Unifying Single-host and Distributed Machine Learning with Maggy
Try out Maggy for hyperparameter optimization or ablation studies now on Hopsworks.ai to access a new way of writing machine learning applications.

This blog covers the oblivious training function and the internals of Maggy presented at Spark+AI Summit 2020, on June 26th.
Most of the publicly available ML source code for training models is not built to scale-out on many servers or GPUs. Getting started with deep learning is relatively easy these days, thanks to fast.ai, GitHub, and the blogosphere. The hard part for practitioners starts when the code examples found online need to be applied to more challenging domains, with larger and custom datasets, which in turn will require a bigger customized version of the model to fit that dataset. Using publicly available code as a starting point for model development on clusters, you will end up in a process similar to the one depicted in Figure 1.
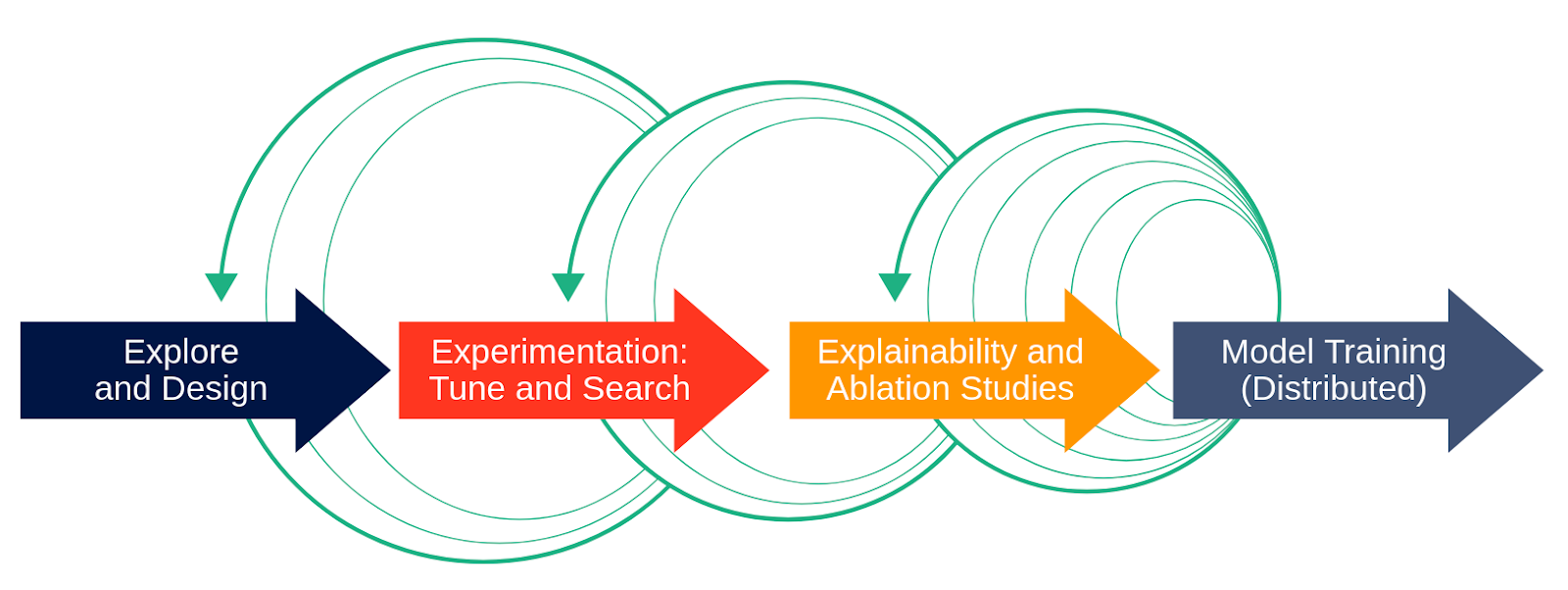
Figure 1: A simplified view of the ML model development process, illustrating its iterative nature.
The software development process for ML models is rarely the perfect waterfall development model, as shown in Figure 1 without the green arrows. In the (discredited) waterfall development process, you would start out with requirements, then move on to design, implementation and test. The (current!) equivalent process in ML model development is the following, as shown in Figure 1 with the green arrows. You start out on your local machine with a subset of the data in order to explore and design the model architecture. Then you move to use a cluster of resources (such as GPUs) to more quickly find hyperparameters, run lots of parallel ablation studies (many skip this stage!), and finally scale out the training of the model on the large dataset using lots of resources. Then, you’re done, right? Wrong! You typically iterate through the stages, finding better hyperparameters, adding new features, rewriting for distribution, going from your laptop to the cluster and back again.
We rewrite our model training code for distribution as it offers many benefits – faster training of models using more GPUs, parallelizing hyperparameter tuning over many GPUs, and parallelizing ablation studies to help understand the behaviour and performance of deep neural networks. However, not only will the boiler plate model training code need to be modified, but as you move along the process, distribution will introduce additional obtrusive code artifacts and modifications, depending on the frameworks used. This will lead to a mix of infrastructure code and model code, with duplicated training logic, hyperparameters hard-coded into the training loop, additional tracking code to keep record of your changes and config files for experiments:

Figure 2: Model development creates a mix of code artefacts duplicating code for every step, making iterative development hard.
With such a code base, iterating becomes near impossible as it requires adapting many copies of redundant code. And finally, imagine handing the code off to an ML engineer to productionize the model.
The Oblivious Training Function
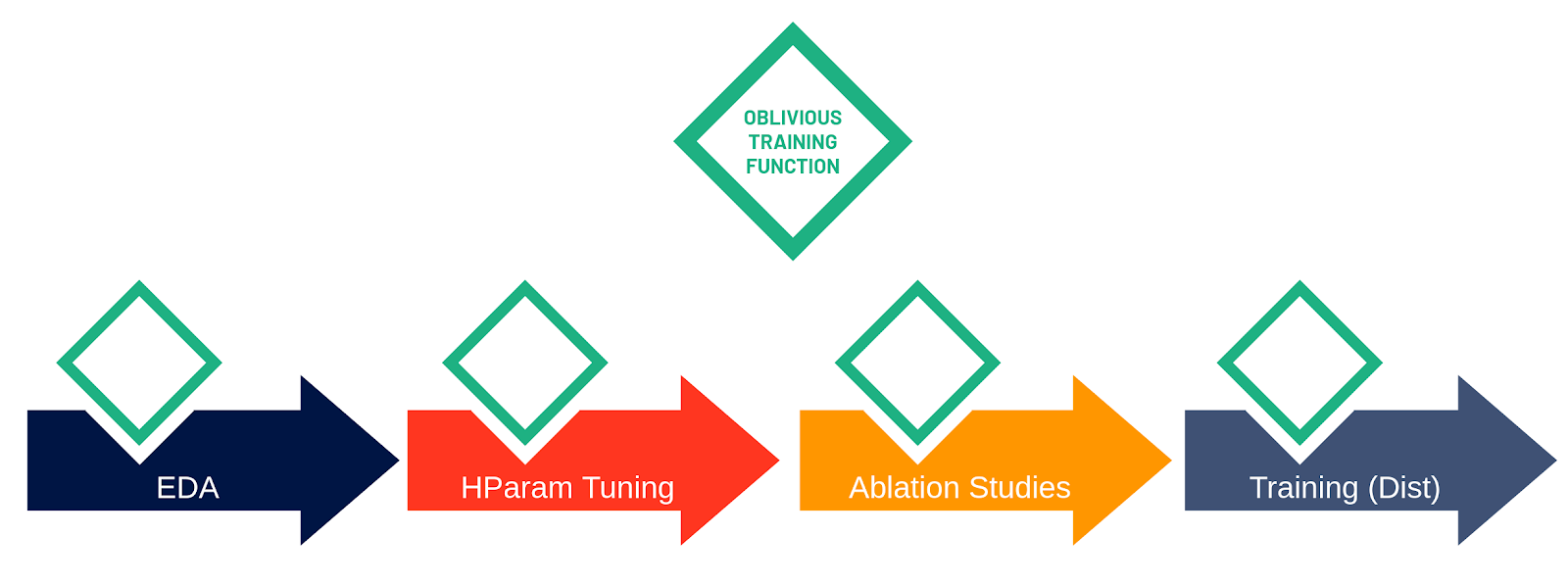
Figure 3: The oblivious training function makes training code reusable among all steps of the process.
We introduce an open-source framework, Maggy, that enables write-once training functions that can be reused in single-host Python programs and cluster-scale PySpark or Distributed TensorFlow programs. Training functions written with Maggy look like best-practice TensorFlow programs where we factor out dependencies using popular programming idioms (such as functions to generate models and data batches). We call this new abstraction for ML model development the oblivious training function, as the core model training logic supports distribution transparency, that is, the training code is not aware (oblivious) of whether it is being run on a single host or whether it is being executed on hundreds of devices in parallel.
What does it mean for training code to be distribution transparent?
Transparency in distributed systems refers to hiding distribution-specific aspects of an application from the developer - for example, a developer invoking a function may not know (or need to know) if the function she is calling is local to her application or on a remote server. This means, distribution transparency enables developers to write code that is reusable between single-host and distributed instantiations of a program:
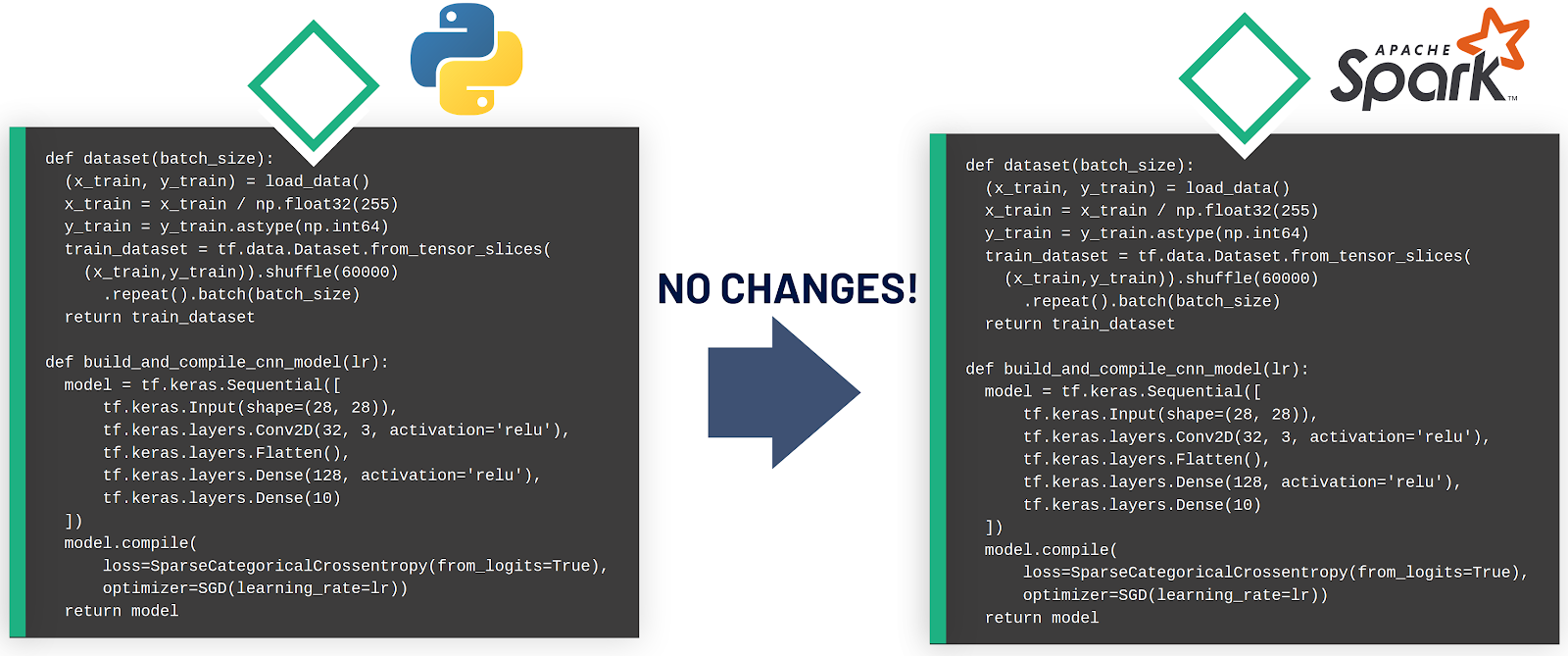
Figure 4: Distribution Transparency hides complexities related to distribution from the developer, making the same code executable on a single-host as well as in a large cluster. Transparency leads to [DRY](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself#:~:text=Don't%20repeat%20yourself%20(DRY,data%20normalization%20to%20avoid%20redundancy.) training code.
Building Blocks for Distribution Transparency
How does ML code have to be structured in order to be transparently distributed? Firstly, developers have to follow best practices and, secondly, developers must be aware of the difference between distribution contexts, that is, what characterizes, for example, distributed hyperparameter tuning vs. distributed training.
1. ML Development Best Practices:
The ML community has recently developed some best practices, which are already widely spread among developers. Taking a look at the new well-illustrated Keras Guides, you will notice a common approach with four techniques.
- Modularize: By modularizing code into reusable functions, these functions become building blocks, making the code pluggable in order to construct different configurations of the model for hyperparameter optimization or ablation.
- Parametrize: Instead of hardcoding parameters such as learning rate, regularization penalty or other hyperparameters, developers are encouraged to replace this with variables whenever possible, to have a single place for them to be changed.
- Higher order training functions: instead of using instantiated objects for example for the training dataset, the input logic related to the data can be encapsulated in a function which is being used by a higher order function. By doing so also the data input pipeline can be parametrized. The same holds for the generation of the model, which can be encapsulated in a function returning the model.
- Usage of callbacks at runtime: In order to be able to intercept and interact with the actual training loop, most ML frameworks such as TensorFlow and PyTorch offer the possibility to use callback functions that are invoked by the framework at certain points in time during training, such as at the end of every epoch or batch. Callback functions enable runtime monitoring of training, and can, for example, also be used to add support to stop the training early (important in hyperparameter optimization).
2. Distribution Context
While a single-host environment is self-explanatory, there is a difference between the context of ML experiments, such as hyperparameter optimization or parallel ablation studies, and the distributed training of a single model. Both hyperparameter optimization and parallel ablation studies have weak scaling requirements (also known as embarrassingly parallel), because all workers execute independent pieces of work and have limited communication. For example, hyperparameter tuning involves training independent copies of the model with different hyperparameters or different architectures, in order to find the best performing configuration. Distributed training, however, is strong scaling, as it introduces significant communication and coordination between the workers. As workers are training a single model, they continually exchange gradients, which are computed on independent shards of data (data parallel training). Many distributed training problems, in fact, become (network or disk) I/O bound as they scale. Figure 5 illustrates the three contexts and the step in the model development process that they are applicable to.
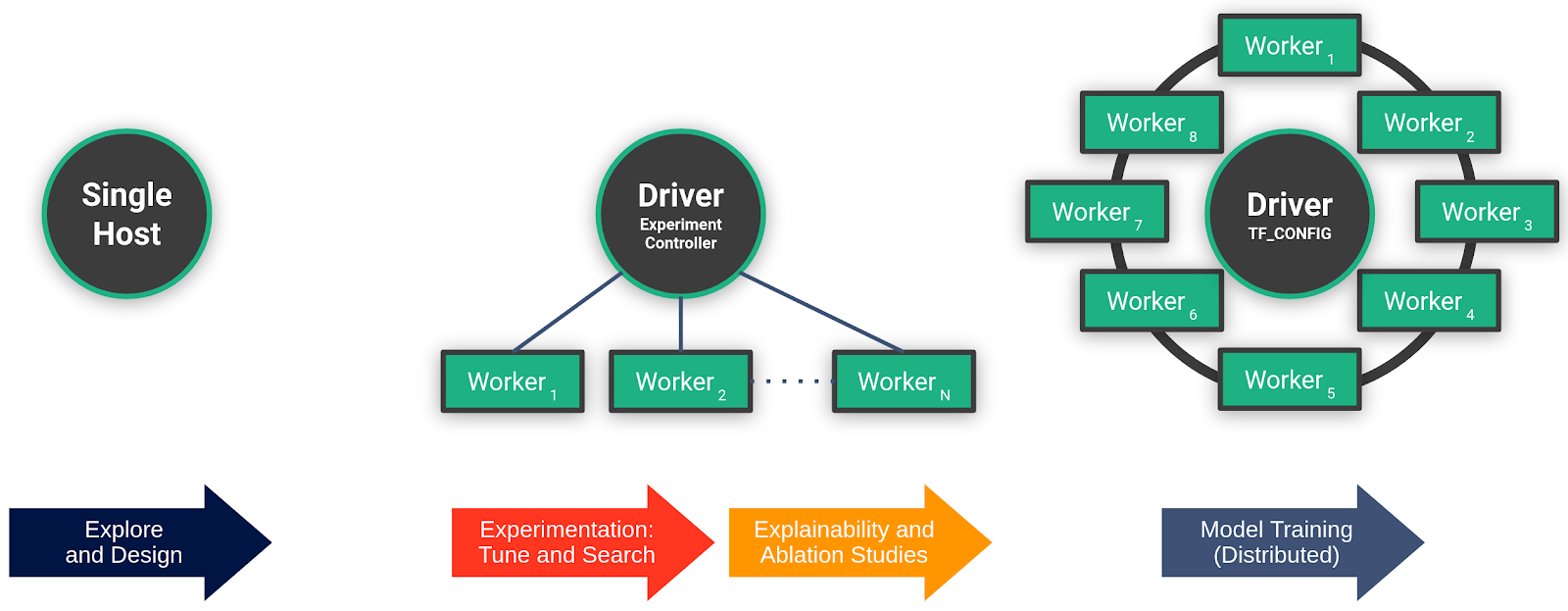
Figure 5: Single-host vs. parallel multi-host vs. distributed multi-host context and their applicability to the steps of the process.
Being aware of the different contexts and applying popular programming idioms, it becomes apparent what it means for the oblivious training function. It is no longer the developer herself who instantiates and launches the training function, but the framework that will invoke the training function as it is aware of the current context and it will take care of the distribution related complexities. That means, for exploration, the framework can be used to fix all parameters. For hyperparameter optimization experiments, the framework will take care of generating potentially good hyperparameter combinations and parameterizing the oblivious training function with them to be launched on different workers. For distributed training, it means setting up the environment for workers to discover each other and wrapping the model code with a distribution strategy.
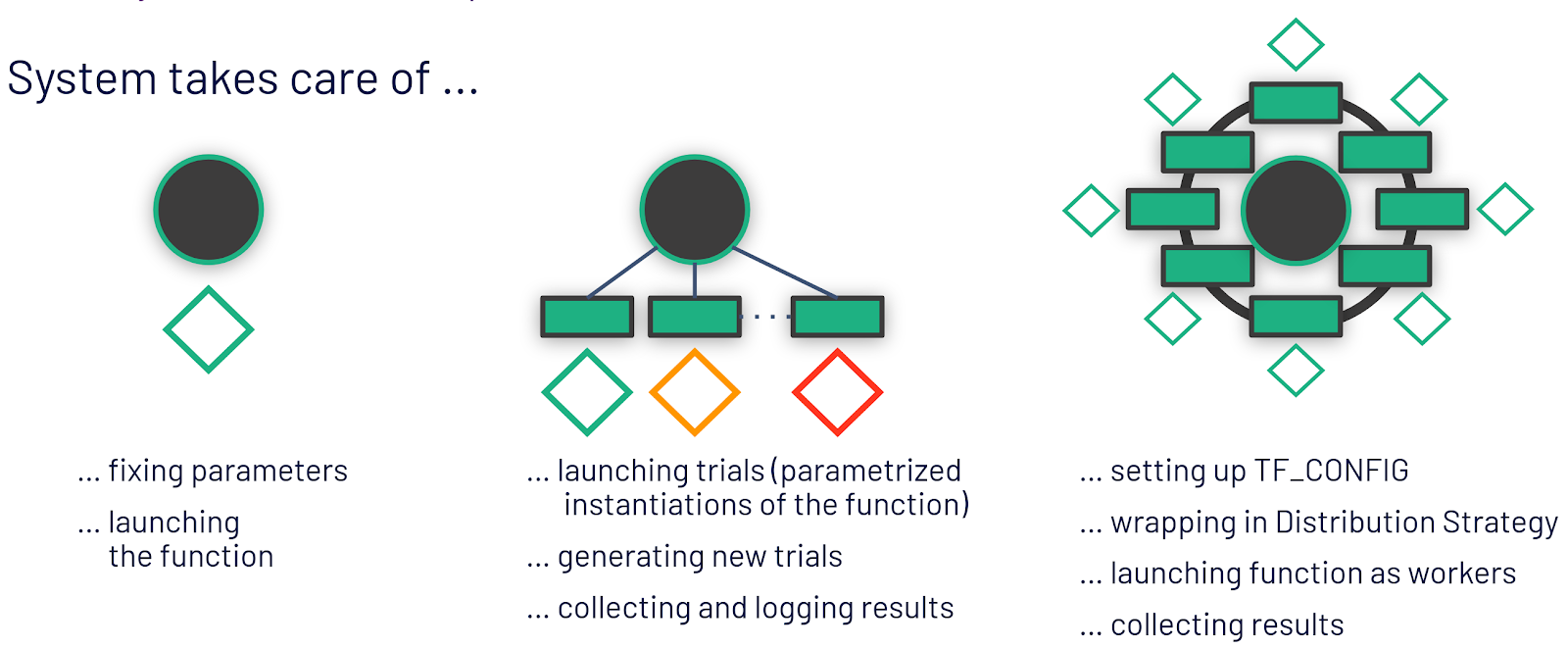
Figure 6: The oblivious training function as an abstraction allows us to let the system take care of distributed system related complexities.
Putting it all together
Having the building blocks at hand, how do we write the model training code in Maggy? Let us take a look at the latest best-practices MNIST example that already factors the model configuration, dataset preparation and training logic into functions. Building on this example, we will show the modifications to the code that are needed to construct an oblivious training function in Maggy. It is important to note that all modifications are still vanilla Python code, and can, therefore, be run as is on a single host environment. Let’s start with the boiler plate with the two functions and the training logic:
1. Model Definition
2. Data set generation
3. Training logic
1. Model generation
We are parametrizing the model itself, by replacing hyperparameters with arguments.
Parametrizing the model definion
2. Dataset generation
The dataset generation function stays unchanged in this case, but similar to the model, this function could be parametrized
3. Training logic
The training logic is wrapped in a parametrized and pluggable function, the oblivious training function. Again, hyperparameters are passed as arguments to the function. Additionally, the dataset and model generation functions are replaced with arguments, in order to be able to let the system, for example, replace the dataset generator with an alternative one - we use this to drop features for ablation studies. Last, but not least, the training function should return its current performance as a metric to be optimized in hyperparameter optimization. This is needed to make Maggy aware of the desired optimization metric.
Adjust Training Logic to be callable with different parameters
Note that up to this point, all modifications are pure Python code and, hence, the training function can still be run in a single host environment by calling it yourself in a Notebook with a fixed set of parameters and by passing the model and dataset generation functions as arguments.
Finally, to execute the function in a different distribution context, Maggy is used:
Maggy requires additional configuration information for hyperparameter optimization, such as a search space definition and the optimization strategy to be used. In the case of distributed training, the distribution strategy is needed as well as a set of parameters to fix the model to. These parameters can either be taken from the previous hyperparameter tuning experiments or input manually. Lagom is the API to launch the function on a Spark cluster.
Future Work
You can try out Maggy for hyperparameter optimization or ablation studies now on Hopsworks and keep an eye on Maggy's GitHub repo for the oblivious training function to be released as a pure Spark version or wait until the next release of Hopsworks, that will include full support. Maggy is still a project under heavy development and our mission with Maggy is to provide a new way of writing machine learning applications that reduces the burden on Data Scientists becoming distributed systems experts. By following the best practices we are able to keep the high-level APIs of frameworks like Keras and PyTorch free of distribution obtrusive code.
Summary
In this blog, we introduced a new feature to an open-source framework, Maggy, that enables write-once training functions that can be reused in single-host Python programs and cluster-scale PySpark programs. Training functions written with Maggy look like best-practice TensorFlow programs where we factor out dependencies using popular programming idioms (such as functions to generate models and data batches). In a single Jupyter notebook, developers can mix vanilla Python code to develop and test models on their laptop with PySpark-specific cells that can be run when a cluster is available using a PySpark kernel, such as Sparkmagic. This way, iterative development of deep learning models now becomes possible, moving from the laptop to the cluster and back again, with DRY code in the training function – as all phases reuse the same training code.