Platform
The Feature Store
The missing data layer for machine learning pipelines. Manage, reuse, and serve features with sub-millisecond latency - powered by RonDB, the world's fastest key-value store.
Life Without a Feature Store
Data is the hardest part of ML. Teams spend 80% of their time on feature engineering, yet features are duplicated, inconsistent, and impossible to reuse.
No Principled Feature Access
Features are embedded in training jobs. No way to access them during serving without duplicating code.
Training-Serving Skew
Features computed differently for training vs production. Inconsistent data causes model failures.
No Feature Reuse
Teams rebuild the same features from scratch. No sharing, no discovery, no governance.
Data Silos
Customer data lives in dozens of systems. Building ML features requires joining data that was never meant to be joined.
With a Feature Store
Data Scientists search for features and easily build models with minimal engineering. Features are cached and reused across models. A managed, governed asset for the enterprise.
Data Engineers
Write to the Feature Store
At the end of your feature pipeline, write features to the store instead of project-specific databases. Spark, Pandas, or any DataFrame API.
fg.insert(features_df)Data Scientists
Read from the Feature Store
Query features by name across any feature group. The query planner handles joins automatically. No SQL required.
fv.get_feature_vector(entity_id)Powered by RonDB
The world's fastest key-value store with SQL capabilities. Peer-reviewed benchmarks published and verified.
250k+
ops/sec
Feature vector lookups
7.5ms
p99 latency
11 features, ~1KB
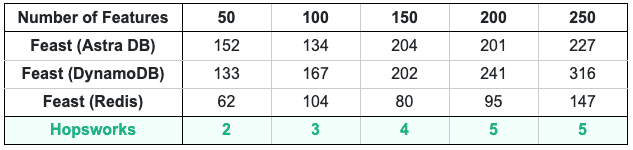
P99 latency comparison: Hopsworks vs Feast
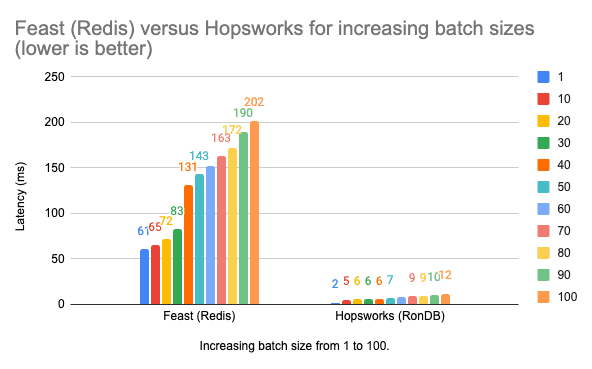
Feature vector retrieval: batch size scaling
Dual Storage
Online + Offline Store
A transparent dual storage system. The offline store for high-bandwidth training, the online store for low-latency serving. Same features, consistent data.
Offline Store
Apache Hudi tables on HopsFS (S3/Azure). High bandwidth for training and batch inference. Time-travel for reproducibility.
Online Store
RonDB key-value store. Sub-millisecond latency for real-time serving. Stores only latest feature values per primary key.
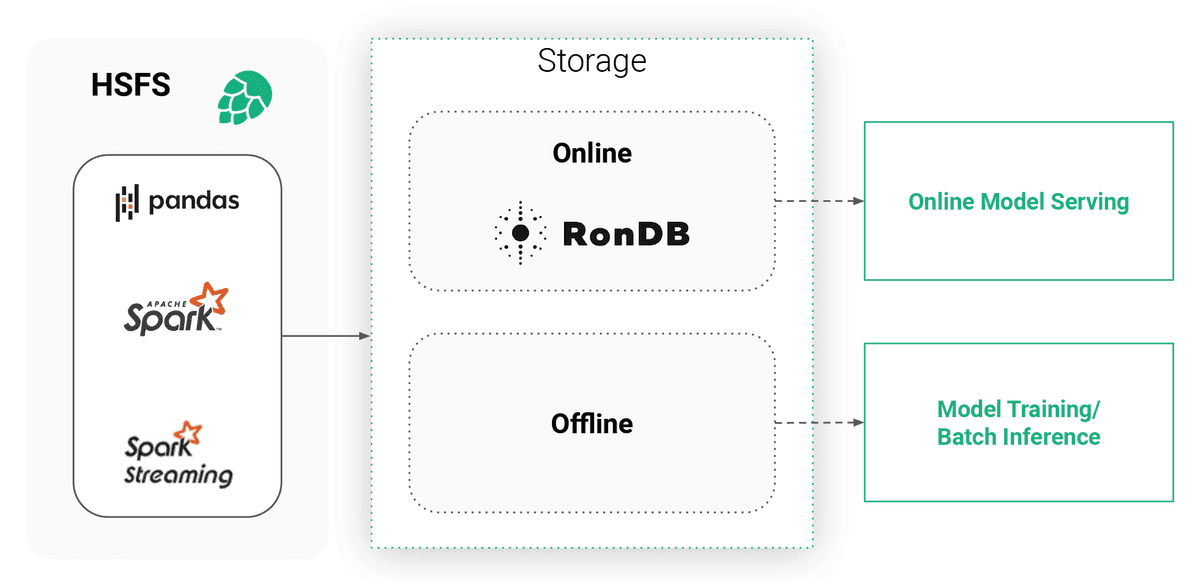
HSFS abstracts the dual storage system - write once, serve anywhere.
Enterprise Feature Management
Everything you need to manage features at scale - from ingestion to serving to monitoring.
Sub-Millisecond Serving
Powered by RonDB, the world's fastest key-value store. 250k+ ops/sec with 7.5ms p99 latency.
Dual Storage System
Online store for low-latency serving, offline store for training. Same features, consistent data.
Point-in-Time Correct
Generate training datasets that reflect feature state at any historical point. No data leakage.
Feature Reuse
Build features once, use everywhere. Meta reports top 100 features reused across 100+ models.
Data Lineage
Track every feature from raw data to production. Full audit trails for compliance.
Feature Monitoring
Track distributions, detect drift, receive alerts. Ensure models always have reliable inputs.
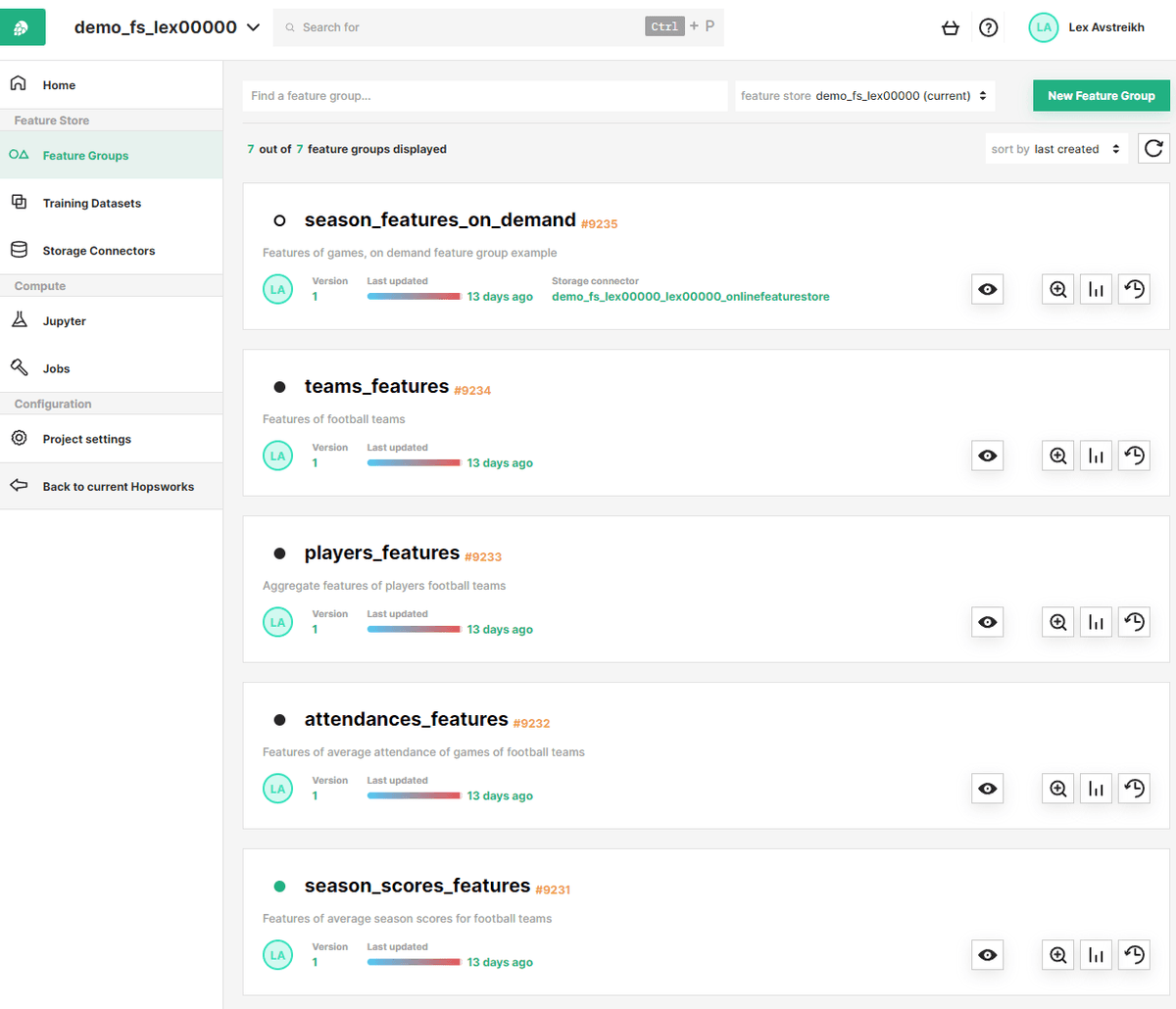
Feature Registry: search, discover, and analyze features across your organization.
Discovery
Feature Registry
When starting a new project, Data Scientists scan the registry for existing features. Only add new features that don't already exist.
Keyword search on metadata
Automatic feature analysis & statistics
Version comparison & evolution tracking
Access control & governance
Economies of Scale for ML
The more features in your store, the easier it becomes to build new models. Uber reported 10,000+ features in their feature store in 2017.
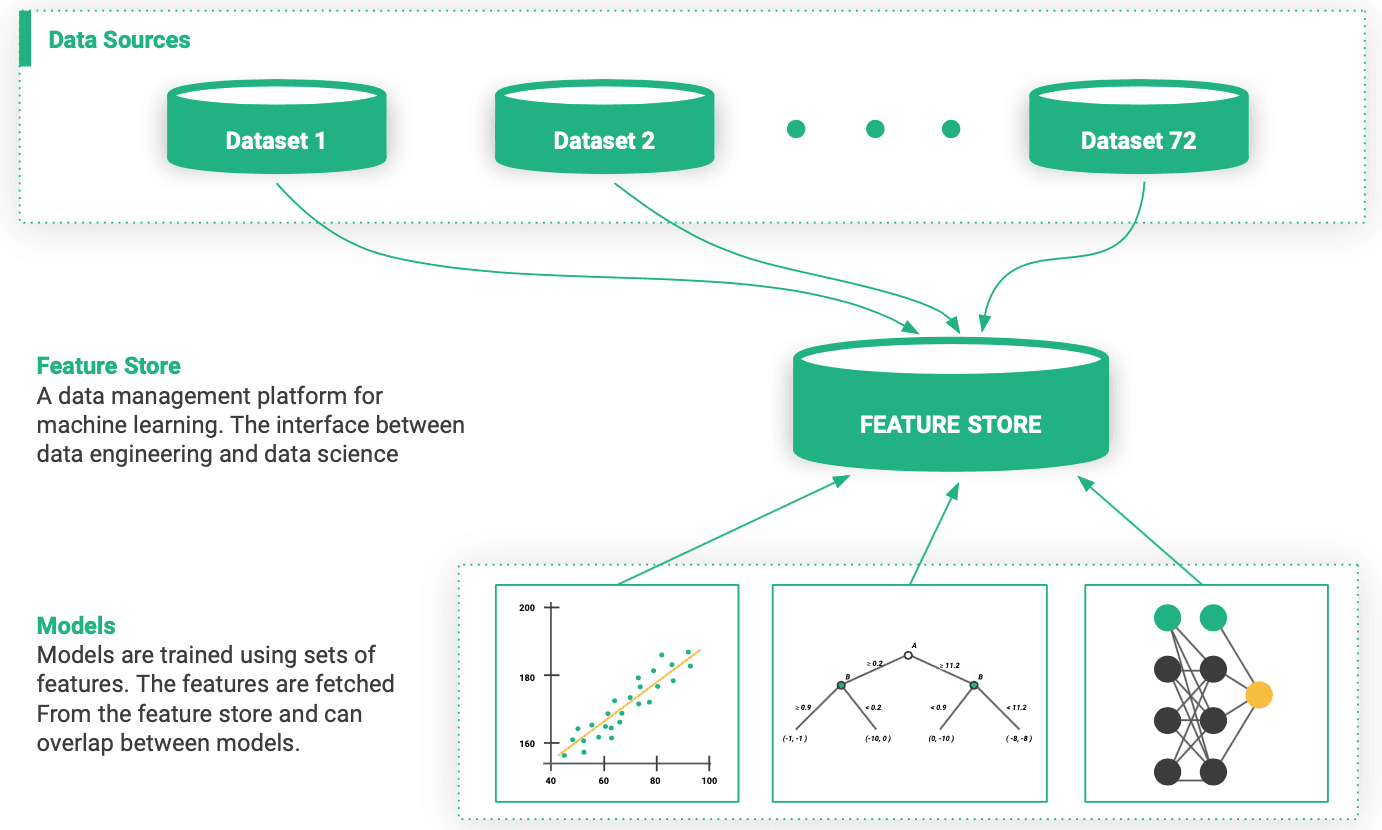
Centralizing feature storage reduces ramp-up time for new models and projects.
The Missing Data Layer for ML
Stop rebuilding features from scratch. Start sharing, reusing, and serving features with enterprise-grade infrastructure.