Building Feature Pipelines with Apache Flink
Find out how to use Flink to compute real-time features and make them available to online models within seconds using Hopsworks.

The case for decomposing the MLOps pipeline
Hopsworks feature store allows data scientists and data engineers to decompose a monolithic MLOps pipeline into three more manageable and independent programs: a feature pipeline, a training pipeline, and an inference pipeline.
The feature pipeline is responsible for computing the features and publishing them in the feature store. The training pipeline reads the features and labels (targets) as a training dataset, trains and saves the model. Finally, the inference pipeline retrieves the model and the inference data (from the online or offline feature store and/or user request data) and makes predictions with the model using the inference data.
This refactoring has the nice property of making the pipelines independent and composable. You can leverage different frameworks for the different pipelines, and Hopsworks abstracts away that complexity using unified dataframe-like APIs.
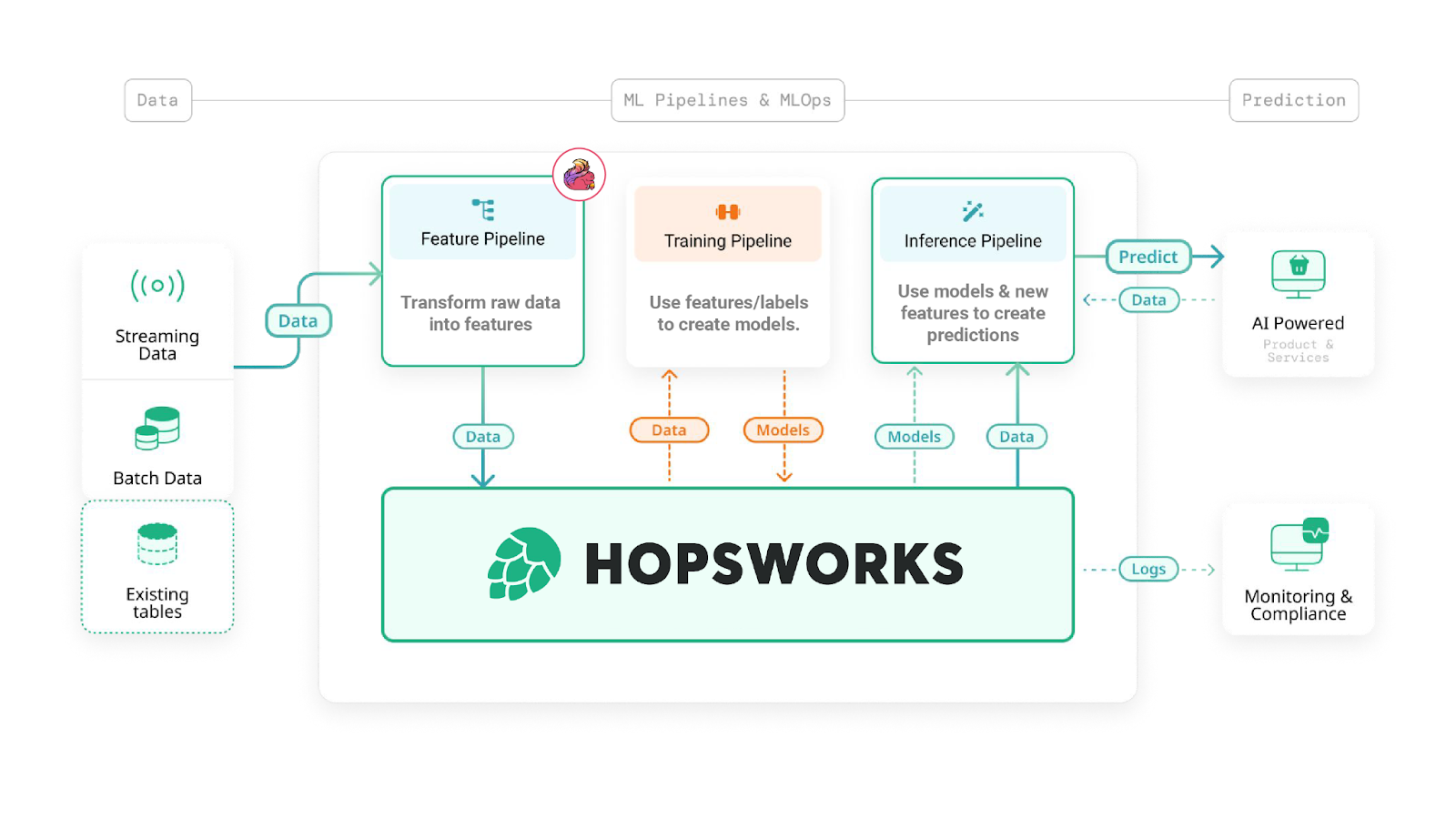
Figure 1. FTI Pipelines with Apache Flink
The case for streaming feature engineering
There is an entire class of ML-enabled use cases that require very fresh features (computed using data/events that is just a few seconds old). Use cases such as fraud detection, network intrusion detection, dynamic pricing, and real-time recommendation systems require events to be routed to real-time feature pipelines and the features to be published on the feature store - all within a few seconds - otherwise the models will be making predictions with stale features and will not be able to achieve their performance targets.
Spark Streaming and Apache Flink are popular frameworks for stream processing and can be used for real-time feature engineering. Hopsworks supports both frameworks for building streaming feature pipelines.
In this blog post, we will explore how to build a streaming feature pipeline in Flink. We will show how to use the Hopsworks Flink API to make feature data available in real-time to the online feature store, as well as materializing those features to the offline feature store to build the historical data which will be used in the future to retrain the models.
Building a Feature Pipeline in Flink
In the example below, we build a Flink-based feature pipeline which subscribes to a WebSocket feed from Coinbase that contains ETH-USD orders (orders for the Ethereum cryptocurrency, priced in US dollars). The pipeline performs several window aggregations and finally publishes the data to the Hopsworks feature store.
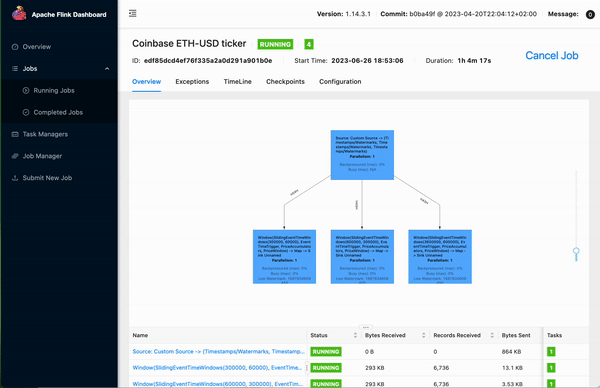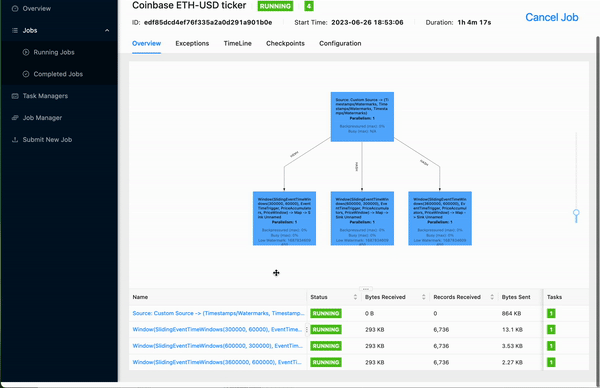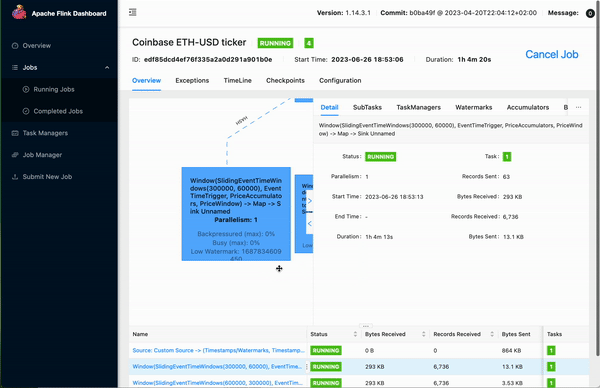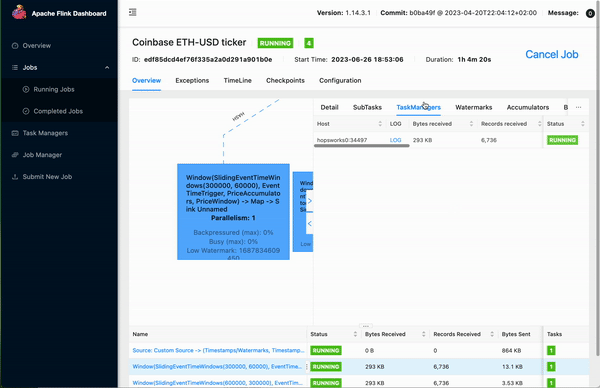
Figure 2. Building a Flink-based Pipeline
Creating a feature group
Before diving into the pipeline itself, we need to create the feature group that will contain the features. A feature group is a collection of features that are related to the same entity, e.g., a customer, an account, or a device.
A feature group needs to be created before the Flink pipeline can be started. Feature groups can be created using the UI or using the Hopsworks API (e.g., in a Python or Java program).
When creating a feature group, the only requirement is that the streaming APIs are enabled for the feature group.
When creating a feature group with the streaming API enabled, Hopsworks creates an Avro schema, defining the features and their data types in the feature group. You can retrieve the Avro schema from the Hopsworks schema registry, and we will use it to generate the Java class that represents our feature group.
Reading the WebSocket feed
The first step of the feature pipeline is to set up the WebSocket reader. Coinbase publishes several feeds (https://docs.cloud.coinbase.com/exchange/docs/websocket-overview). For this example, we are going to subscribe to the ticket feed for the ETH-USD exchange.
We create a custom WebSocket reader that can subscribe to the Coinbase feed and can parse the incoming messages. The WebSocket reader extends the Flink RichSourceFunction class and sets up a listener using the AsynchHttp library.
When new messages are received, the reader deserializes them and puts them in a queue. Flink is going to be listening to events from that queue and process them in the next stage.
Feature Engineering
We set up several window-based aggregations over the ticket stream. We compute the minimum, maximum and average price over the last 5, 10 and 60 minutes sliding windows.
Writing the features
The final step is to point the Flink stream to the Hopsworks feature store to write the features.
We use the avro-maven-plugin to convert the Avro schema generated by Hopsworks into the Java class representing the feature group.
We can then instantiate the class in our pipeline and populate it with the values generated by the window aggregations.
We connect to the Hopsworks feature store using the Hopsworks Flink Java SDK, retrieve the metadata object for the feature group, and call the insertStream method on it.
Online Materialization
The feature-engineered data will land on the online feature store as soon as it is produced by Flink. If you are curious about the latency, throughput, and the Hopsworks overhead, check out this blog post on 'Fast Access to Feature Data for AI Applications' we published with performance numbers related to writing to the online feature store.
Offline Materialization
The same data produced by Flink can be written to the offline feature store in batches. This is done using the backfilling job, which Hopsworks sets up automatically when creating a feature group with the streaming API enabled.
The job can be scheduled to run every now and then to write the data produced by Flink to the offline feature store. The frequency of the job should be correlated to the amount of data produced by the stream. For performance reasons, it’s better to perform more infrequent but larger commits.
Conclusion
In this blog post, we have seen how to build a feature pipeline using Apache Flink and how to publish the features to the online feature store. You can find the full codebase on Github - Coinbase Hopsworks Flink
You can also have a look at the Hopsworks Flink API documentation.