
Redshift
data-source; data-warehouse
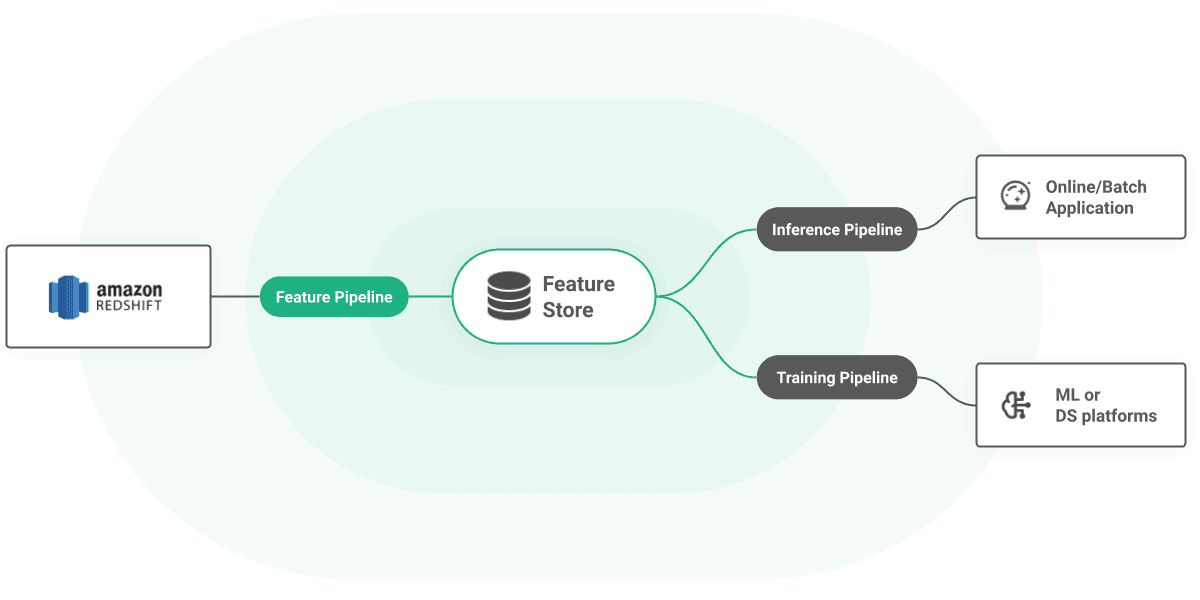
You can extend Redshift with real-time feature serving capability with Hopsworks. You can also centrally manage features stored in Redshift on Hopsworks, enabling them to be joined with features from other data sources. You can easily use Redshift tables as data sources in Python or Spark feature pipelines.