Guide to File Formats for Machine Learning
How to Choose the Right File Format for ML Training, Serving, and Feature Engineering
This blog is a guide to the popular file formats used in open source frameworks for machine learning in Python, including TensorFlow/Keras, PyTorch, Scikit-Learn, and PySpark.

A file format defines the structure and encoding of the data stored in it and it is typically identified by its file extension – for example, a filename ending in .txt indicates the file is a text file. However, even though files are used to store much of the world’s data, most of that data is not in a format that can be used directly to train ML models.
This post is mostly concerned with file formats for structured data and we will discuss how the Hopsworks Feature Store enables the easy creation of training data in popular file formats for ML, such as .tfrecords, .csv, .npy, and .petastorm, as well as the file formats used to store models, such as .pb and .pkl . We will not cover other well-known file formats, such as image file formats (e.g., .png, .jpeg), video file formats (e.g.,.mp4, .mkv, etc), archive file formats (e.g.,.zip, .gz, .tar, .bzip2), document file formats (e.g., .docx, .pdf, .txt) or web file formats (e.g., .html).
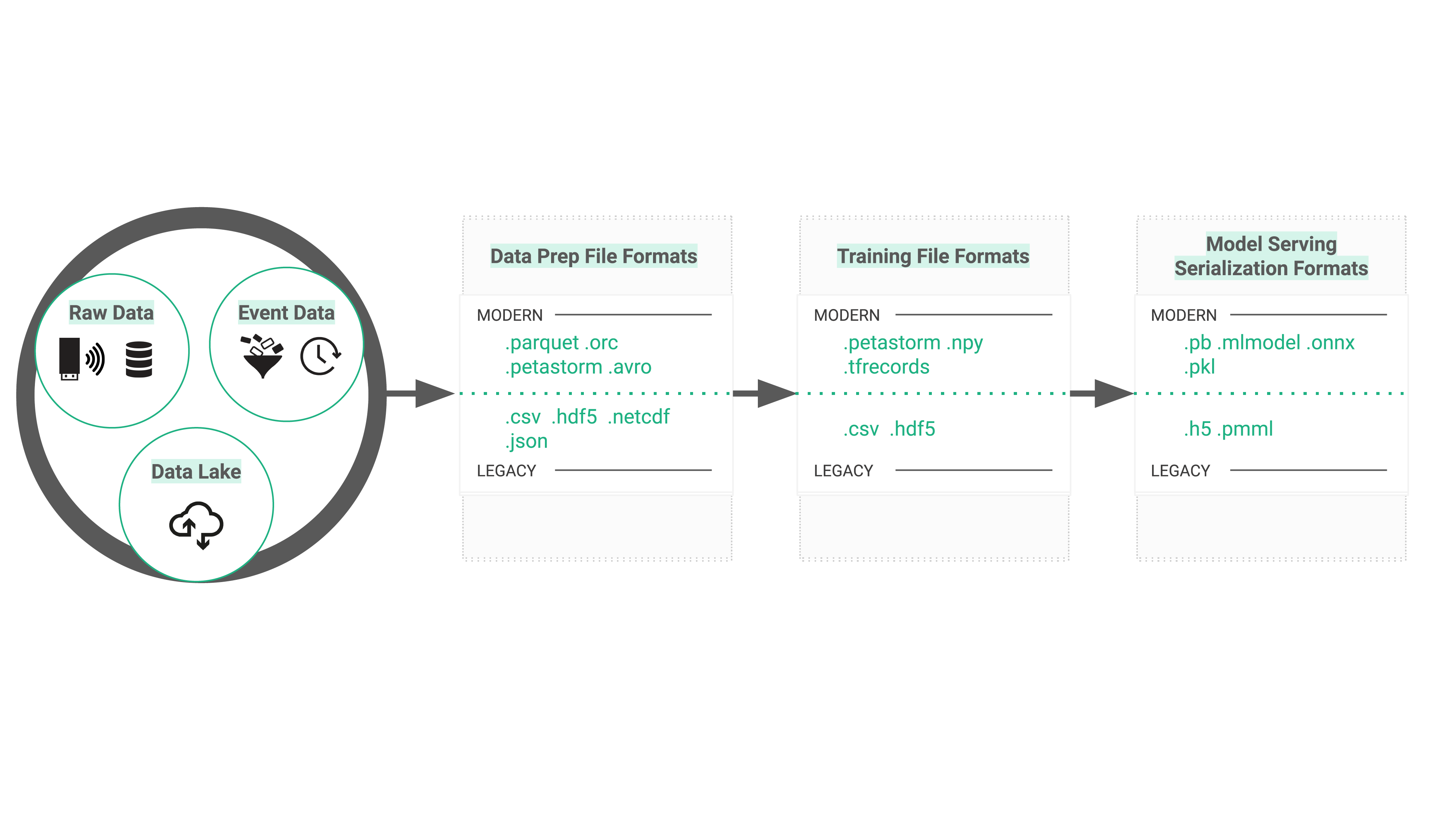
Data sources: file systems, distributed file systems, and object stores
Files are stored on file systems, and, in the cloud, increasingly on object stores. File systems come in different flavors. A local file system (POSIX) usually stores its data on one or more disks (magnetic (hard drives), SSD (solid-state storage), or NVMe drives).
Such file systems can be accessible over the network (e.g., NFS), or if large amounts of capacity are needed distributed file systems can be used that scale to store hundreds of Petabytes of data across thousands of servers, like HDFS, HopsFS, and CephFS. In the cloud, object stores are the cheapest file storage option where the files can be read/written with reasonable performance by applications.
File formats are linked to their file system. For example, if you ran a TensorFlow/Pytorch application to train ImageNet on images stored in S3 (object store) on a Nvidia V100 GPU, you might be able to process 100 images/sec, as that is what a single client can read from S3. However, the V100 can potentially process 1000 images/sec – you are bottlenecking on the I/O to the filesystem.
New file formats appear to get around just this type of problem. For example, the petastorm file format was developed by Uber to store PBs of data for self-driving vehicles that is stored on HDFS. petastorm files are large, splittable, and compressed with readers for TensorFlow and PyTorch enabling them to feed lots of V100 in parallel, ensuring they do not bottleneck on file I/O – as they would have if they worked with traditional multimedia file formats on slower network file systems. An alternative, but much more expensive solution, would be to work with the traditional file formats on storage devices made up of hundreds or thousands of NVMe disks.
Machine learning frameworks want to consume training data as a sequence of samples, so file formats for training ML models should have easily consumable layouts with no impedance mismatch with the storage platform or the language used to read/write the files. Additionally, distributed training (training ML models on many GPUs at the same time to make training go faster) requires files to be splittable and accessible over a distributed file system or object store, so that different GPUs can read different shards (partitions) of the data in parallel from different servers.
Big Data – from Binary to Structured Data
Machine learning has produced technological breakthroughs in a number of domains, such as image classification, voice recognition, voice synthesis, natural language processing, and neural machine translation. The types of file formats used in these systems are typically compressed binary or plaintext data formats.
Machine learning has extended its impact beyond these first domains and is now being applied to Enterprise data to solve business problems that can be modelled as supervised machine learning problems. However, much of Enterprise data is available as structured data – originating from Data Warehouses, databases, document repositories, and Data Lakes. Structured Enterprise data can also be used in a variety of text-based and binary file formats. In general, if you have large amounts of data, then you should consider using a binary file format (instead of a traditional text-based format like CSV), as binary file formats may significantly improve the throughput of your import pipeline, helping reduce model training time. Binary file formats require less space on disk and take less time to read from disk. Binary file formats are significant as the other main trend in machine learning is the increasing use of deep learning. Deep learning is ravenous for data - it just keeps getting better the more data it is trained on – and with increased volumes of data, efficient, compressed file formats have a role to play in the deep learning wars to come.
File Formats in Machine Learning Frameworks
Older file formats (e.g., .csv) may not be compressed, may not be splittable (e.g., HDF5 and netCDF) so that they can work seamlessly when training with many workers in parallel, and may make it difficult to combine multiple datasets. However, if the framework you use for machine learning, such as TensorFlow, PyTorch, ScikitLearn, does not provide data import and preprocessing functionality that is integrated seamlessly with those file format features and data sources, then you may not get the benefit of better file formats. For example, the TFRecord file format was designed for TensorFlow and has full support in tf.data, while PyTorch’s DataLoader was designed, first-and-foremost, around Numpy files and then extended to other file formats. Similarly, ScikitLearn was first designed to work with CSV and Pandas and then extended to work with other file formats. So, while it is clear you should be using more modern file formats for machine learning, you still have the challenge of converting your data to this format, and there may be limited documentation available on how to do that. Fortunately, the Feature Store (introduced later) enables you to easily convert your data into the most important file formats for machine learning with no effort.
File Formats
This section introduces the most widely used file formats for ML, grouping them into known classes of well-known file format types: columnar, tabular, nested, array-based, and hierarchical. There are also new file formats that have been designed for model serving, that are described below.
Columnar Data File Formats
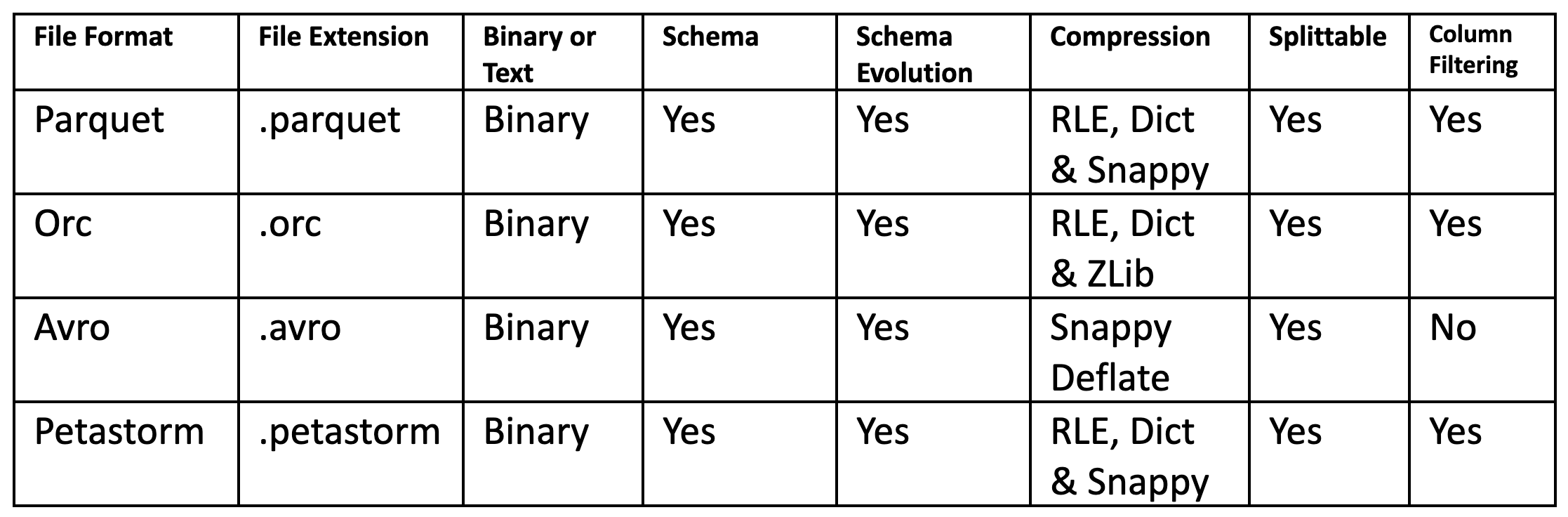
Apart from possibly Excel, the most common location for Enterprise data is the Data Warehouse or Data Lake. This data is typically accessed using Structured Query Language (SQL) and the data may be stored in either row-oriented format (typically OLTP databases that provide low latency access, high write throughput) or, more commonly, column-oriented format (OLAP/columnar databases that can scale from TBs to PBs and provide faster queries and aggregations). In Data Lakes, structured data may be stored as files (.parquet and .orc) that are still accessible via SQL using scalable SQL engines such as SparkSQL, Hive, and Presto. These columnar data files and backend databases are often the source of training data for Enterprise ML models, and feature engineering on them often requires data-parallel processing frameworks (Spark, Beam, and Flink) to enable feature engineering to scale-out over many servers. This scalable processing is enabled because the path to data in parquet/orc/petastorm data is actually a directory – not a file. The directory contains many files that can be processed in parallel. So, typically you supply the base path (directory) when you want to read data in a columnar file format, and the processing engine figures out which file(s) to read. If you only want to read a subset of columns from a table, files containing excluded columns will not be read from disk, and if you perform a range scan, statistics (max/min values for columns in files) in files enable data skipping - skip this file if your query asks for columns with values outside the range of values stored in the file.
While both parquet and orc have similar properties, Petastorm is uniquely designed to support ML data - it is the only columnar file format that natively supports multi-dimensional data. Columnar file formats typically assume 2-dimensional relational data, but tensors can have much higher dimensionality than 1-d vector or 2-d relational data sources. Petastorm provides multi-dimensional data capability by extending Parquet with its own Unischema designed explicitly for machine learning use-cases. The Unischema enables petastorm files to store multi-dimensional tensors natively in Parquet. The unischema is also compatible with PyTorch and TensorFlow so you can convert the petastorm schema directly to TensorFlow schema or PyTorch schema, which enables native TensorFlow/PyTorch readers for petastorm.
Columnar file formats are designed for use on distributed file systems (HDFS, HopsFS) and object stores (S3, GCS, ADL) where workers can read the different files in parallel.
- File formats: .parquet, .orc, .petastorm.
- Feature Engineering: PySpark, Beam, Flink.
- Training:.petastorm has native readers in TensorFlow and PyTorch;
.orc, .parquet have native readers in Spark;
JDBC/Hive sources supported by Spark
Tabular Text-based File Formats
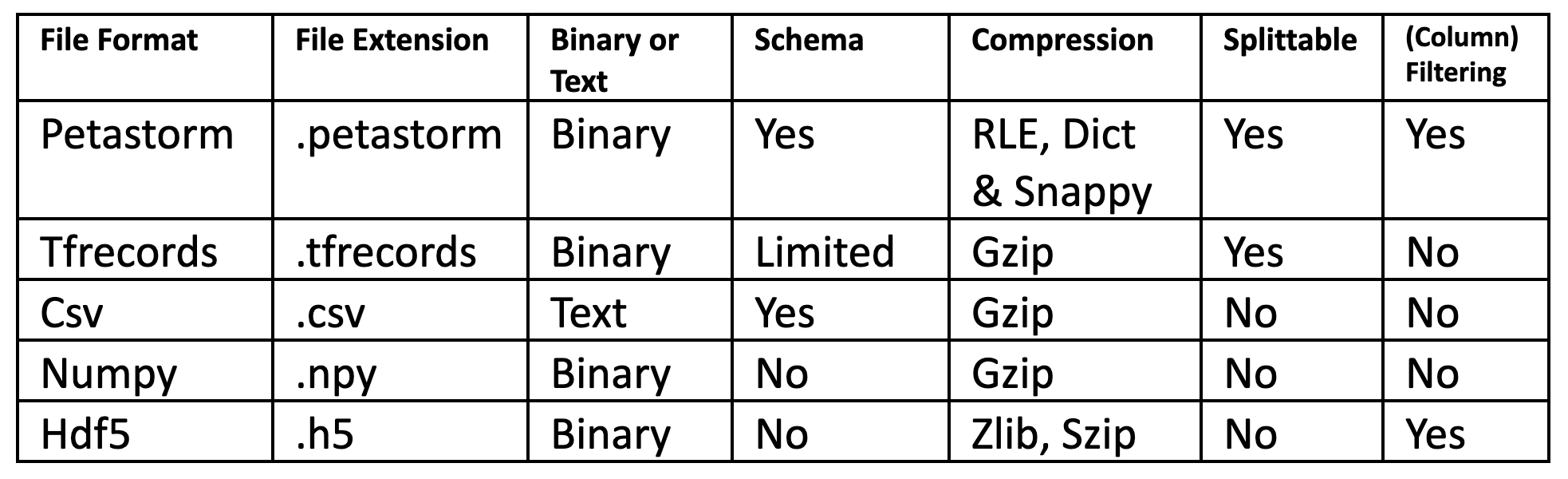
Tabular data for machine learning is typically found is .csv files. Csv files are text-based files containing comma separated values (csv). Csv files are popular for ML as they are easy to view/debug and easy to read/write from programs (no compression/indexing). However, they have no support for column types, there is no distinction between text and numeric columns, and they have poor performance which is more noticeable when the volume of data grows to GBs or more - they are not splittable, they do not have indexes, and they do not support column filtering. .csv files can be compressed using GZIP to save space. Other popular tabular formats that are not typically used in ML are spreadsheet file formats (e.g.,.xlsx and .xls) and unstructured text formats (.txt).
- File formats: .csv, .xslx
- Feature Engineering: Pandas, Scikit-Learn, PySpark, Beam, and lots more
- Training: .csv has native readers in TensorFlow, PyTorch, Scikit-Learn, Spark
Nested File Formats
Nested file formats store their records (entries) in an n-level hierarchical format and have a schema to describe their structure. A hierarchical format means that a record could have one parent (or be the root, with no parent) but it could also have children. Nested file format schemas are able to be extended (add attributes while maintaining backwards compatibility) and the order of attributes is typically not significant. The .json and .xml file formats are the best known plain text nested file formats, while binary nested file formats include protocol buffers (.pb) and avro (.avro).
TFRecords is a sequence of binary records, typically a protobuf with either a schema “Example” or “SequenceExample”. The developer decides whether to store samples as either an “Example” or a “SequenceExample”. Choose a SequenceExample if your features are lists of identically typed data. A TFRecords file can be a directory (containing lots of .tfrecords files), and it supports compression with Gzip. More details on how to use TFRecords can be found in the official documentation, and this good blog post.
- File formats: .tfrecords, .json, .xml, .avro
- Feature Engineering: Pandas, Scikit-Learn, PySpark, Beam, and lots more
- Training: .tfrecords is the native file format for TensorFlow;
.json has native readers in TensorFlow, PyTorch, Scikit-Learn, Spark
.avro files can be used as training data in TensorFlow with LinkedIn’s library.
Array-Based Formats
Numpy is an abbreviation of Numerical Python and it is a massively popular library for scientific computing and data analysis. Through support for vectorization, Numpy (.npy) is also a high performance file format. A Numpy array is a densely packed array with elements of the same type. The file format, .npy, is a binary file format that stores a single NumPy array (including nested record arrays and object arrays).
- File formats: .npy
- Feature Engineering: PyTorch, Numpy, Scikit-Learn, TensorFlow;
- Training: .npy has native readers in PyTorch, TensorFlow, Scikit-Learn.
Hierarchical Data Formats
HDF5 (.h5 or .hdf5) and NetCDF (.nc) are popular hierarchical data file formats (HDF) that are designed to support large, heterogeneous, and complex datasets. In particular, HDF formats are suitable for high dimensional data that does not map well to columnar formats like parquet (although petastorm is both columnar and supports high dimensional data). Lots of medical device data is stored in HDF files or related file formats, such as BAM, VCF for genomic data. Internally, HDF5 and NetCDF store data in a compressed layout. NetCDF is popular in domains such as climate science and astronomy. HDF5 is popular in domains such as GIS systems. They are not splittable, so not suitable for distributed processing (with engines like Spark).
- File formats: .h5 (HDF5), .nc (NetCDF)
- Feature Engineering: Pandas, Dask, XArray;
- Training: .h5 has no native readers in TensorFlow or PyTorch;
.nc has no native readers we are aware of.
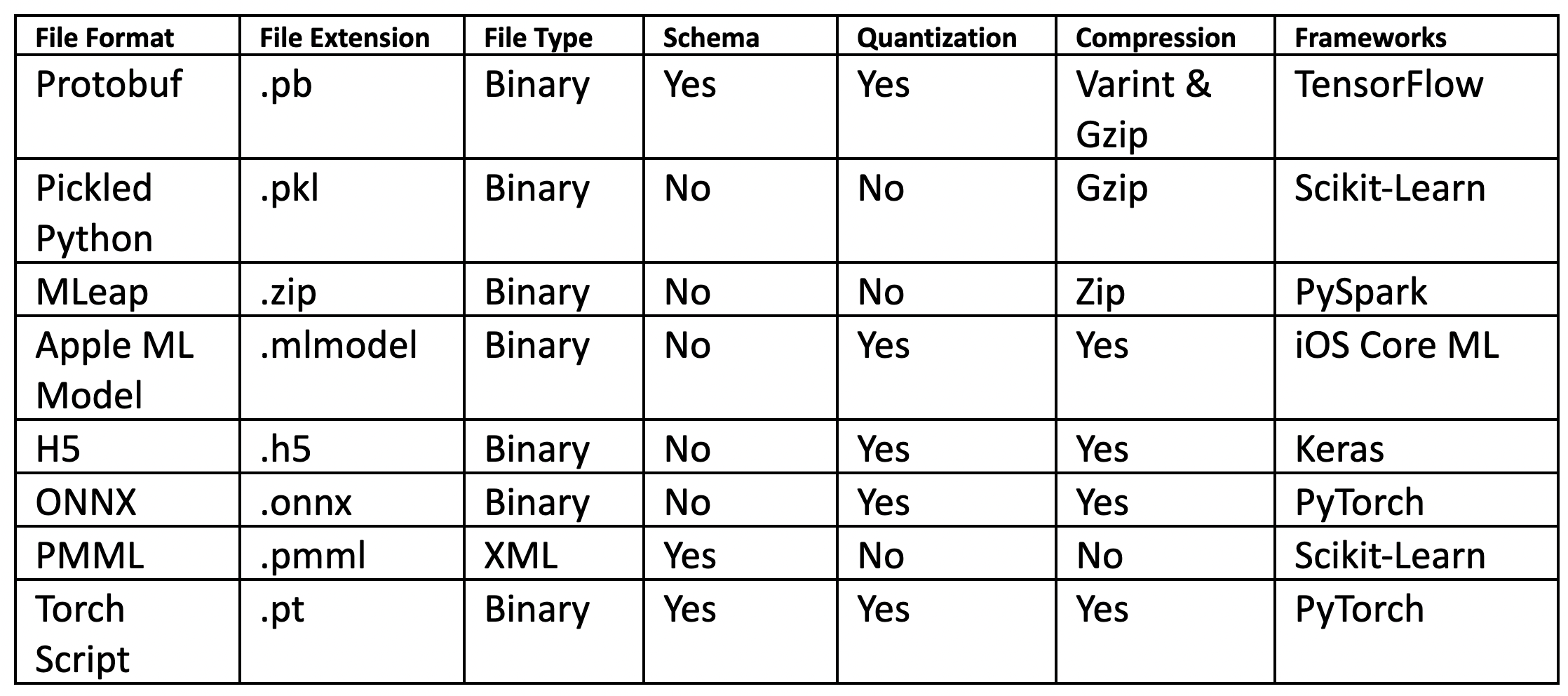
Model File Formats
In supervised machine learning, the artefact created after training that is used to make predictions on new data is called a model. For example, after training a deep neural network (DNN), the trained model is basically a file containing the layers and weights in the DNN. Often, models can be saved in a file that can potentially be compressed, so typically model files have a binary file format. TensorFlow saves models as protocol buffer files, with a .pb file extension. Keras saves models natively as .h5 file. Scikit-Learn saves models as pickled python objects, with a .pkl file extension. An older format for model serving based on XML, predictive model markup language (.pmml), is still usable on some frameworks, such as Scikit-Learn.
Model files are used to make predictions on new data by either (1) batch applications that typically read the model in as a file or (2) a real-time model serving server (such as TensorFlow Serving Server) that reads the model into memory, may even have multiple versions of a model in memory for AB testing.
Other model file formats that are used include SparkML models that can be saved in MLeap file format and served in real-time using a MLleap model server (files are packaged in .zip format). Apple developed the .mlmodel file format to store models embedded in iOS applications as part of its Core ML framework (which has superior support for ObjectiveC and Swift languages). Applications trained in TensorFlow, Scikit-Learn, and other frameworks need to convert their model files to the .mlmodel file format for use on iOS, with tools like, coremltools and Tensorflow converter being available to help file format conversion. ONNX is a ML framework independent file format, supported by Microsoft, Facebook, and Amazon. In theory, any ML framework should be able to export its models in .onnx file format, so it offers great promise in unifying model serving across the different frameworks. However, as of late 2019, ONNX does not support all operations for the most popular ML frameworks (TensorFlow, PyTorch, Scikit-Learn), so ONNX is not yet practical for those frameworks. In PyTorch, the recommended way to serve models is to use Torch Script to trace and save a model as a .pt file and serve it from a C++ application.
One final file format to mention here is YAML that is used to package models as part of the MLFlow framework for ML pipelines on Spark. MLFlow stores a YAML file that describes the files it packages for model serving, so that deployment tools can understand the model file format and know what files to deploy.
- File formats: .pb, .onnx, .pkl, .mlmodel, .zip, .pmml, .pt
- Inference: .pb files are served by TensorFlowServing Server;
.onnx files are served by Microsoft’s commercial model serving platorm;
.pkl files are served for Scikit-Learn models, often on Flask servers;
.mlmodel files are served by iOS platforms;
.zip files are used to package up MLeap files that are served on the MLeap runtime;
.pt files are use to package PyTorch models that can be served inside C++ applications.
ML Data File Formats Summary
A summary of the different file formats for the different ML pipeline stages (feature engineering / dataprep, training, and serving) is shown in tables below.
Feature Engineering File Formats
Model Training File Formats
Model Serving File Serialization Formats
And the winners are...
The most feature complete and language independent and scalable of the file formats for training data for deep learning is petastorm. Not only does it support high-dimensional data and have native readers in TensorFlow and PyTorch, but it also scales for parallel workers, but it also supports push-down index scans (only read those columns from disk that you request and even skip files where the values in that file are outside the range of values requested) and scales to store many TBs of data.
For model serving, we cannot really find any file format superior to the others. The easiest model serving solution to deploy and operate is protocol buffers and TensorFlow serving server. While both ONNX and Torch Script have potential, the open-source model serving servers are not there yet for them. Similarly, serving .pkl files on a flask server, while used heavily in production, still requires a lot more work on behalf of the ML operations engineer - you have to write your own Python serving program, manage security, load balancing, and much more.
Hopsworks and ML File Formats
In this section, we discuss support for converting ML feature data into the file format of your choice using the Hopsworks Feature Store, and the support for the main ML frameworks file formats in Hopsworks using the HopsFS file system.
Feature Store for File Format Conversion
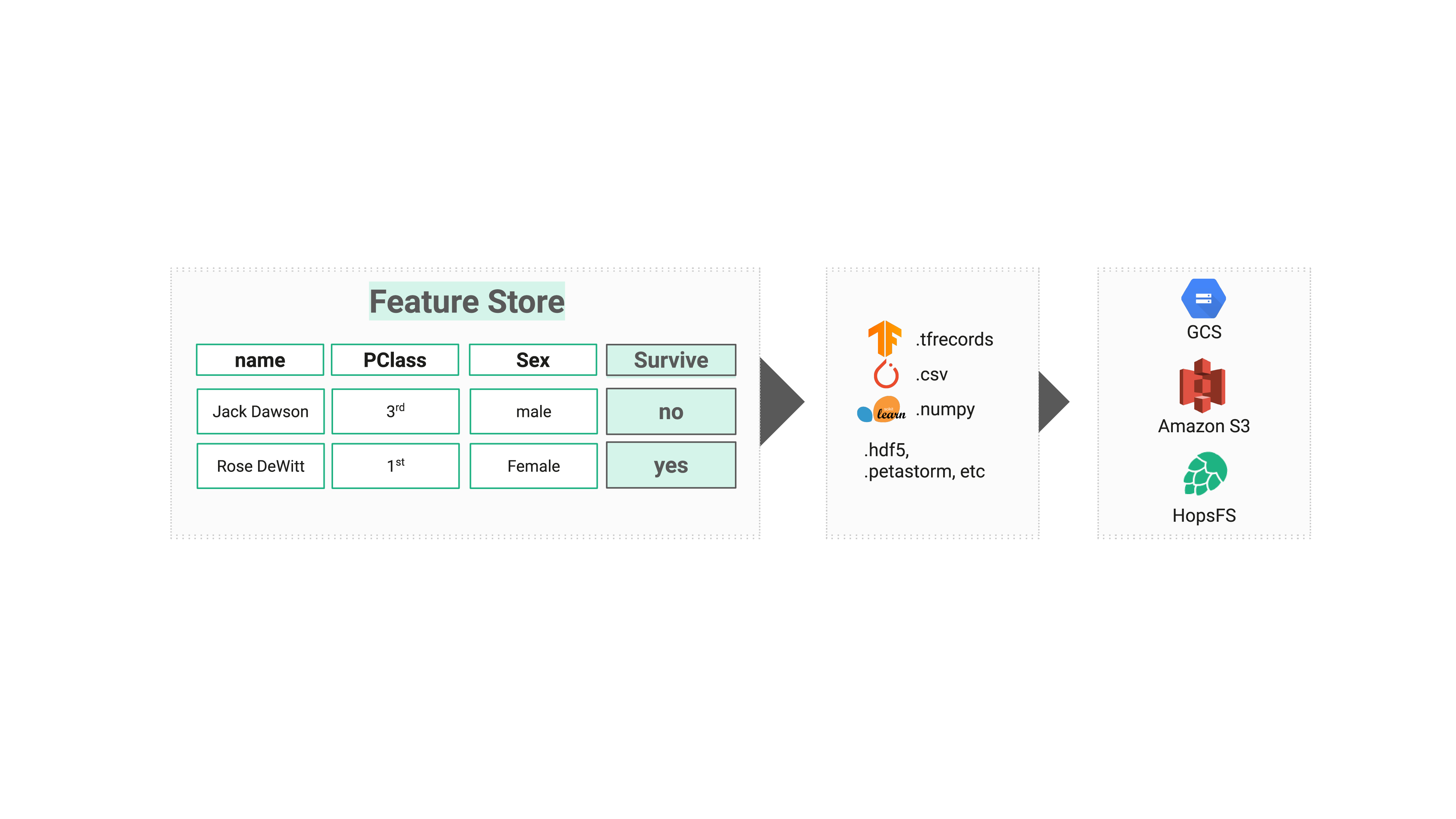
The Hopsworks Feature Store is a warehouse for storing reusable features for ML. It is designed to act as a cache for feature data. Feature data is the output of feature engineering, which transforms raw data from backend systems into features that can be used directly to train ML models. Data scientists interact with the feature store by browsing the available features, and, then, on finding the features they need to build their predictive model, they generate train/test data in the file format of their choice, on the storage platform of their choice. In the example shown in the Figure above, we can see we have 3 features and a target variable from the Titanic dataset, and we can then pick a file format (from the 10+ available file formats) and a target file system where the train/test data will be created. The Feature Store enables teams to easily collaborate on solving a problem by easily trying out solutions in different frameworks using different approaches (for example, deep learning on TensorFlow and PyTorch, and decision trees on Scikit-Learn) without the effort of converting the train/test data into the most efficient, easy-to-use file format for the respective framework.
File Formats Examples in Hopsworks
Hopsworks provides HopsFS (a next-generation HDFS file system) as its default distributed file system. HopsFS is a great distributed file system for machine learning due to its high throughput and low latency as well as widespread native HDFS readers in popular frameworks for ML: Spark, TensorFlow, Pandas (Scikit-Learn), and PyTorch (through petastorm).
PySpark
File formats: .csv, .parquet, .orc, .json, .avro, .petastorm
Data sources: local filesystem, HDFS , S3
Model serving file formats: .zip (MLeap)
Columnar file formats work better with PySpark (.parquet, .orc, .petastorm) as they compress better, are splittable, and support reading selective reading of columns (only those columns specified will be read from files on disk). Avro files are frequently used when you need to write fast with PySpark, as they are row-oriented and splittable. PySpark can read files from the local filesystem, HDFS, and S3 data sources.
Pandas/Scikit-Learn
File formats: .csv, .npy, .parquet, .h5, .json, .xlsx
Data sources: local filesystem, HDFS , S3
Model serving file formats: .pkl
Pandas can read files natively in .csv, .parquet, .hdf5, .json, .xlsx, and also from SQL sources. Pandas can read files from the local filesystem, HDFS, S3, http, and ftp data sources. In Hopsworks, you can read files in HopsFS using Panda’s native HDFS reader with a helper class:

TensorFlow/Keras
File formats: .csv, .npy, .tfrecords, .petastorm
Data sources: local filesystem, HDFS , S3
Model serving file formats: .pb
The native file format for Tensorflow is .tfrecords, and if your Dataset is not huge and you do not need to read only a subset of columns from the dataset, then it is our recommended file format. If, however, you only want to read a subset of columns (a projection in database terminology) from the dataset, then .petastorm is the file format to use. TensorFlow can read files from the local filesystem, HDFS, and S3 data sources.

Open Example TensorFlow Notebook
PyTorch
Training File formats: .csv, .npy, .petastorm
Data sources: local filesystem, HDFS ( petastorm), S3
Model serving file formats: .pt
PyTorch is tightly integrated with Numpy, and .npy is the native file format for PyTorch. However, np.load() does not work with HopsFS natively, so you have to use a wrapper function that we include in our library that first materializes the data from HopsFS to the local filesystem before reading it in as a numpy array. If you have large datasets, we recommend using .petastorm, which works natively with PyTorch through its own reader.

Numpy/Scikit-Learn
File formats: .npy
Data sources: local filesystem
Model serving file formats: .pkl
The native data format for Scikit-Learn is numeric data, and is most commonly stored as numpy arrays or pandas DataFrames (convertible to numpy arrays). PyTorch also builds directly on numpy arrays. As such, .npy is a popular file format for training data with Scikit-Learn. In Hopsworks, we provide a numpy_helper to read .npy files from HopsFS.
