The Enterprise Journey to introducing a Software Factory for AI Systems
The Journey from Artisanal ML to ML Infrastructure
In this article we describe the software factory approach to building and maintaining AI systems.

The need for a Software Factory for AI Systems
The largest and most profitable software companies are generating huge amounts of value through AI, while the (silent) majority of Enterprises are not. That is a commonly heard refrain with more than a grain of truth to it. The companies that deliver huge value through applied AI (from Facebook to Google to Salesforce to Github) have built their own software factories for building and maintaining AI systems. They do not follow the decentralized approach, see Figure 1, where many parallel organic initiatives at an organization deliver varied results.
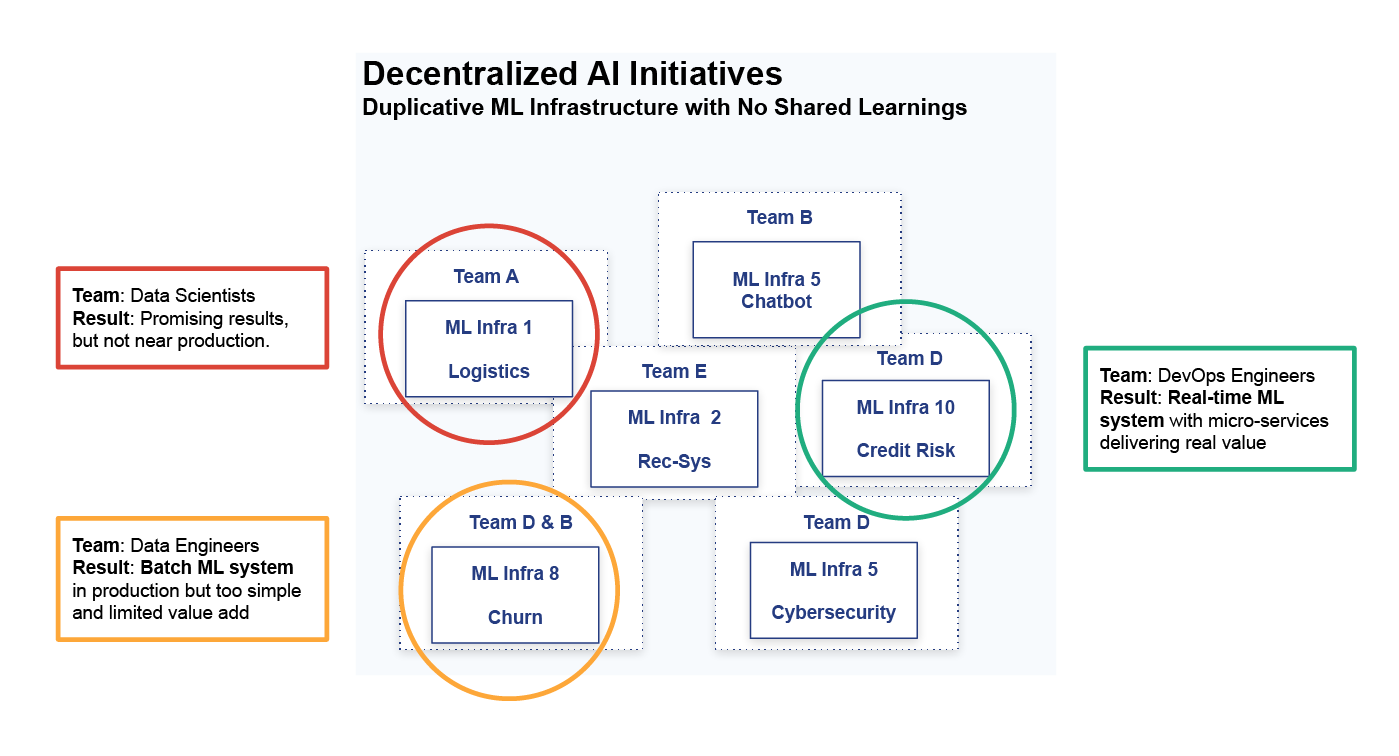
Figure 1. Without a centralized AI platform, different lines of business develop their own AI-powered products and services using their own systems, tools, and processes.
However, many organizations start their AI journey with no centralized policy or platform team for AI system development, with the result that many teams take local initiatives to add AI to their products or services, using their own choice of tools and platforms. In my experience, from working with companies that are at different points in their AI journey, it is often Team D from Figure 1 who have a large voice in the future of AI at the company. They are the ‘hacker’ team that have managed to successfully build an AI powered product that is delivering value today. In contrast to the data science dominated Team A, who lacked the software infrastructure skills to productionize their promising models, the more experienced software developers in Team D concentrated on starting small, getting a working ML system first, and only later refining the AI that powers their product. One lesson they learnt was that following a DevOps software development process worked for them. However, are the lessons learnt by Team D a blueprint for success in AI for the organization as a whole?
Brief History of Modular AI Systems
(Real-Time and Batch)
Team D successfully applied some established techniques for handling complexity when building software systems:
- decompose systems into smaller manageable modular components;
- design the modular components in such a way that they can be easily composed into a complete AI system;
Team D also did their homework on machine learning engineering. Some features needed to be precomputed and retrieved at runtime to hit their SLA, so they used a Postgres database to store and retrieve them and wrote a separate data pipeline for each model. They knew enough to avoid pitfalls such as skew between training and serving, so they logged all predictions to a single wide table and waited to collect enough training data. This one-big-table data model avoids data leakage that can arise when your data is spread across multiple tables and you need to perform a temporal Join across tables when creating training data.
Team A did not follow this approach as they did not have the software development skills to build the CI/CD pipelines, containerize the different modules in the ML system, and operate and instrument the microservice architecture used to deliver the operational ML system. So Team A just concentrated on making their models better, which ultimately did not deliver value to the business. Models stuck in notebooks add no value to the business.
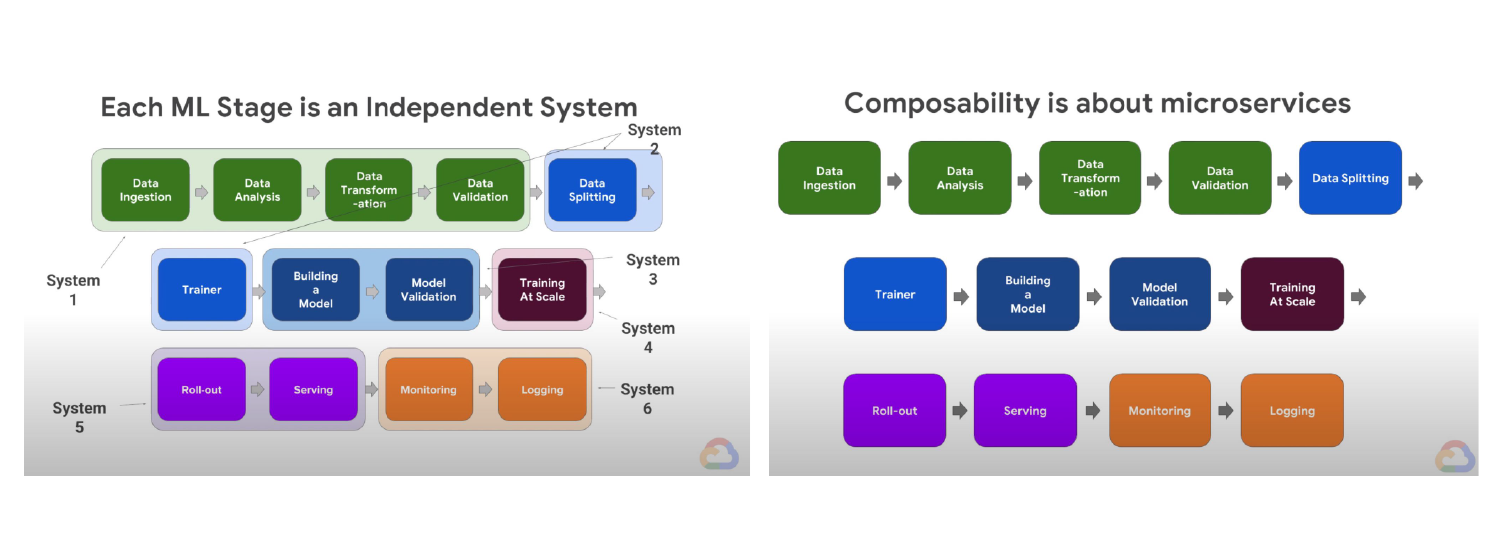
Figure 2. A composable real-time machine learning system can be built from separate independent microservices. Images from Lak Lakshmanan in Google Cloud
Team D later helped Team B (the marketing team with a data engineer) build a batch ML system that helped predict subscriber churn. For Team D, this was a more straightforward project, as it was a single monolithic batch ML system. Their ML system as a dataflow program - a directed acyclic graph of steps - executed by an orchestrator, see Figure 3. One difficult challenge they faced was in creating training data. The data was spread over many tables - user engagement, marketing actions, session data, and so on. Team D realized temporal joins would be needed to create rich training data, and there was a risk of data leakage if they didn’t get them right. So being the good engineers they are, they followed the KISS principle and used only the user engagement data for their model, as they hypothesized this data had the most predictive power for subscriber churn. Unfortunately, neither Team D nor Team B were experts at data science, and the model they built was too trivial (it had low predictive power) and ultimately did not significantly impact the bottom line. They also skipped on monitoring their features/predictions for drift, instead committing to retraining the model every 6 months. But their model made it to production - in contrast to our Team A of data scientists. Team A, in contrast, made fun of the churn model when they found out about it.
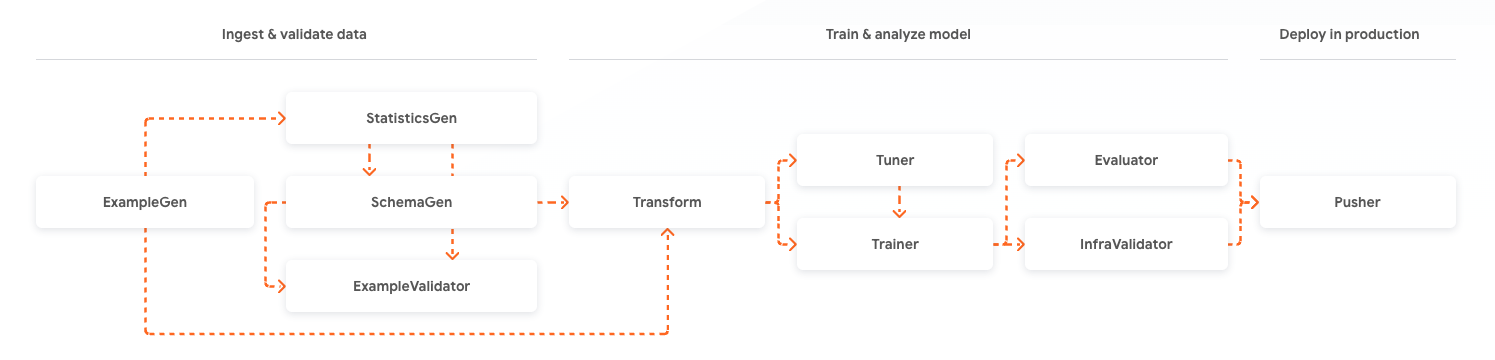
Figure 3. A batch ML system can be built as a monolithic Directed Acyclic Graph (DAG) of independent steps executed by an orchestration engine. Image source: Google TFX Project.
As you can see, the software architectures of the real-time ML system (Figure 2) and batch ML system (Figure 3) are radically different. Team D has some crack developers who were comfortable switching development paradigms and tooling, and pulled it off for real-time and got something working for batch. So what did the organization learn from its decentralized ML initiatives?
Team D drew conclusions that real-time AI systems could be built as microservices architectures and batch AI systems should be orchestrated DAGs. However, there are some issues. While the microservices architecture is modular, it is not easy to compose AI systems as graphs of independent microservices. The subsystems are tightly coupled and need to be always-on. If a microservice is “down”, it can lead to the entire ML system being down. The call depth for microservices can be deep and you need great observability tools for tracing calls and monitoring services. They couldn’t use serverless functions to implement microservices due to high latencies that break SLAs during cold-starts. If they hadn’t had the same low latency SLA, they would have looked at designing their microservices as loosely coupled serverless functions that communicate by passing events through a serverless database (like DynamoDB) or a shared event bus, such as Kafka or AWS Kinesis or GCP PubSub.
Then, there is the cost. Deploying a new microservice is not trivial for the Data Science team. You need to build your container, set up a CI/CD platform to deploy containers in a runtime (like Kubernetes) and connect your microservices to the other microservices and existing services. You need to develop your microservices so that they correctly perform service discovery and handle service connection/disconnection events correctly. This is all hard work, and definitely not the work of data scientists, or even many ML engineers. That is a common reason teams often “start with batch AI systems”. Only the highest value real-time AI systems get deployed first. Then, making those real-time AI systems highly available and reusing assets created between different real-time AI systems are just roadmap items for even Team D.
MLOps Infrastructure
So, what should the organization do now? Should it just work on batch AI systems and only in exceptional cases approve real-time AI systems? Is there an alternative? How do the hyperscale AI companies spit out new AI systems at low cost and with high quality? Could we do the same? The answer is that the hyperscalers have all built their own ML infrastructure to support AI systems, see Figure 3. Most of them (AWS, Databricks, Snowflake, Twitter, Spotify, Uber, WeChat) have presented their ML infrastructure at the feature store summit (videos available). All of them have implemented Feature Store-based data architectures and a model management infrastructure to solve most of the problems identified earlier:
- decompose the problem of building AI systems into modular ML pipelines that are easily composed together into a system using the shared data layer;
- decouple ML pipelines enabling independent scheduling and the use of the best technology for each ML pipeline;
- support for creating point-in-time consistent training data;
- low-latency access to precomputed features for real-time ML systems;
- real-time features computed using data only available at request-time;
- data validation for feature pipelines, ensuring no garbage-in;
- unified batch and real-time support for both feature monitoring and model monitoring;
- out-of-the-box observability and governance, using versioning, tagging, search and lineage services;
- high availability and enterprise level security.
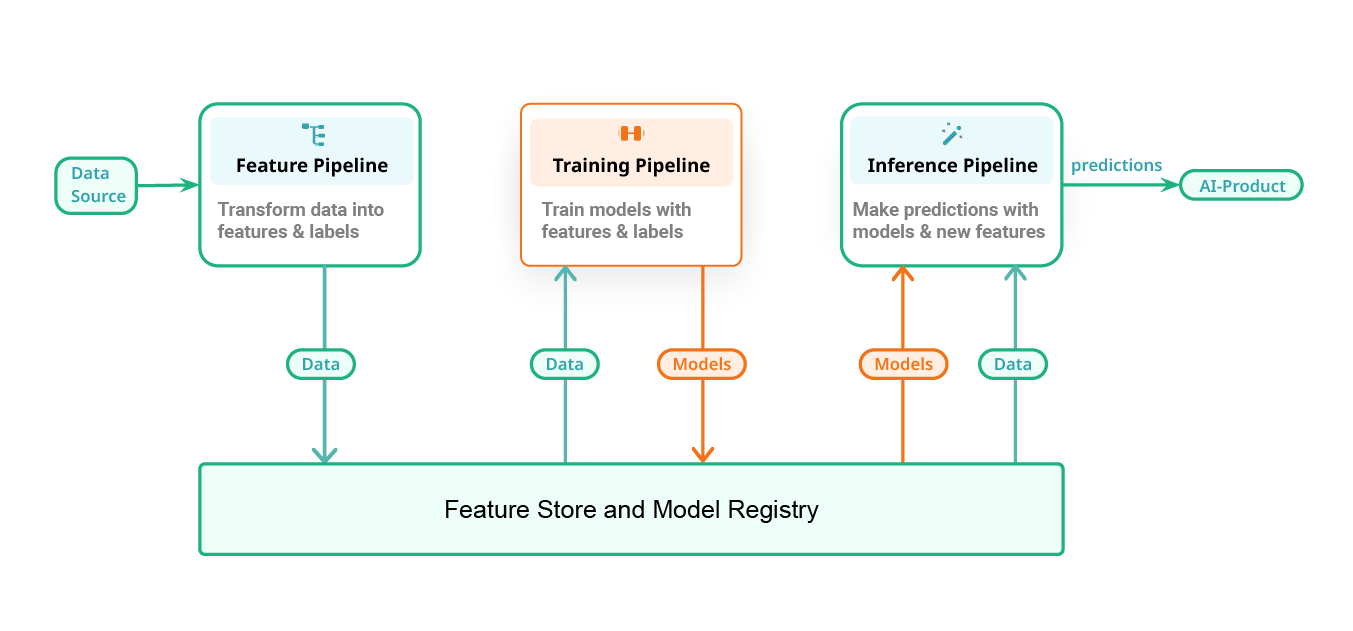
Figure 3. Feature Pipelines, Training Pipelines, Inference Pipelines are the independent ML Pipelines that together make up a ML System
In a previous blog, and shown in Figure 3, we outlined what these ML platforms have in common. AI systems consist of primarily three classes of ML pipelines (feature pipelines , training pipelines, and inference pipelines) that communicate via a shared data layer, consisting of a feature store and a model registry. Somebody in Team D happened to read that blog entry, and designed Table 1, comparing the different approaches to building AI systems.
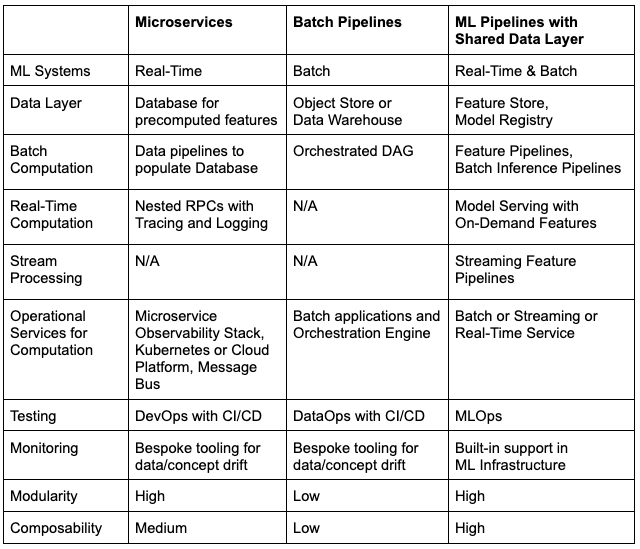
Table 1: Team D summarized the different approaches to building AI systems. Real-time AI systems as microservices. Batch AI systems as orchestrated DAGs. A unified ML system architecture based around feature/training/inference pipelines and a shared data layer.
Microservices are not, however, as composable as ML pipelines. ML Pipelines can be scheduled to run as batch systems or microservices (always-on) or stream processing systems. Upgrading versions is straightforward - you do not need to stop upstream and downstream clients while upgrading.
When planning their AI strategy, the executive team needed a summary of Table 1, so Team D developed Table 2.
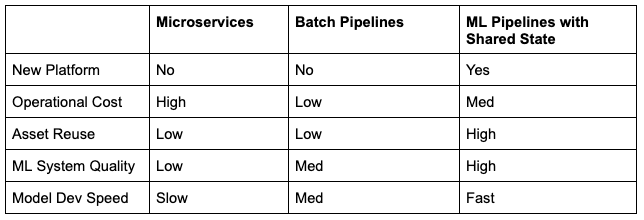
Table 2: Relative economic benefits of the different architectural approaches to building AI systems
So, after a long journey, developing and deploying both batch AI systems and real-time AI systems, our organization takes the decision to move towards the software factory approach for building AI systems, using ML pipelines with shared ML infrastructure (feature store, model registry, experiment tracking, model serving). They want to have the same infrastructure as the Hyperscale AI companies so that AI can become a core part of their value proposition.
Build or Buy the MLOps Infrastructure?
The next question facing our organization is whether to build or buy the ML infrastructure. This is not a simple question, nor is it something that is unique to organizations that are considering their alternatives with regards to any kind of data infrastructure. Given enough time and resources, large engineering organizations can pull off any infrastructure component themselves, as has been elaborately proven by many of the hyperscalers mentioned above.
Figure 4. The Hopsworks platform provides all of the major ML infrastructure needed for your AI software factory: a feature store, managed ML pipelines, a model registry, and model serving (KServe).
However, for the typical enterprise, considering their options with regards to their MLOps infrastructure landscape, this is not a straightforward question. In fact, it is complicated by the very nature of the problem:
- On the one hand, we want to move fast, be nimble and lean, and prove value quickly in the early parts of the machine learning and AI journey. That will often mean taking shortcuts, and duct-taping infrastructure together - and that is fine in these early days.
- On the other hand, we want to get to production quickly, as soon as we have proven the value and as soon as we understand that the machine learning and AI initiative will be more than just an experiment.
This will greatly impact the timing and the balance of the build versus buy decision.
In this decision, different factors should be taken into account. However, it seems clear that they fall into three proverbial buckets:
- Strategic parameters, that have everything to do with the way that the organization and the project can deal with the manpower, competencies and costs associated with both the build or the buy decision.
- Technical parameters that concern the nature of a feature store architecture and the intricate complexities that come with this.
We will not discuss these parameters in this article here in detail, but will instead refer to this page on the Hopsworks website, which discusses this in greater detail. It should, of course be clear, that at Hopsworks we think of it as our everyday mission to make sure that you will not have to worry about this build versus buy decision, and that it would be all the more obvious that you can productively start using the Hopsworks platform as early as you want, whatever the use case of your project might be.
Summary
The typical Enterprise journey to creating value with AI involves decentralized experimentation, followed by first value-added services being built with bespoke solutions, to finally adopting a software factory approach to building and maintaining AI systems. The hyperscale AI companies built their own software factories, but the next wave of Enterprises should probably buy their ML infrastructure, as the cost and time-to-market trade-offs are now heavily in favor of buying.