, I briefly ran into Anton Osika, founder of Lovable, I think it was still called GPT Engineer at the time. He told me what he was building, and I had two immediate thoughts. The first: "why didn't I think of it." The second: "how does this even survive?" And in my arrogant French way, I probably hinted at the second one.
I was wrong, evidently.
But there was no doubt that a coding agent could prompt a working website into existence. And so the next logical question was: could the same thing be coming for Machine Learning? Can someone with minimal data engineering or data science background prompt a full system into life?
I think the answer is yes. For thirty years software companies competed on surfaces: UIs, CLIs, SDKs, SQL dialects and APIs designed for humans. Agents change that. Increasingly, users don't learn the surface. The agent does. The platform is judged by how easily an agent can operate it.
So the winning platform may simply be the one that creates the least friction for the agent.
Slop Used to be Called MVP
If we go back in time long enough that the LLMs were not in the room with us, a flaky prototype that was sort of working and could be iterated on was called a Minimum Viable Product. The general idea being that one could iterate over parts of the prototype to improve it over time, but that the prototype would be able to showcase the value much faster, to justify that investment in time or money or both.
Today, those prototypes can be called slop, because they are generated at least in part, if not entirely, by LLMs. There is an understandable reason as to why it is considered slop: if anyone comes to the office and shows you some Claude-coded engineering thing as if it is the finished product, you are not going to be kind. And rarely do those prototypes get to the level of "ship it now".
But the label is noise around the reality that today, we can produce prototypes and improve them well enough that they do become shippable. Anyone pretending otherwise is not keeping up.
The argument worth having is not how we call the MVPs, but rather how we build and make them better.
What Makes Everything so Trivial to Build?
Building has become so easy, clearly because of the coding agents and their harnesses, and there is simply no legacy data platform at the moment that has successfully built its own harness. Nor would you be wise to bet on one if they had, since that locks you to a single vendor's tooling while the current best-in-class reshuffles every few weeks. The reality is that much of the working hours of an engineer, an analyst or a data scientist are going to be spent in Claude Code, Codex or similar.
That's the thesis: the work moves into the agent, the agent talks to the platform directly, and the platform underneath turns into something the user never touches directly.
The direct impact on the industry is visible in the recent announcements. Snowflake has Coco, a "data-native AI coding agent", effectively their own harness, plus Coco in Snowsight as a conversational analytics UI. Databricks has its own meta-harness, and Genie for the same conversational layer.
That Databricks Omnigent meta-harness is worth noting in that context: an amazing exercise in developer relations that has no real relation to their own products. Open-sourcing a tool that explicitly does not require your platform suggests that the center of gravity is moving toward the agents.
If the platform becomes something users rarely touch directly, with the agent sitting between them and the backend, then companies like Snowflake and Databricks need to remind you they exist as hard as possible, as often as possible. These are perfectly reasonable considerations if you own the platform underneath and need to capture the economics of the current gold rush, but there are multiple ways to go about it.
Two Emerging Strategies
1. Build tooling that sits on top of the data layer. Coco (Snowflake) and Genie (Databricks) keep the agentic experience inside the vendor's walls. It is a perfectly legitimate business strategy, but it ties your agent layer to one vendor's bet on which model and which harness wins. They are hardcoding the tooling into the platform, for you.
2. Stay as the data layer. Here is the bet we are making at Hopsworks: we did not build an abstraction of agents around the infrastructure. We built infrastructure for the agents.
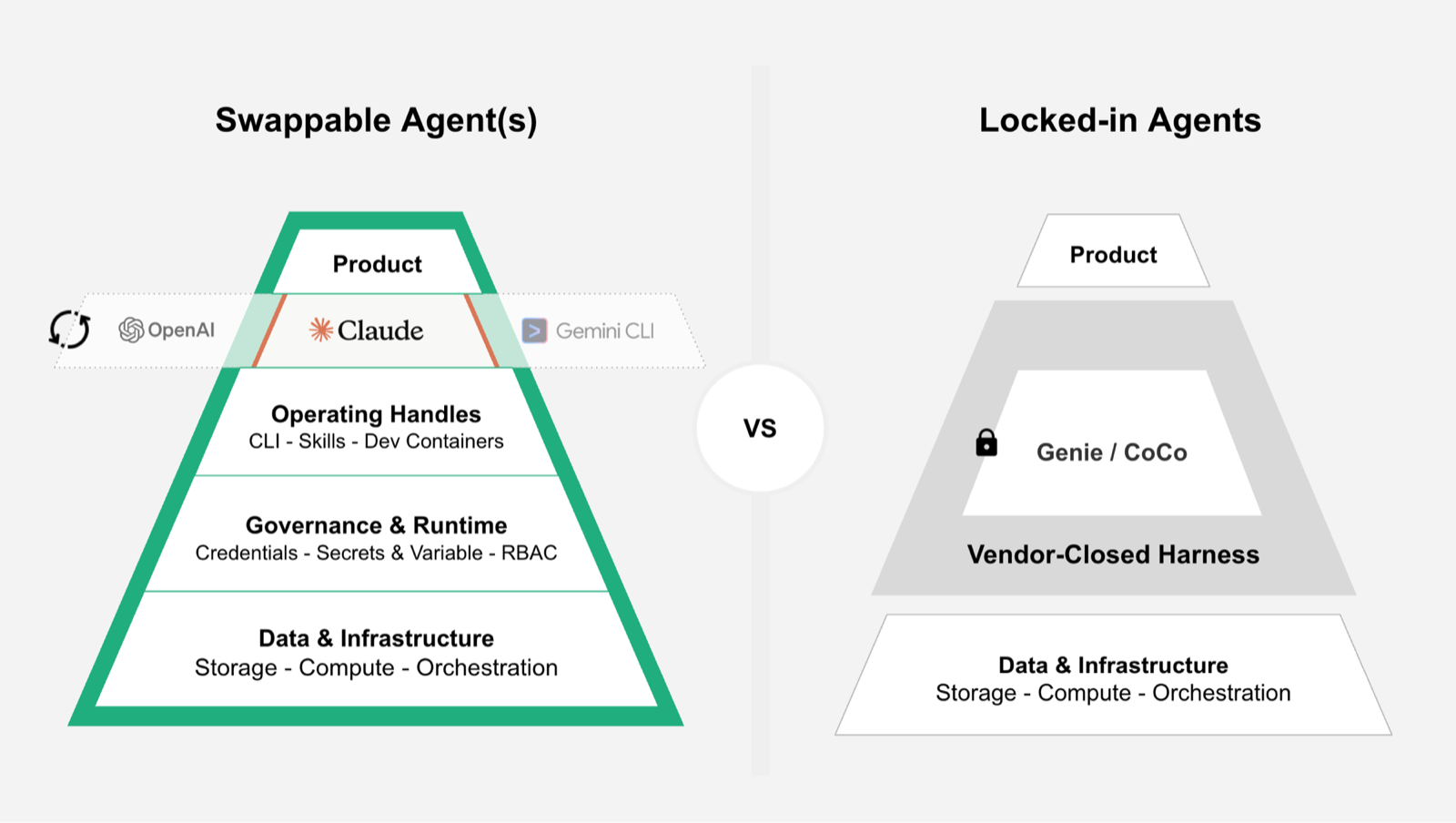
Figure 1. Two bets: a swappable agent layer on top of an open data and infrastructure platform, versus a vendor-closed harness wedged between the product and the data layer.
That is the whole strategy in two sentences. Not harnesses to compete with Claude Code or Codex. We spent the time making the platform the instrument any of those tools can pick up, with as little friction as possible: the path of least resistance, not a wall. We extended the platform to be operated by any agent, and built the interfaces around that. Switch from Claude to Codex tomorrow, and nothing underneath changes. The platform does not care what tool you are holding.
Boring, and That's OK
We believe in the boring parts. Hopsworks is a data management platform: storage and management of the data, of the artifacts and metadata, and the compute and orchestration to train and serve models. These are the boring parts of any ML system, and also the parts ultimately no one can work without. An organisation has two options: build it or buy it.
But the upside is, if you give any agent the data management layer, it can do the actual work: turn raw tables into features, train and deploy a model, schedule and maintain the whole thing. Build the system, build a UI on top, embed the model in it.
So Where's the Theory in Practice?
"Built infrastructure for the agents" is a neat tagline. The version we shipped is in Hopsworks 5.0; it comes with a browser-based terminal that mounts agent credentials straight from our filesystem, headless agent workflows that run as ordinary jobs against whichever provider you pick, and a CLI with skills so any agent you bring can operate the Feature Store and the rest of the platform. Check our release notes, we'd love more eyeballs on the new version.
Show, Don't Tell
So beyond the essay: what does it look like, today? Well, you can build a fully functional AI system MVP in an hour, for free. Nobody could say that a couple of years ago.
Last week we ran a live session with minimal prep and walked out with two similarly sloppy but real World Cup prediction services.
We will be running bi-weekly live coding sessions, building things with the audience: no slideware, no solution architect pushing the new thing down your throat. A simple, honest-when-it-breaks stream.
But reading about it is the least interesting option.
Hopsworks 5.0 is live, the SaaS tier is free, and the Terminal is sitting there waiting for an agent. Bring your own, Claude, Codex, whatever you are holding, and see how far you get in an hour. Or join the next live session and watch us find the bugs in real time.
Either way: start breaking things.