
Spark (EMR, Databricks, Cloudera, HDInsight, DataProc)
compute-pipelines
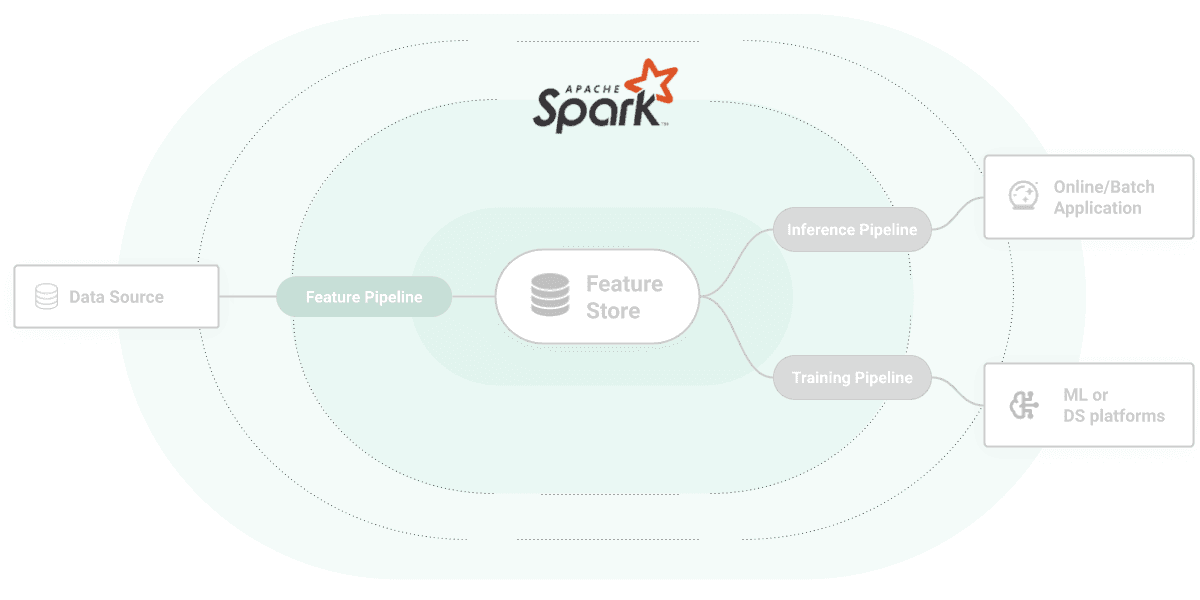
Spark can be used to implement batch feature pipelines, streaming feature pipelines, batch inference pipelines, and streaming inference pipelines for features that are written to Hopsworks Feature Store.