Hopsworks Feature Store for AWS SageMaker
Integrate AWS SageMaker with Hopsworks to manage, discover and use features for creating training datasets and for serving features to operational models.

Feature stores are key components in enterprises’ machine learning/artificial intelligence architectures. In previous blog posts (Introduction to feature store, MLOps with a feature store, and Hopsworks Feature Store for Databricks) we focused on describing the key concepts and building blocks of the Hopsworks Feature Store. In this blog post we are going to focus on how to integrate AWS SageMaker with Hopsworks. Hopsworks is available on AWS as either a SaaS platform or as a custom Enterprise platform.
While Hopsworks provides all the tools to design and operate pipelines that go from raw data to serving models in production, it is also a modular platform. In particular, the Hopsworks Feature Store can be used as a standalone feature store by data science platforms, such as AWS SageMaker or Databricks. It offers AWS Sagemaker users a centralized platform to manage, discover, and use features - for both creating training datasets and for serving features to operational models. In this blog, we will cover how AWS Sagemaker users can, from within the comfort of their Jupyter notebook, perform exploratory data analysis with the feature store, discovering available features, and join features together to create train/test datasets - all from the comfort of your existing SageMaker notebook instance.
Exploratory Data Analysis with a Feature Store
Exploratory data analysis (EDA) is a key component of every data scientists’ job. The Hopsworks Feature Store provides data scientists with a repository of features ready to be used for training models. Data scientists can browse the available features, understand the features by inspecting their metadata, investigate pre-computed feature statistics, and preview sample feature values. These are typical steps a data scientist takes to determine if a feature is a good fit for a specific model. With the Hopsworks AWS SageMaker integration, data scientists can perform these steps in a Jupyter notebook by making feature store API calls in Python.
In Hopsworks, features are organized into groups of related features in what is called a Feature Group. Exploration usually starts at the feature group level, by listing all the available feature groups in the feature store:
The following step allows data scientists to understand which individual features are available in a given feature group, and it returns the first five rows (a data sample):
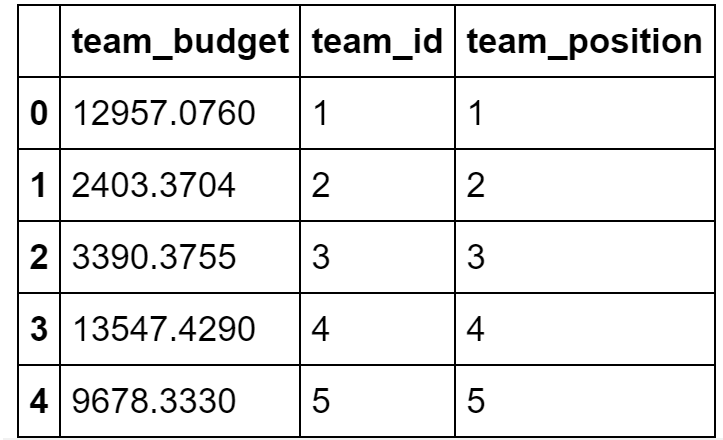
The above API call will send a request to the Hopsworks Feature Store and return the result to the user in a Pandas dataframe df.
Individual features are the building blocks of the Hopsworks feature store. From SageMaker, data scientists can join features together and visualize them. As joining features is performed in Spark and SageMaker only provides a Python kernel, the join is executed on the Hopsworks Feature Store and the result returned to the user in a Pandas dataframe df. The complexity of the request is hidden behind the API call.
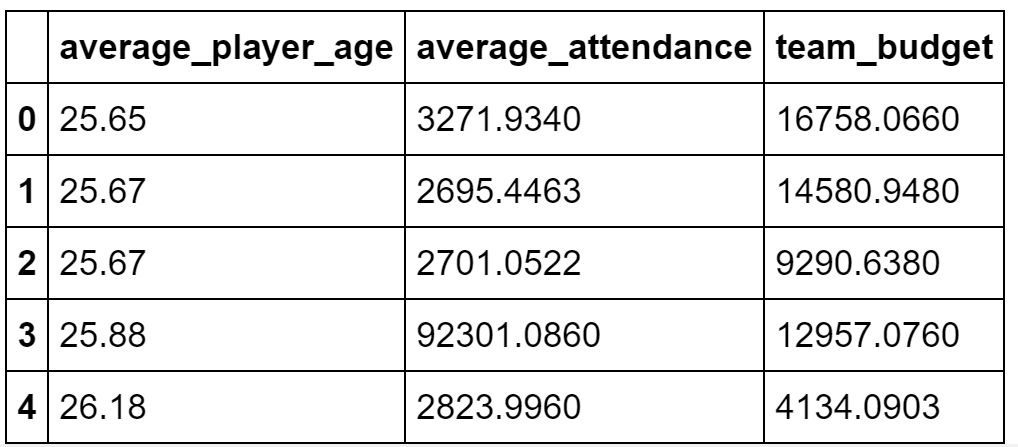
Statistics and data visualization help to give an understanding of the data. Hopsworks allow users to compute statistics such as the distribution of feature values, feature correlation within a feature group, and descriptive statistics (Min, Max, Averages, Counts) on the different features.
The statistics are shown in the Hopsworks Feature Store UI, but they are also available from a notebook in SageMaker:
Generate train/test datasets
Once you have explored the feature store and identified which features you need for your model, you can create a training dataset (the train and test data you need to train and evaluate a model, respectively). A training dataset is a materialization of multiple features joined together, potentially coming from different feature groups. The joining of features together on-demand, enables data scientists to reuse the same features in many different training datasets. Once features have been joined together into a dataframe, they can be stored in a ML framework friendly file format on a storage platform of choice, such as S3. For example, if you are training a TensorFlow model, you may decide to store your training dataset in TensorFlow’s native TFRecord file format, in a bucket on S3, s3_bucket.
In the above example, the feature store joins the list of features together and saves the result in files in TFRecord format in a S3 bucket. The S3 bucket needs to be defined inside a connector in the Hopsworks Feature Store. In practice, what happens is that the SageMaker notebook asks the Hopsworks Feature Store to start a Spark job to produce the training dataset. When the job has completed on Hopsworks, you’ll be able to use the training dataset, typically in a different notebook, to train your model.
Get Started
Before you begin, make sure you have started a Hopsworks cluster using our platform. The Hopsworks - SageMaker integration is an enterprise only feature and Hopsworks gives you access to it. The first time you use the Hopsworks - SageMaker integration, there are a few simple steps that you need to perform to configure your SageMaker environment.
API Key
From SageMaker you need to be able to authenticate and interact with the Hopsworks Feature Store. As such you need to get an API key from Hopsworks. You can generate an API key by clicking on your username in the top right of the window, click on Settings and select API KEY.
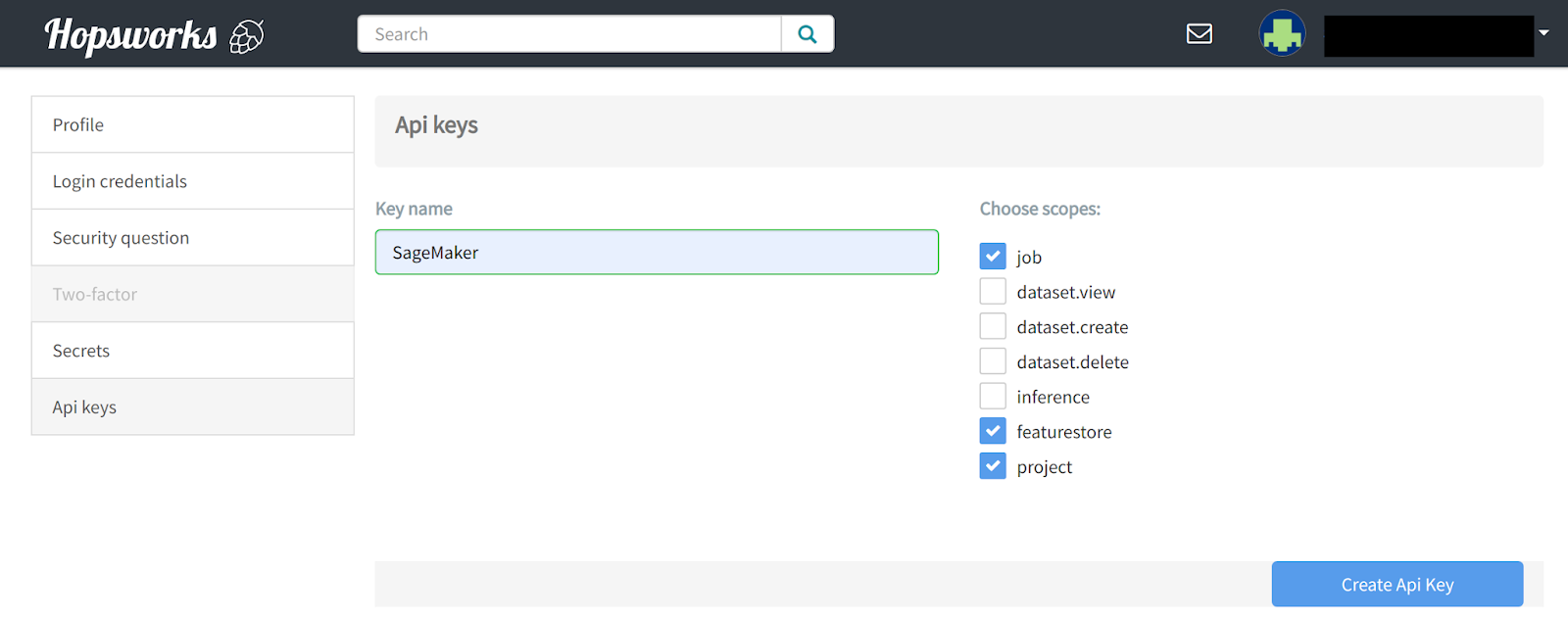
You need to choose the featurestore, jobs, and project scopes when creating your API key. You should upload the API key as a secret on the AWS Secrets Manager service. The Hopsworks SageMaker integration also supports reading the API key from the AWS Parameter Store or a local file. The documentation covers the setup for all the cases.
To use the AWS Secrets Manager, you should first find the IAM Role of your SageMaker notebook - in this case it is AmazonSageMaker-ExecutionRole-20190511T072435.
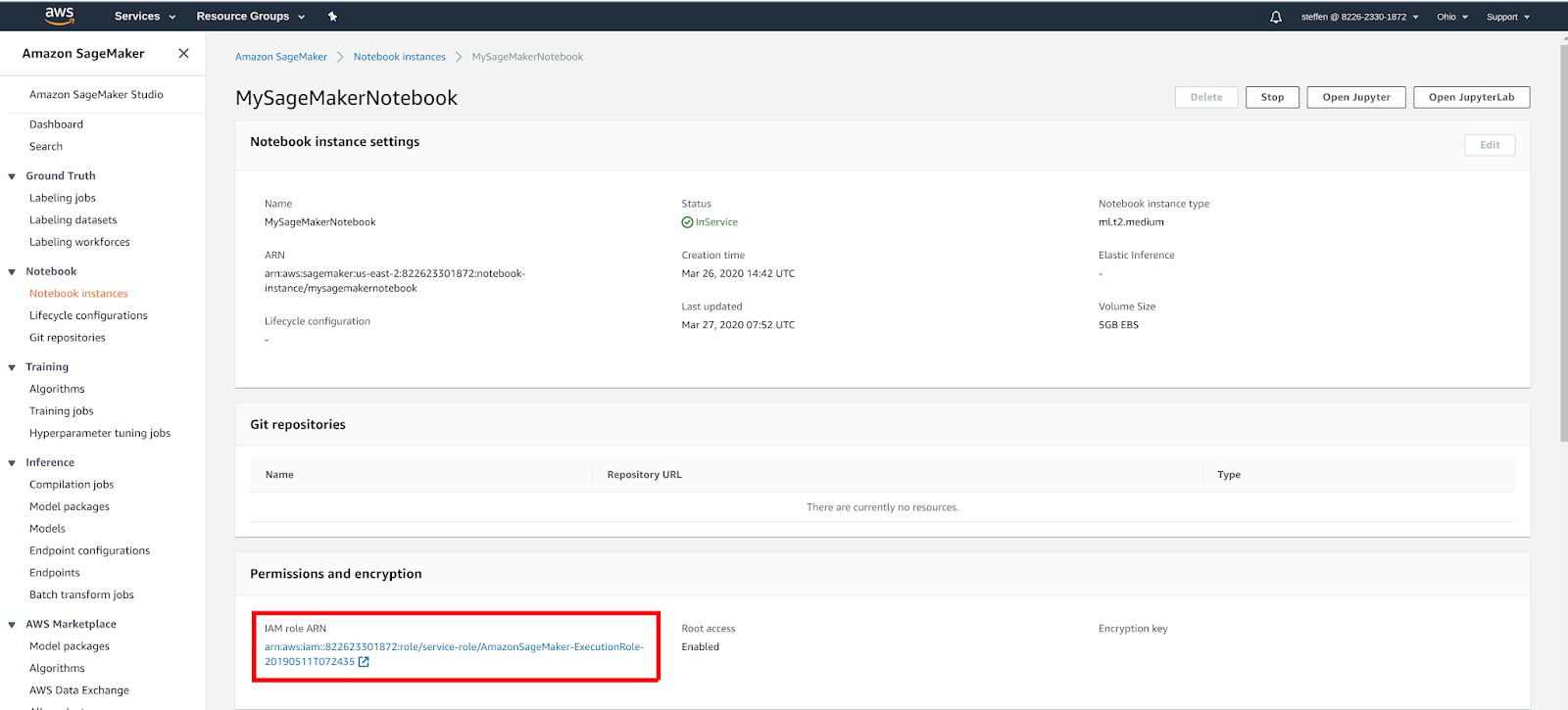
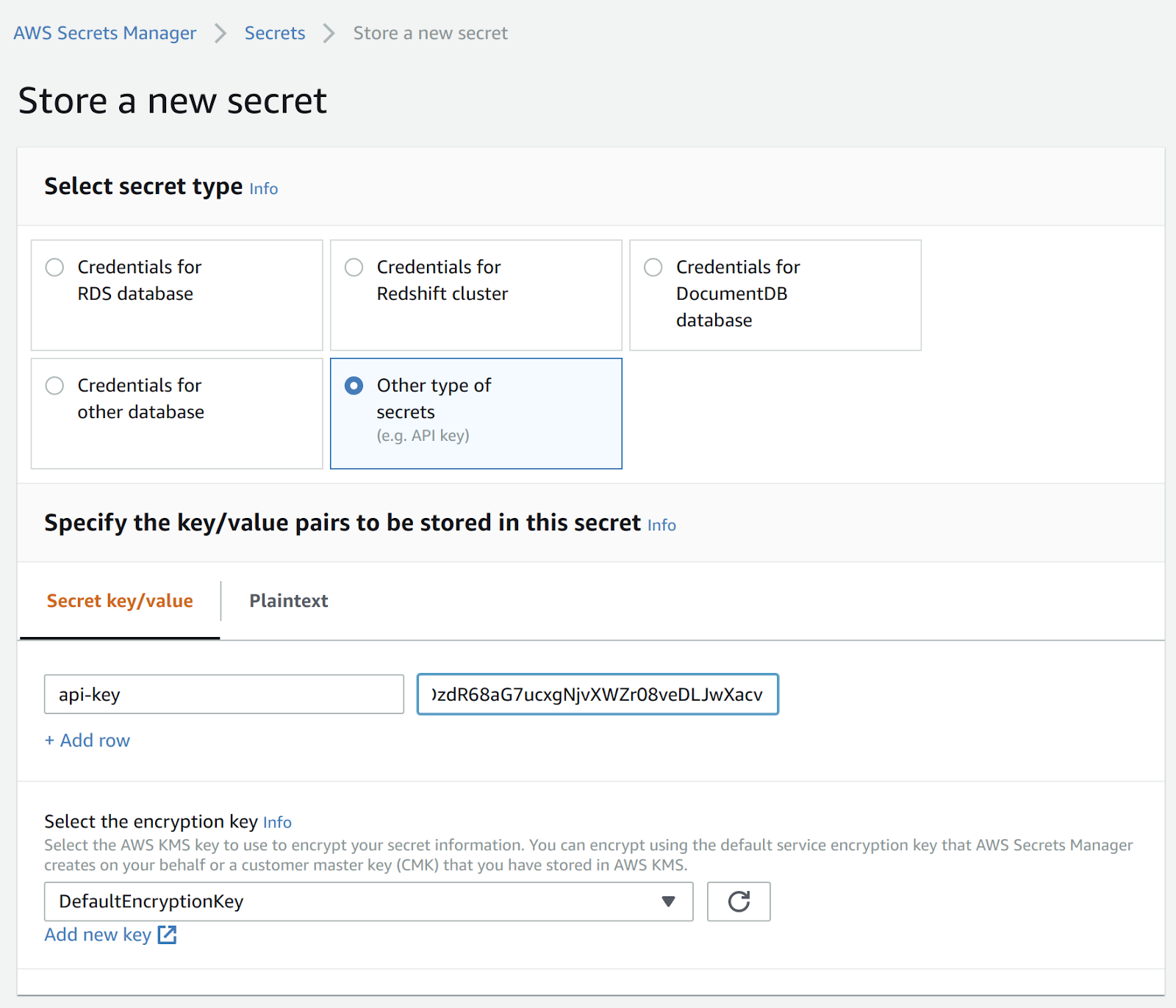
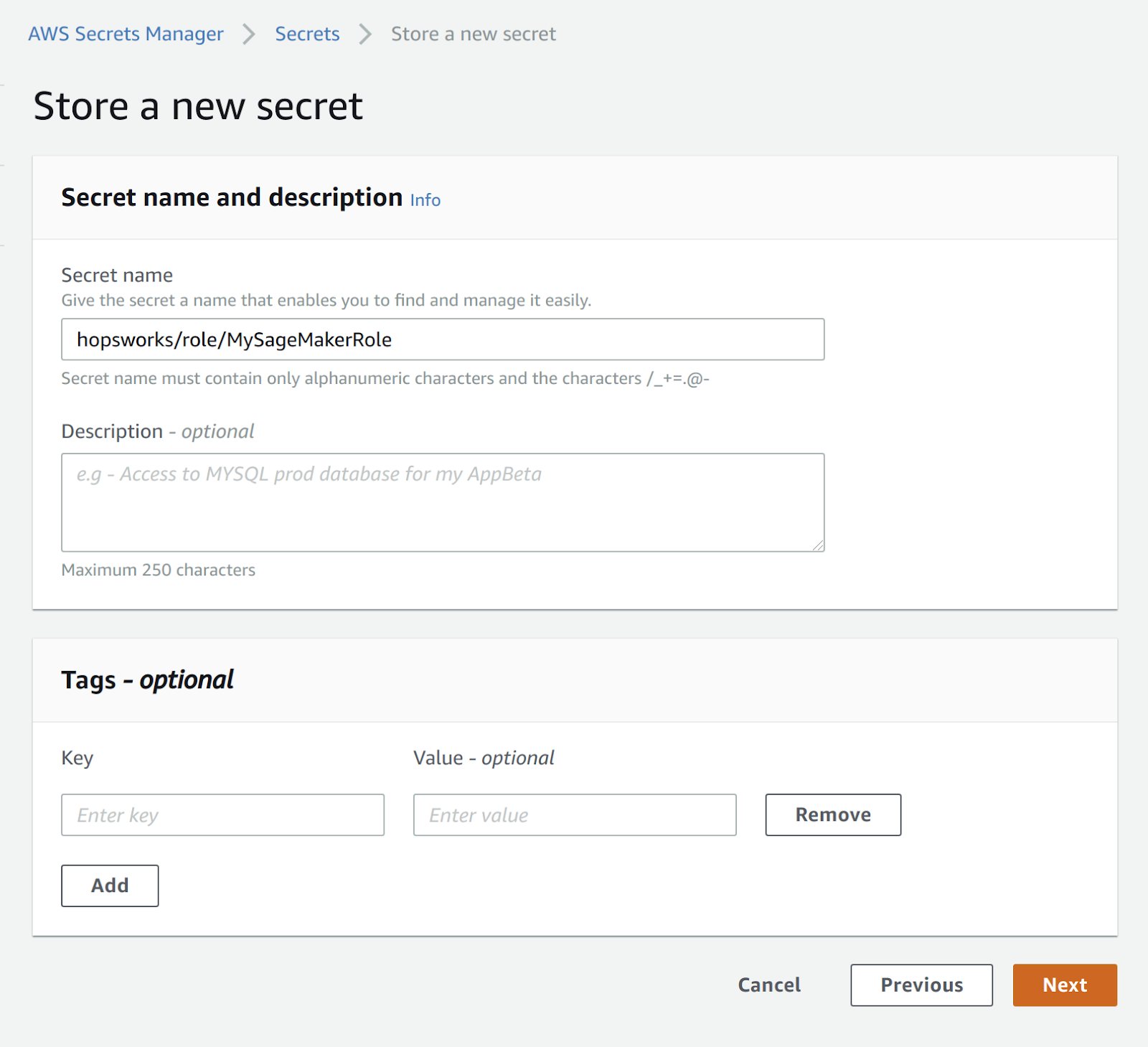
Create a new secret called hopsworks/role/[MY_SAGEMAKER_ROLE] where the [MY_SAGEMAKER_ROLE] is the same name as the IAM Role you retrieved in the previous step. The key should be api-key and the value you should be the API Key you copied from Hopsworks in the first step.
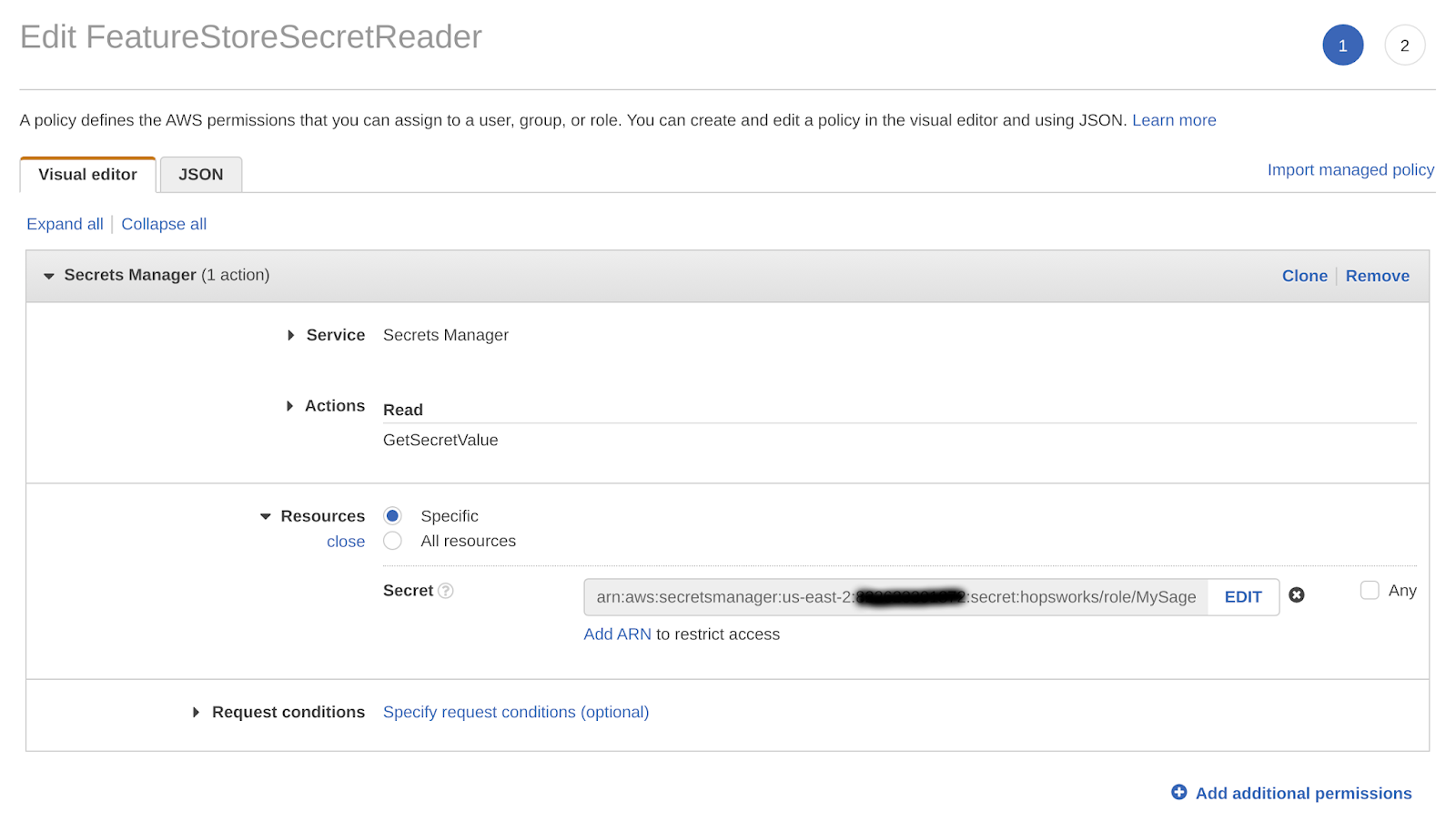
Finally we need to give the IAM role of the SageMaker notebook permissions to read the secret we just created. In the AWS Management Console, go to IAM, select Roles and then the role that is used when creating SageMaker notebook instances. Select Add inline policy. Choose Secrets Manager as service, expand the Read access level and check GetSecretValue. Expand Resources and select Add ARN. Paste the ARN of the secret created in the previous step with the AWS Secrets Manager. Click on Review, give the policy a name und click on Create policy.
After this step, your Sagemaker notebook when run as the above IAM Role will have permission to read the Hopsworks API key from the Secrets Manager service.
Hopsworks-cloud-sdk
With the API key configured correctly, in your AWS Sagemaker Jupyter notebook, you should be able to install the hopsworks-cloud-sdk library using PIP:
Make sure that the hopsworks-cloud-sdk library version matches the installed version of Hopsworks.
Establish the first connection
With the API Key configured and the library installed, you should be now able to establish a connection to the feature store, and start using the Hopsworks - AWS SageMaker integration.
Try it out now with Hopsworks.ai
You can now try out the Hopsworks Feature Store and the SageMaker integration by starting an instance on Hopsworks and running this example Jupyter notebook on your SageMaker instance.
The Hopsworks Community is also available if you need help with your setup.
Upcoming improvements
Several exciting improvements are coming to the Hopsworks feature store APIs in the next couple of weeks. The most important one is a more expressive API for joining features together. The new API is heavily inspired by Pandas dataframe joining and should make life easier for data scientists. Moreover, we are adding the capability to register a small Pandas dataframe as a feature group directly from a SageMaker notebook. While we still encourage you to use a Spark environment to engineer complex features with lots of data, it will also be possible to ingest Pandas dataframes as feature groups without the need for PySpark.