Building a Cheque Fraud Detection and Explanation AI System using a fine-tuned LLM
The third edition of the LLM Makerspace dived into an example of an LLM system for detecting check fraud.

The third edition of the LLM Makerspace dived into an example of an LLM system for detecting check fraud.
So, what exactly are checks? They're essentially money transfers where you write the amount on a piece of paper and hand it over to someone. It's considered legal tender and payment for services. As an Anglo-Saxon myself from Ireland, I'm familiar with checks. Other countries like America still use them too, but much of the world has moved on. However, there are still plenty of people processing checks, especially in the financial industry and banks. They receive these physical pieces of paper daily and need to validate that they're not fraudulent. That's where LLMs come in handy, and we'll explore how to use them for this purpose.
If you want to start from the beginning, you can recap the previous editions of the LMM Makerspace on the Hopsworks YouTube channel. You can also read about the other AI systems we’ve built on our blog page:
- The first one focused on function calling and building an air quality system.
- The second one covered querying private PDFs with the help of an LLM.
The Problem: Check Fraud Detection
Banks and financial institutions receive a large volume of physical checks daily. Each check needs to be validated to ensure it's not fraudulent. This is where an LLM system can assist. When a check is marked as fraudulent, a human employee needs to write an explanation of why it's considered fraudulent. This is a time-consuming task that many financial institutions undertake. They hire people to evaluate checks for fraud and write descriptions for fraudulent ones.
The goal is to use an LLM to generate these explanations, freeing up employees to be more productive in other areas. While AI may not be allowed to write these descriptions in many jurisdictions, it can still suggest a description that the human can accept if they're satisfied with it, thereby improving their productivity.
The Solution: A Feature Pipeline, Training Pipeline and Inference Pipeline Architecture
To build a check fraud detection system, we'll follow a specific architecture called the feature-training-inference (FTI) pipeline architecture. The idea is to break down the AI system into smaller, easily composable modules. Here's an overview:
- Feature Pipeline: This module takes in the data, parses it, and creates features. The resulting feature table is called a feature group.
- Training Pipeline: Here, we train a simple model for fraud detection in checks using the features from the feature pipeline.
- Inference Pipeline: Finally, we perform inference for fraud detection using the trained model.
The Process
Data Preparation
We start with images of checks and some labeled data for supervised machine learning. The checks go through an optical character recognition (OCR) system that extracts the text from the images.
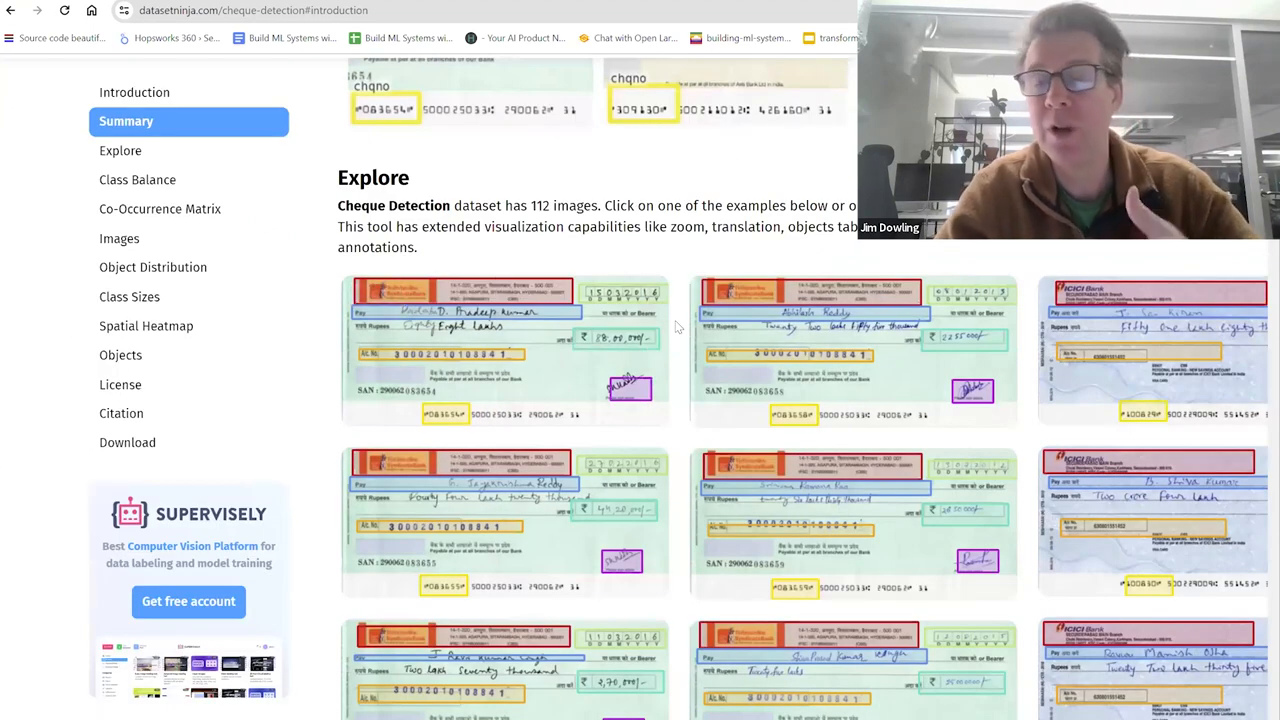
The OCR system identifies bounding boxes on the check and uses optical character recognition to extract the written text. This is a traditional deep learning CNN-style network problem, and many existing frameworks can handle it. We'll assume this OCR system is already in place at your financial institution.
Feature Pipeline
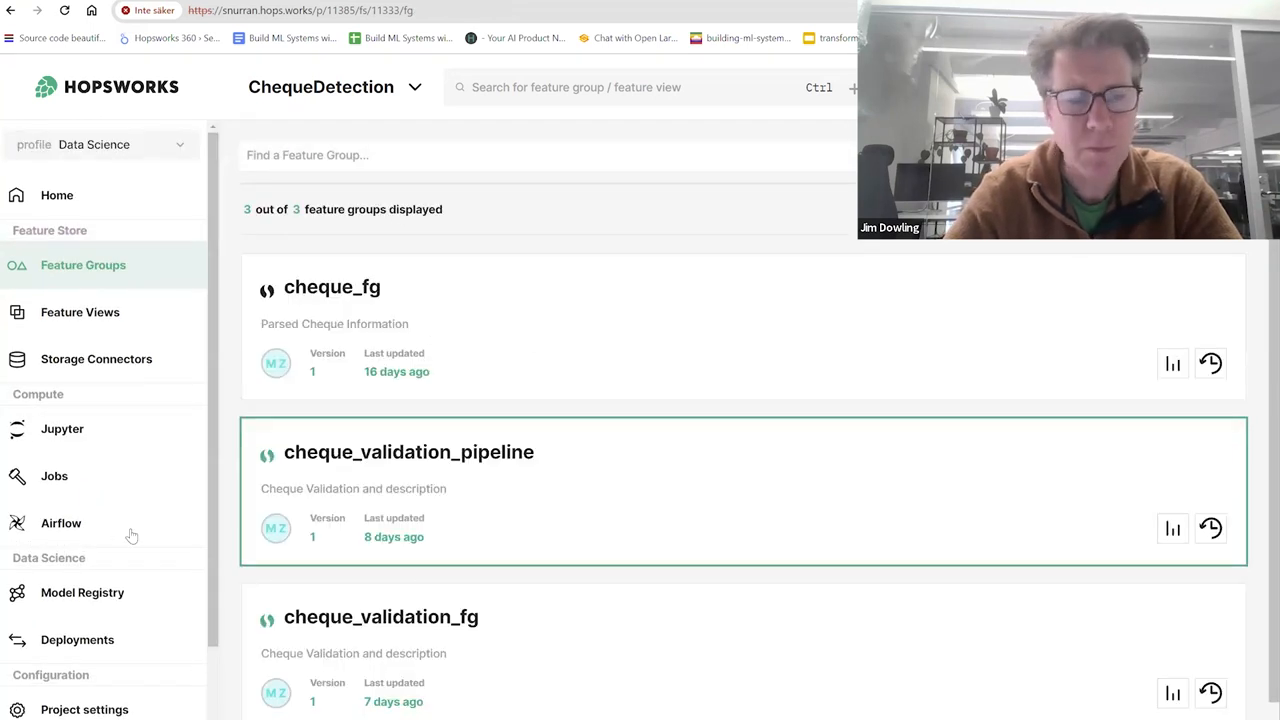
Using the extracted text from the checks, we create a feature pipeline. This pipeline reads the data, parses it, and creates features that we store in a feature table called a feature group.
Some of the features we extract include:
- Check number
- User ID
- Amount of money in text
- Amount written in numbers
- File path
- Whether the amount in text matches the amount in numbers
- Bank name
- Spelling correctness
- Username
We also have a label indicating whether the check is valid or not. Here's a preview of the data:
Training Pipeline
With our features ready, we move on to training a simple model to predict whether a check is fraudulent. We use an XGBoost classifier for this purpose. In Hopsworks, we create a feature view that selects the relevant features from the feature group(s). For this model, we don't need a huge number of features.
We use:
- Is the spelling correct?
- Does the amount of the check in letters and numbers match?
- The valid label
We train the model and store it in the Hopsworks model registry. We also compute some model metrics and feature importance scores.
Inference Pipeline
The inference pipeline is a batch process that runs daily. It takes the new checks that arrive each day and predicts whether they are fraudulent. If a check is predicted as fraudulent, the LLM generates a description explaining why.
Here's how it works:
- The new check images are uploaded to a designated directory.
- The batch inference program runs daily, processing the images in that directory.
- For each check, the program:some text
- Extracts the text using OCR
- Predicts whether the check is fraudulent using the trained model
- If the check is predicted as fraudulent, uses the LLM to generate an explanation
- The predictions and explanations are stored in a feature group (which is also a MySQL table).
- A decision support system can connect to this table, read the output, and use the generated explanations in reports.
Here's an example of the output:
Putting It All Together
Let's walk through the code to see how everything comes together. We'll use Python notebooks in Hopsworks for this example, but you can also run the code locally or in Colab with some modifications.
Prerequisites
Clone the Hopsworks tutorials repository:
Navigate to the fraud-check-detection directory:
Install the required libraries:
Feature Pipeline
Connect to Hopsworks and read the CSV file containing the check data:
Explore the data and create features:
Create a feature group and insert the data:
Training Pipeline
Create a feature view:
Create the training dataset, with a random train/test split of 80/20:
Train the model:
Evaluate the model:
Save the model in the Hopsworks model registry:
Inference Pipeline
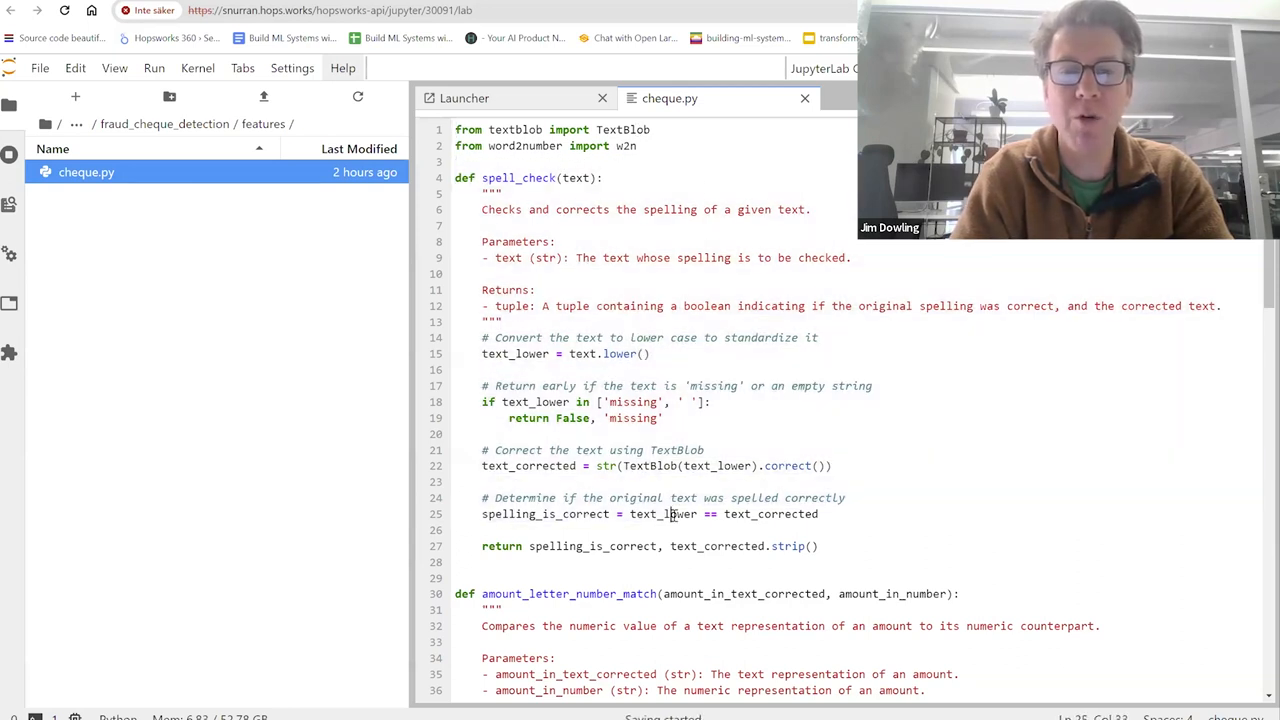
Load the trained model and OCR processor:
Define a function to generate explanations using the LLM:
Process the new checks daily:
Save the results in a feature group:
Conclusion
In this blog post, we've seen how to build a check fraud detection system using LLMs. We broke down the process into three main parts:
- A feature pipeline to extract features from check images
- A training pipeline to train a fraud detection model
- An inference pipeline to predict fraud and generate explanations using an LLM
By automating the explanation generation process, we can save financial institutions a significant amount of time and resources. The LLM-generated explanations can serve as a starting point for human employees, who can then review and modify them as needed. The aim of this example was to give a good understanding of how to use LLMs in a practical application like check fraud detection.
Watch the full video here: