Hopsworks Feature Store for Databricks
This blog introduces the Hopsworks Feature Store for Databricks, and how it can accelerate and govern your model development and operations on Databricks.

What is a Feature Store?
The Feature Store for machine learning is a feature computation and storage service that enables features to be registered, discovered, and used both as part of ML pipelines as well as by online applications for model inferencing. Feature Stores are typically required to store both large volumes of feature data and provide low latency access to features for online applications. As such, they are typically implemented as a dual-database system: a low latency online feature store (typically a key-value store or real-time database) and a scale-out SQL database to store large volumes of feature data for training and batch applications. The online feature store enables online applications to enrich feature vectors with near real-time feature data before performing inference requests. The offline feature store can store large volumes of feature data that is used to create train/test data for model development or by batch applications for model scoring. The Feature Store solves the following problems in ML pipelines:
- reuse of feature pipelines by sharing features between teams/projects;
- enables the serving of features at scale and with low latency for online applications;
- ensures the consistency of features between training and serving - features are engineered once and can be cached in both the Online and Offline Feature Stores;
- ensures point-in-time correctness for features - when a prediction was made and an outcome arrives later, we need to be able to query the values of different features at a given point in time in the past.

The Feature Store for ML consists of both an Online and Offline database and Databricks can be used to transform raw data from backend systems into engineered features cached in the online and offline stores. Those features are made available to online and batch applications for inferencing and for creating train/test data for model training.
Engineer Features in Databricks, publish to the Feature Store
The process for ingesting and featurizing new data is separate from the process for training models using features that come from potentially many different sources. That is, there are often differences in the cadence for feature engineering compared to the cadence for model training. Some features may be updated every few seconds, while others are updated every few months. Models, on the other hand, can be trained on demand, regularly (every day or every week, for example), or when monitoring shows a model’s performance has degraded. Feature engineering pipelines are typically triggered at regular intervals when new data arrives or on-demand when source code is pushed to git because changes were made in how features are engineered.
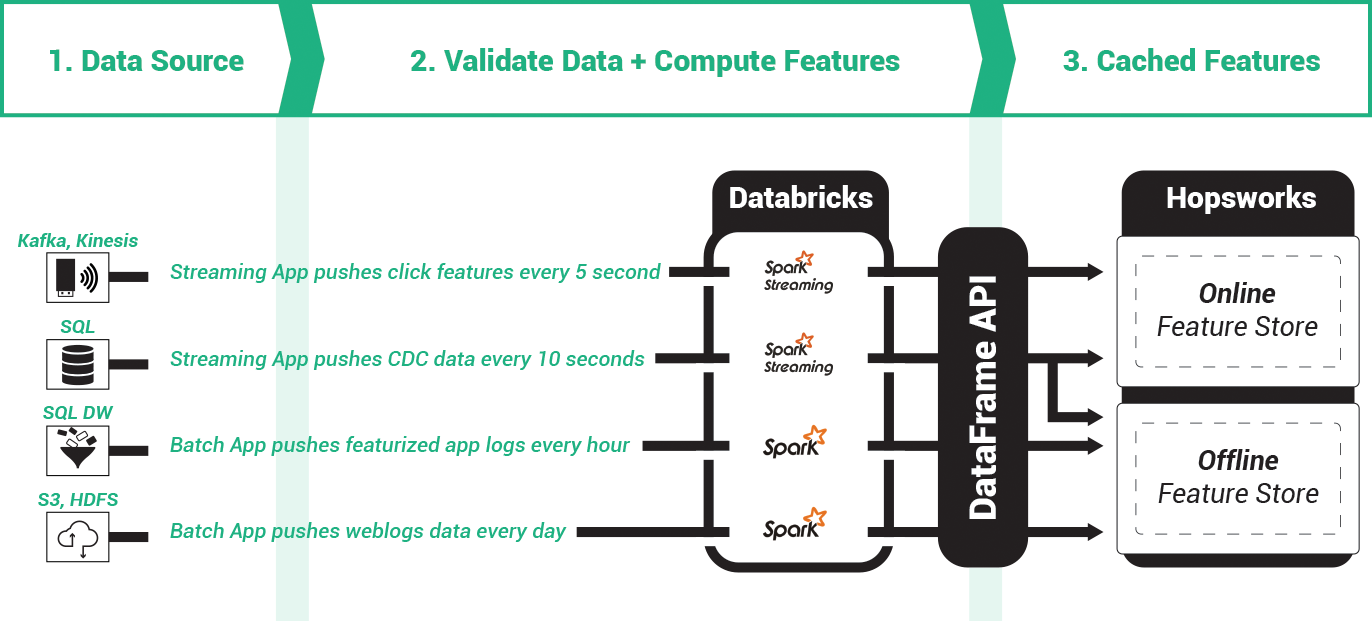
Feature pipelines have a natural cadence for each data source, and the cached features can be reused by many downstream model training pipelines. Feature Pipelines can be developed in Spark or Pandas applications that are run on Databricks. They can be combined with data validation libraries like Deequ to ensure feature data is correct and complete.
The feature store enables feature pipelines to cache feature data for use by many downstream model training pipelines, reducing the time to create/backfill features. Groups of features are often computed together and have their own natural ingestion cadence, see figure above. Real-time features may be updated in the online feature store every few seconds using a streaming application, while batch features could be updated hourly, daily, weekly, or monthly.
In practice, feature pipelines are data pipelines, where the output is cleaned, validated, featurized data. As there are typically no guarantees on the correctness of the incoming data, input data must be validated and any missing values must be handled (often by either imputing them or ignoring them). One popular framework for data validation with Spark is AWS Deequ, as they allow you to extend traditional schema-based support for validating data (e.g., this column should contain integers) with data validation rules for numerical or categorical values. For example, while a schema ensures that a numerical feature is of type float, additional validation rules are needed to ensure those floats lie within an expected range. You can also check to ensure a columns’ values are unique, not null, that its descriptive statistics are within certain ranges. Validated data is then transformed into numeric and categorical features that are then cached in the feature store, and subsequently used both to train models and for batch/online model inferencing.

In this code snippet, we connect to the Hopsworks Feature Store, read some raw data into a DataFrame from a parquet file, and transform the data into polynomial features. Then, we create a feature group, it’s version is ‘1’ and it is only to be stored in the ‘offline’ feature store. Finally, we ingest our new polynomial_dataframe into the feature group, and compute statistics over the feature group that are also stored in the Hopsworks Feature Store. Note that Pandas DataFrames are supported as well as Spark DataFrames, and there are both Python and Scala/Java APIs.
When a feature store is available, the output of feature pipelines is cached feature data, stored in the feature store. Ideally, the destination data sink will have support for versioned data, such as in Apache Hudi in Hopsworks Feature Store. In Hopsworks, feature pipelines upsert (insert or update) data into existing feature groups, where a feature group is a set of features computed together (typically because they come from the same backend system and are related by some entity or key). Every time a feature pipeline runs for a feature group, it creates a new commit in the sink Hudi dataset. This way, we can track and query different commits to feature groups in the Feature Store, and monitor changes to statistics of ingested data over time.
Model Training Pipelines in Databricks start at the Feature Store
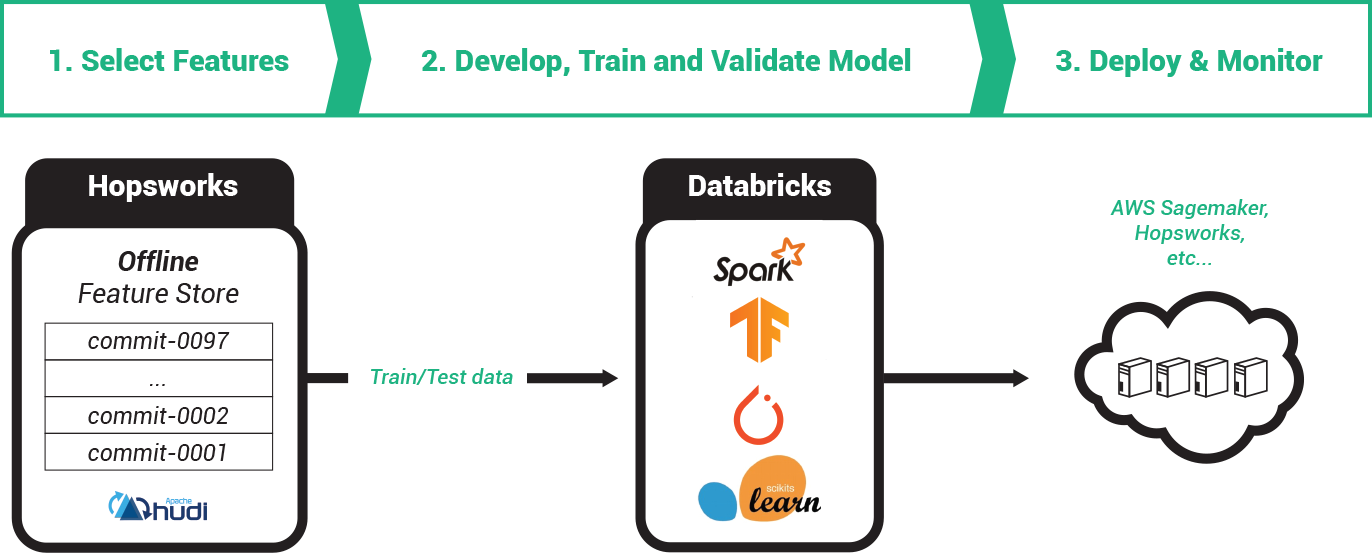
Model training pipelines in Databricks can read in train/test data either directly as Spark Dataframes from the Hopsworks Feature Store or as train/test files in S3 (in a file format like .tfrecords or .npy or .csv or .petastorm). Notebooks/jobs in Databricks can use the Hopsworks Feature Store to join features together to create such train/test datasets on S3.
Model training with a feature store typically involves at least three stages:
- select the features from feature groups and join them together to build a train/test dataset. You may also here want to filter out data and include an optional timestamp to retrieve features exactly as they were at a point of time in the past;
- train the model using the training dataset created in step 1 (training can be further decomposed into the following steps: hyperparameter optimization, ablation study, and model training);
- validate the model using automated tests and deploy it to a model registry for batch applications and/or an online model server for online applications.

Data Scientists are able to rely on the quality and business logic correctness in published features and can therefore quickly export and create training datasets in their favourite data format.
Deploying the Hopsworks Feature Store for Databricks
The Hopsworks Feature Store is available as a managed platform for AWS and as an Enterprise platform for Azure.
Hopsworks.ai for AWS
Hopsworks.ai is our new managed platform for the Hopsworks Feature Store on AWS. In its current version, it will deploy a Hopsworks Feature Store into your AWS account. From Hopsworks.ai, you can stop/start/backup your Hopsworks Feature Store.
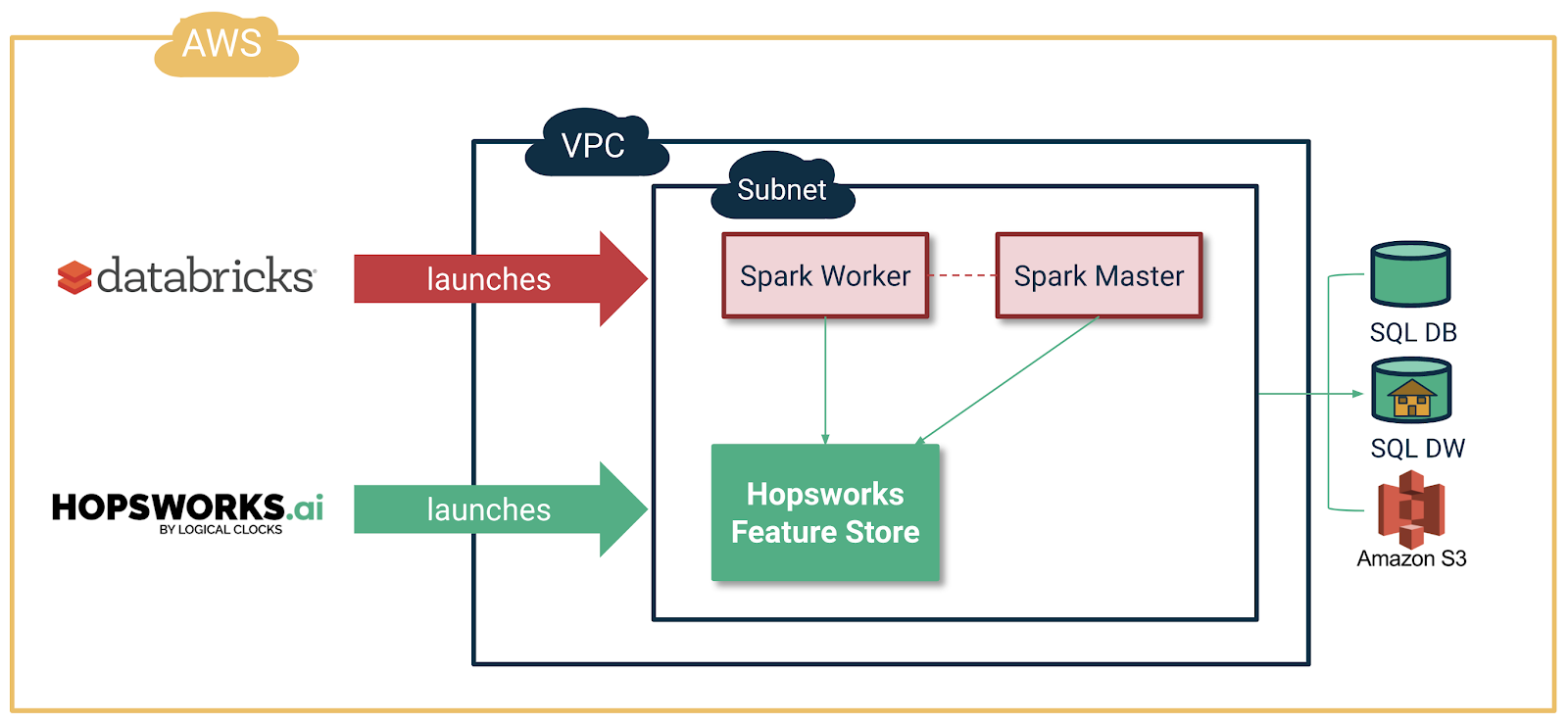
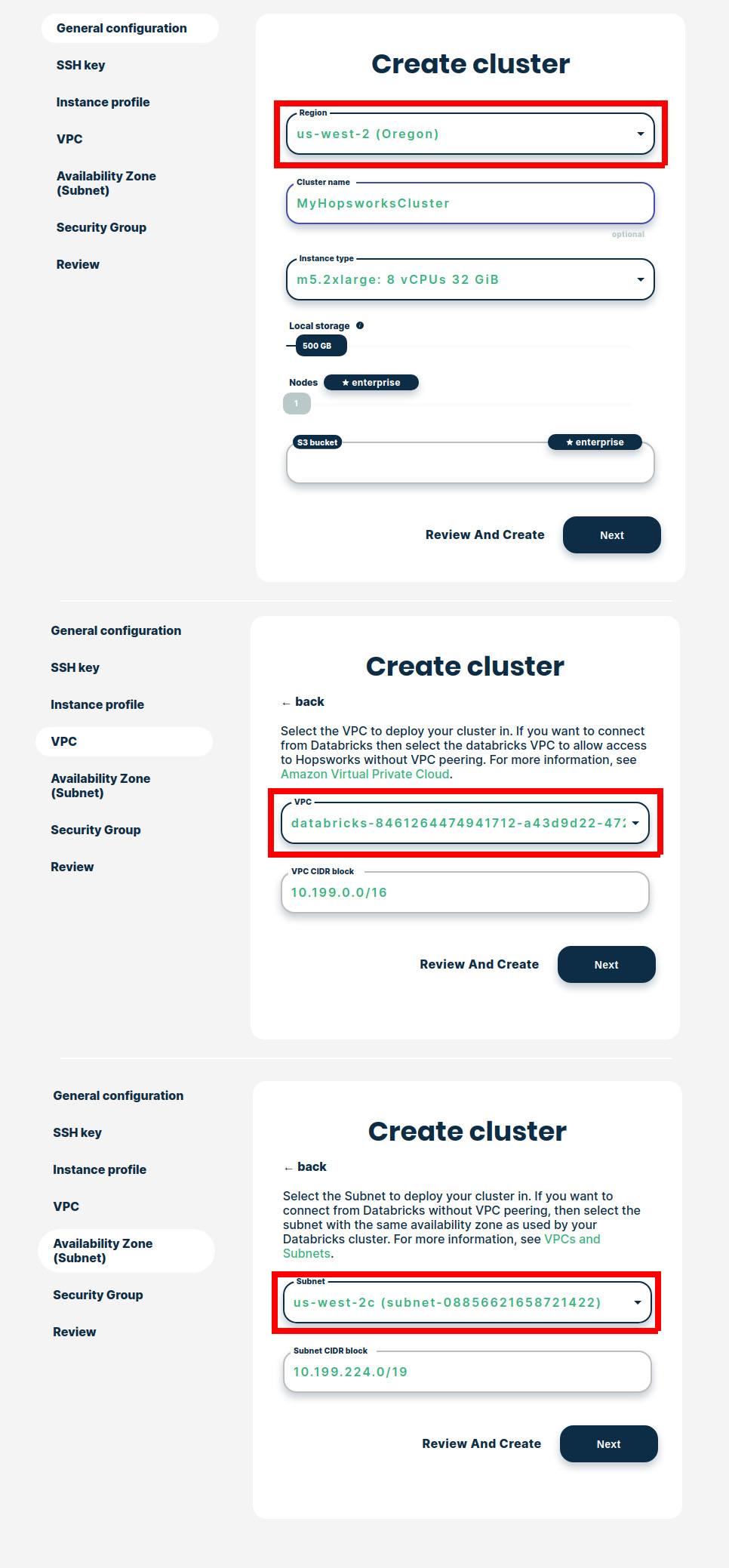
The details for how to launch a Hopsworks Feature Store inside an existing VPC/subnet used by Databricks are found in our documentation. The following figures from Hopsworks.ai show you how you have to pick the same Region/VPC/Zone used by your Databricks cluster when launching Hopsworks.
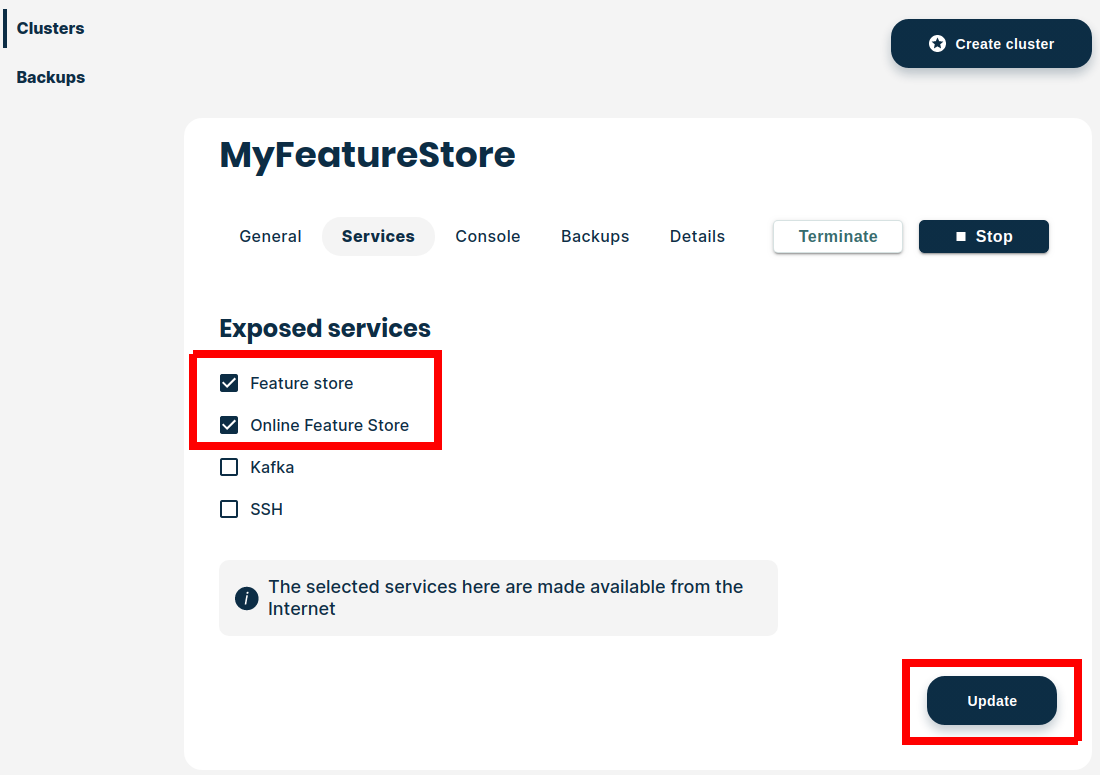
You also need to expose the Feature Store service for use by Databricks, see the figure below.
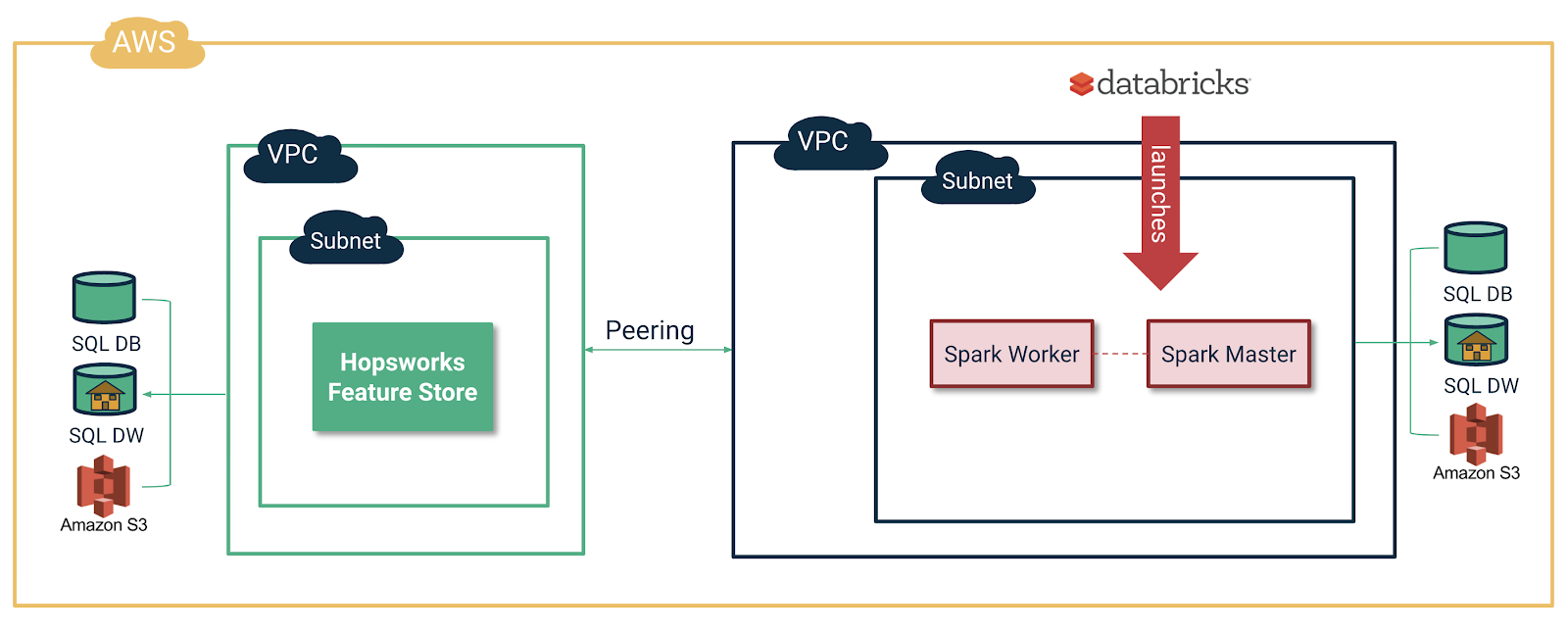
For some Enterprises, an alternative to deploying Hopsworks in the same VPC as Databricks is VPC peering. VPC peering requires manual work, and you can contact us for help in VPC peering.
Enterprise Hopsworks for Databricks Azure
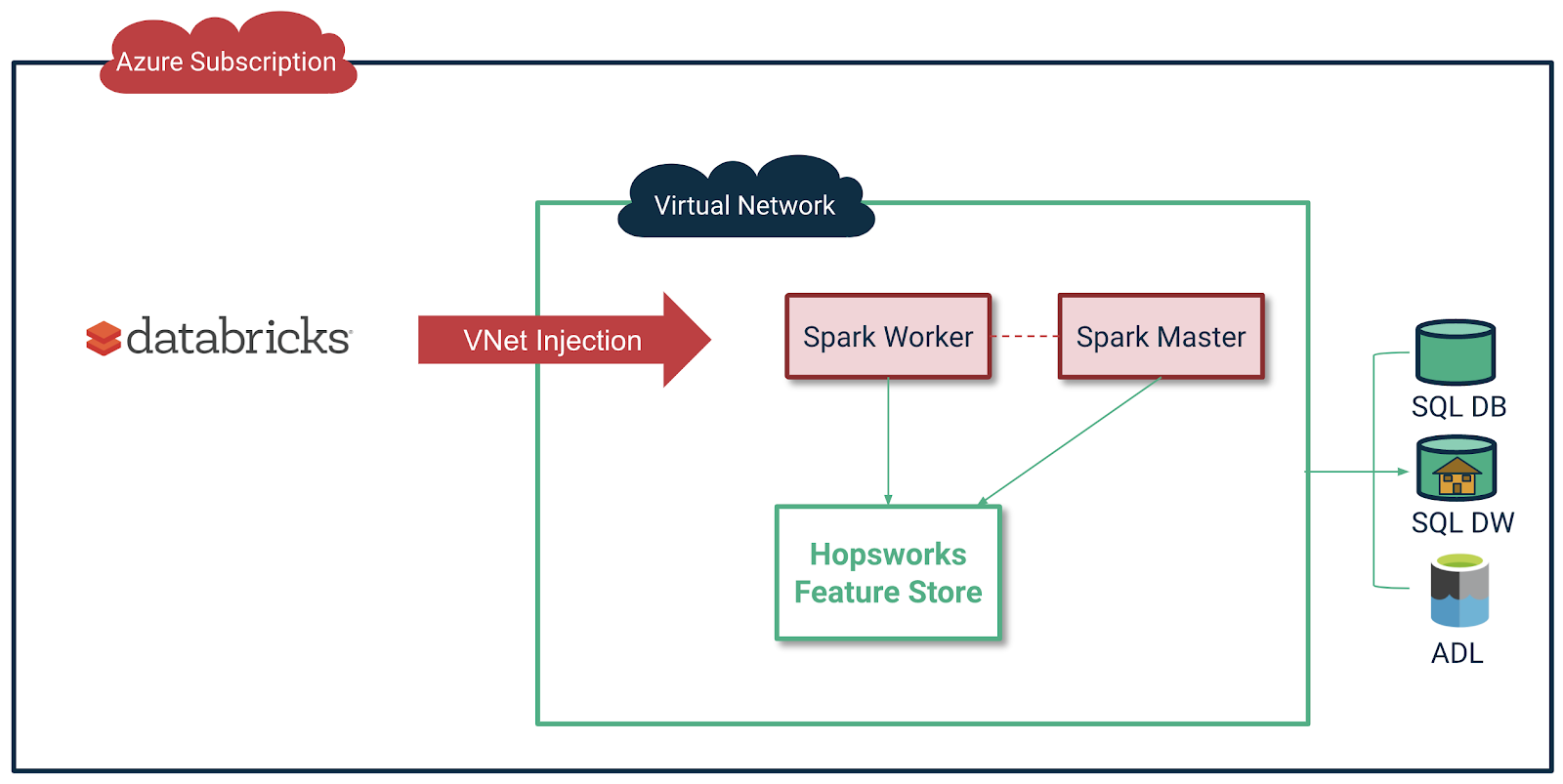
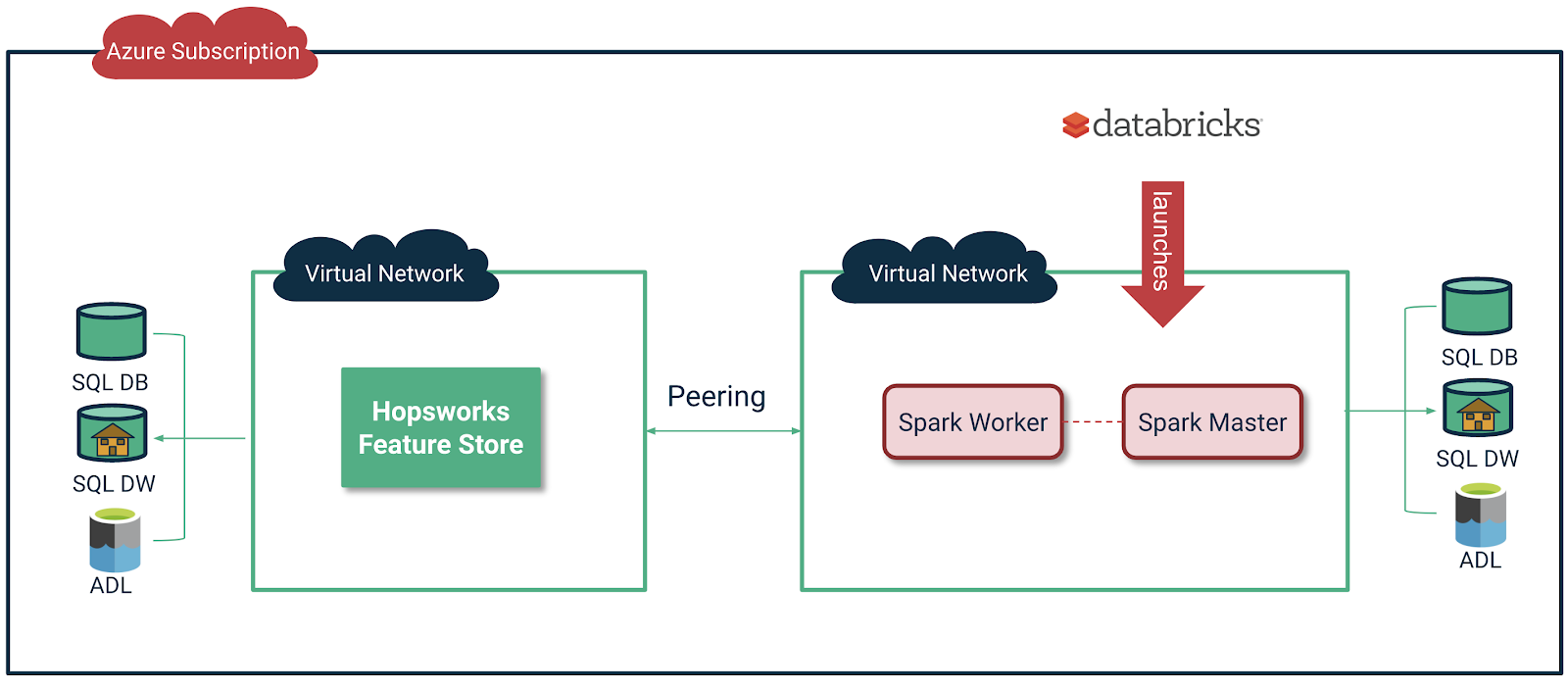
On Azure, by default, Databricks is deployed to a locked resource group with all data plane resources, including a virtual network (VNet) that all clusters will be associated with. However, with VNet injection, you can deploy Azure Databricks into the same virtual network where the Hopsworks Feature Store is deployed. Contact us for more details on how to install and setup VNet injection for Azure with Hopsworks Feature Store. An alternative to VNet injection is VPC, and you can contact us for help in VPC peering.
Learn more
Summary
A new key piece of infrastructure for machine learning has now arrived for Databricks users - the Hopsworks Feature Store. It enables you to centralize your features for ML for easier discovery and governance, it enables the reuse of features in different ML projects, and provides a single pipeline or engineering features for both training and inference. The Hopsworks Feature Store is available today as either a managed platform or AWS, so you can spin up a cluster in just a few minutes, or as an Enterprise platform for either AWS or Azure.