Bring Your Own Kafka Cluster to Hopsworks
A tutorial of how to use our latest Bring Your Own Kafka (BYOK) capability in Hopsworks. It allows you to connect your existing Kafka clusters to your Hopsworks cluster.

Introduction
Hopsworks version 3.4 introduces a new capability of using external Kafka clusters for data ingestion into feature groups. This is a step that is aimed at allowing users to bring their own components, making Hopsworks as a whole more modular platform. In the future, the Hopsworks team is planning on introducing even more such changes to make the feature store more adaptable to each user's needs. The end goal of this endeavor is to encourage tighter integration of the Hopsworks feature store with existing data pipelines.
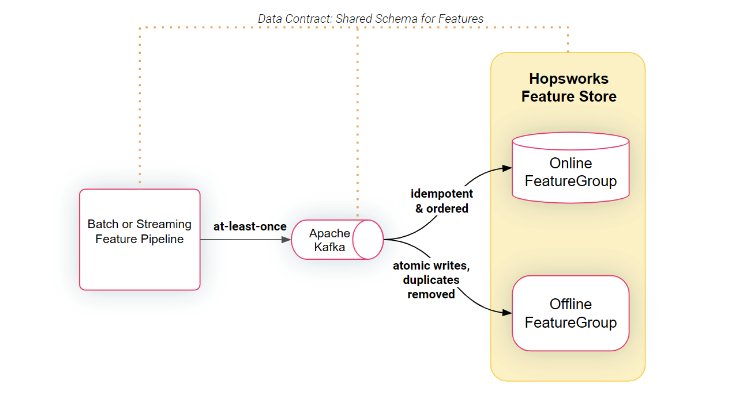
Figure 1: Shared Schema for Features
Hopsworks uses Kafka to transparently replicate data in parallel to both online and offline feature stores. Kafka provides at-least-once replication semantics, meaning duplicate entries could be created. Hopsworks uses idempotent updates to RonDB and ACID updates with Apache Hudi to ensure correct data in the online and offline stores, respectively.
Another new capability added in this release is the ability to have feature groups share Kafka topics. Previously, each feature group in Hopsworks had its own dedicated Kafka topic with the Kafka topic’s schema matching the feature group tables’ schemas - ensuring end-to-end data contracts. Now it is possible to define the project's default topic and also have more granular control over which topic a specific feature group will use - the default topic or its own topic. This functionality is useful in Enterprises with centrally managed Kafka clusters, where creating a Kafka topic might require raising a ticket to the Kafka team.
However, due to it being a new feature there currently are some limitations:
- When using a Kafka cluster that is not managed by Hopsworks the topic management is the responsibility of the user.
- At this time BYOK does not allow for model serving using external Kafka clusters.
- Feature group topic names can’t be changed after they are created.
In this blog, we will learn about how to connect to a Confluent cloud Kafka cluster, provide basic examples of how it could be used for data ingestion, and finally summarize the nuances of using an external Kafka cluster over a Hopsworks-managed one.
Prerequisites
To follow this tutorial you should have an instance of Hopsworks version 3.4 or above and be the Data Owner/Author of a project. Furthermore, to use external Kafka clusters, the user has to configure the Hopsworks cluster to enable it. This can be done by setting the ‘enable_bring_your_own_kafka’ configuration value to ‘true’ (As seen in the image).
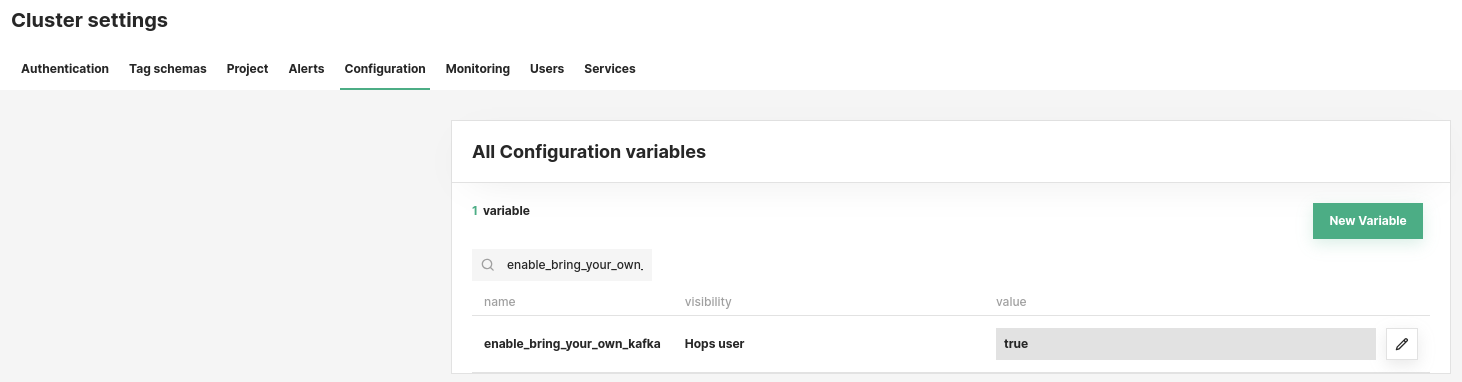
Figure 2: Hopsworks Cluster Settings
Additionally, you should have a cluster set up in the Confluent cloud, in this tutorial it functions as your external Kafka service.
Setting up the Kafka clusters
Hopsworks manages the connection to external Kafka clusters through storage connectors. Therefore, the following steps show you how to retrieve the connection information from Confluent and provide it to your Hopsworks project.
Get connection information from Confluent cloud
In the Confluent cloud get the Kafka configuration information by following the steps below:
‘Clients’ -> ‘New client’ -> ‘Java’ -> ‘Copy the configuration snippet for your clients’. Make sure to specify CLUSTER_API_KEY and CLUSTER_API_SECRET, to retrieve this information click on the ‘Create Kafka cluster API key’ button.
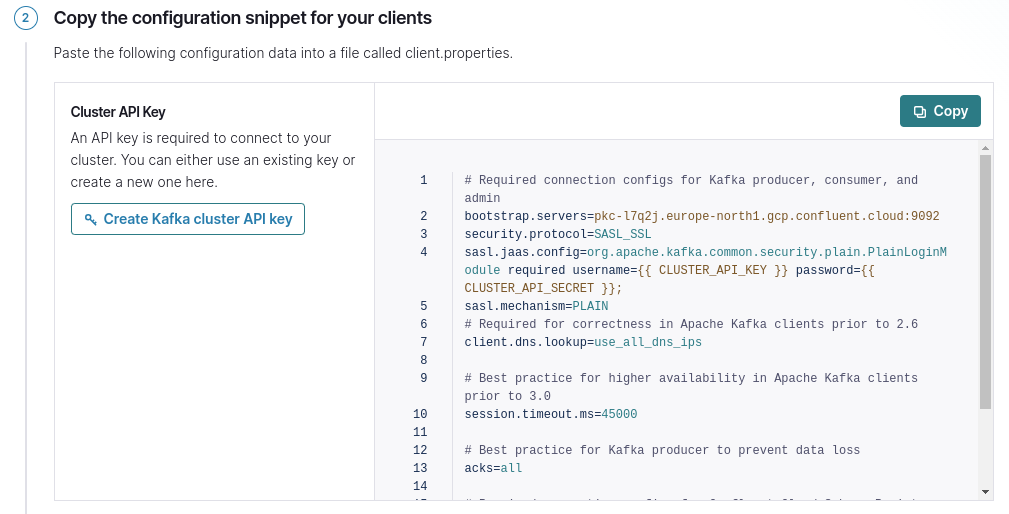
Figure 3: Confluent connection details
Defining the connection to the Kafka cluster using a Hopsworks storage connector
Next, in Hopsworks select a project where you want to connect to the Confluent kafka cluster and create a new storage connector by entering the configuration details from the previous step and setting the connector name to ‘kafka_connector’. Note that when BYOK is enabled, Hopsworks looks for a connector with the name entered, so make sure not to misspell it. This storage connector will be used by everyone working on the project where it is defined. If the connector is undefined, Hopsworks-managed Kafka will be used by default.
After entering the connection information the connector should look something like this.
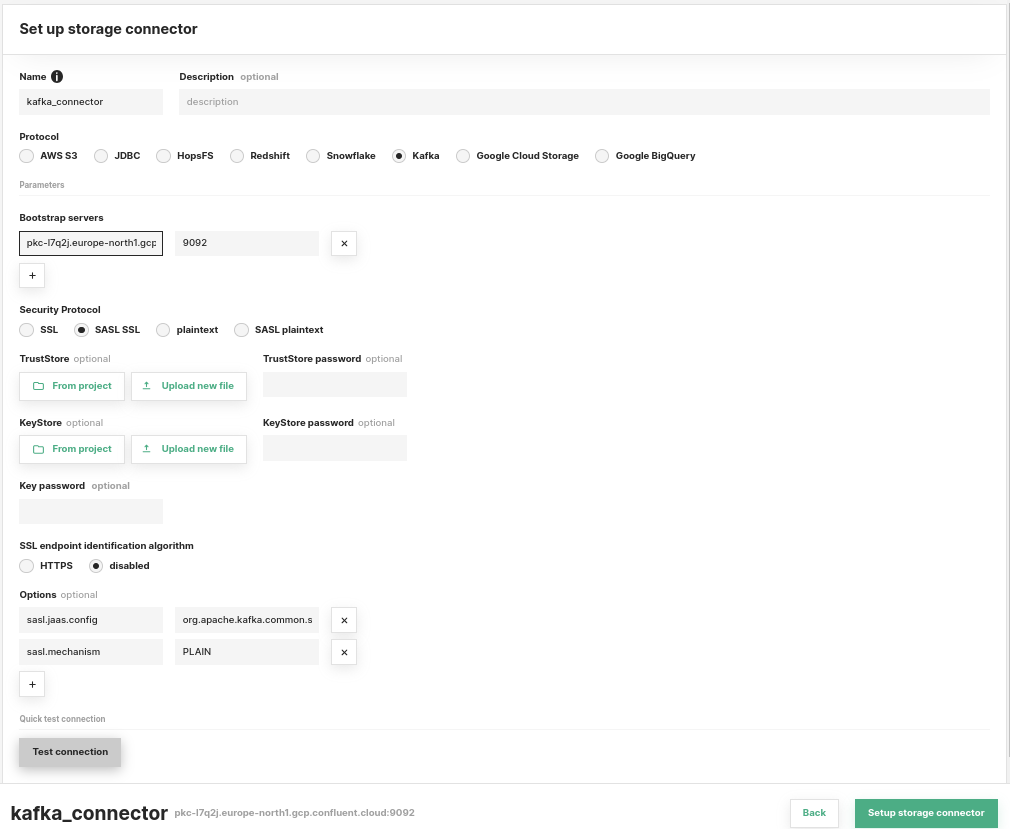
Figure 4: Set up storage connector in Hopsworks
Finally, save the changes and that is it for the setup. If at a later time, you want to alter any of the Kafka connector details, you can do this by simply navigating to the storage connector and updating it.
Usage
The usage of externally managed Kafka is similar to Hopsworks managed one. The biggest difference is that Kafka topics have to be managed manually by the user. Therefore, before creating a feature group you begin by setting up a topic that will be used by it.
Create the topic in Confluent cloud
The creation of topics can be carried out by going to your Confluent cluster, navigating to ‘Topics’, clicking on ‘New topic’, specifying the ‘Topic name’ (for example setting it to: ‘my_topic’), and finally pressing the ‘Create with defaults’ button.
Figure 5: Confluent new topic
Using external Kafka when inserting into a Hopsworks feature group
Subsequently, you can create a new feature group in Hopsworks by specifying the topic name that should be used. In this example, we will create a simple streaming feature group and insert a couple of rows to test that everything works (note that the 'topic_name' parameter value is ‘my_topic’, which is the topic that we created in Confluent).
Let's begin by starting a Jupyter notebook with the following code.
[Code example for creating streaming FG and inserting into it some data]
After executing the code shown above it should be possible to read the data that has been written by running the code shown below.
[Code example for reading from stream FG]
Additionally, you can navigate to the created topic in the Confluent cloud and see the associated metrics, such as produced messages.
Additional insights
Starting from Hopsworks 3.4 if the feature group 'topic_name' parameter is left undefined when creating the feature group, then it will default to using a project-wide topic. By default, this topic is called the same way as the project name, but for online-enabled feature groups this name has the suffix ‘_onlinefs’.
The project-wide topic functions great for use cases involving little to no overlap when producing data. However, concurrently inserting into multiple stream feature groups could cause write amplification when writing to the offline store. Therefore, it is advised to utilize dedicated feature group topics when ingestions overlap or there is a large frequently running insertion into a specific feature group.
The OnlineFS Connector service is synchronizing data in Kafka with the online feature store. By default, OnlineFS subscribes to topics with the suffix ‘_onlinefs’, but it is possible to reconfigure it to subscribe to different patterns or specify topics.
Summary
In this blog post, we have seen how easy it is to get started using your own Kafka clusters in Hopsworks. This functionality allows users to have more control over their data when ingesting information into the feature store. Similarly, it reduces your operational overhead for Hopsworks if you already have your own managed Kafka clusters.