Die fehlende Datenschicht für Machine Learning-Pipelines?
Ein Feature Store ist ein zentraler Speicher für die Aufbewahrung von dokumentierten, gepflegten und zugriffsgeschützten Features. In diesem Blog-Beitrag diskutieren wir den Stand der Technik im Daten

Was ist ein Feature Store?
Das Konzept eines Feature Stores wurde 2017 von Uber eingeführt. Der Feature Store ist ein zentraler Ort, an dem gepflegte Features innerhalb einer Organisation gespeichert werden. Ein Feature ist eine messbare Eigenschaft einer Daten-Stichprobe.
Es könnte zum Beispiel ein Bildpixel, ein Wort aus einem Text, das Alter einer Person, eine Koordinate, die von einem Sensor ausgegeben wird, oder ein Aggregatwert wie die durchschnittliche Anzahl von Käufen in den letzten Stunden sein. Features können direkt aus Dateien und Datenbanktabellen extrahiert oder aus einer oder mehreren Datenquellen abgeleitete Werte sein.
Features sind der Treibstoff für AI-Systeme, da wir sie verwenden, um Modelle mit maschinellem Lernen zu trainieren, damit wir Vorhersagen für Featurewerte machen können, die wir zuvor nicht gesehen haben.

Abbildung 1. Ein Feature Store ist die Schnittstelle zwischen Feature Engineering und Modellentwicklung.
Der Feature Store verfügt über zwei Schnittstellen - eine für Data Engineers zum Schreiben der Features und eine für Data Scientists zum Lesen der Features. Letztere verwenden die Features, um ihre Modelle zu trainieren. Die Features selbst werden währenddessen weder in eine Datei oder in eine projektspezifische Datenbank geschrieben, sondern in den Feature Store.
Ein Beispiel für einen Data Engineer:
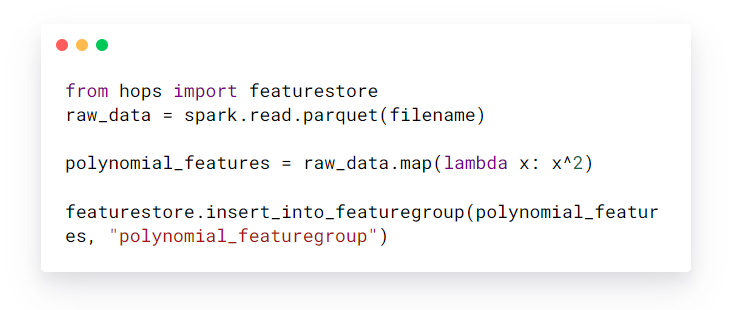
Beispiel für einen Data Scientist
Ein Feature Store ist nicht nur ein einfach zu bedienender Datenspeicherdienst, sondern auch ein Datentransformationsdienst, der Feature-Engineering zum Bürger erster Klasse macht. Feature-Engineering ist der Prozess der Umwandlung von Rohdaten in ein Format, das für Vorhersagemodelle verständlich ist.
Warum Sie einen Feature Store brauchen
Bei Hopsworks haben wir uns der Entwicklung von Technologien verschrieben, um Machine-Learning-Workflows in großem Maßstab zu betreiben und Organisationen dabei zu helfen, Intelligenz aus Daten zu gewinnen. Maschinelles Lernen ist eine äußerst leistungsfähige Methode, die uns helfen kann, von einem historischen Verständnis der Welt zu einer prädiktiven Modellierung der Welt um uns herum zu gelangen. Das Erstellen von Systemen für maschinelles Lernen ist jedoch schwierig und erfordert spezialisierte Plattformen und Tools.
Obwohl Ad-hoc-Feature-Engineering und Trainings-Pipelines Data Scientists eine schnelle Möglichkeit bieten, mit maschinellen Lernmodellen zu experimentieren, neigen solche Pipelines dazu, mit der Zeit komplex zu werden.
Mit zunehmender Anzahl an Modellen wird daraus schnell ein schwer zu verwaltender Pipeline-Dschungel. Dies motiviert zur Verwendung standardisierter Methoden und Werkzeuge für den Feature-Engineering-Prozess und trägt dazu bei, die Kosten für die Entwicklung neuer Vorhersagemodelle zu senken. Der Feature Store ist ein Dienst, der für diesen Zweck entwickelt wurde.
Technische Schulden in maschinellen Lernsystemen
Machine Learning: Die hochverzinsliche Kreditkarte der technischen Schulden.
Maschinelle Lernsysteme neigen dazu, technische Schulden anzuhäufen [1]. Beispiele für technische Schulden in maschinellen Lernsystemen sind:
- Es gibt keine prinzipielle Möglichkeit, während der Modellbereitstellung auf Features zuzugreifen.
- Features können nicht einfach zwischen mehreren MLOps-Pipelines für maschinelles Lernen wiederverwendet werden.
- Data-Science-Projekte arbeiten isoliert ohne gemeinsame Nutzung, Zusammenarbeit und Wiederverwendung.
- Features, die für Training und Serving verwendet werden, sind inkonsistent.
- Wenn neue Daten eintreffen, gibt es keine Möglichkeit, genau festzulegen, welche Features neu berechnet werden müssen, sondern es muss die gesamte Pipeline ausgeführt werden, um Features zu aktualisieren.
Mehrere Organisationen, mit denen wir gesprochen haben, haben aufgrund der technischen Komplexität Schwierigkeiten, ihre Workflows für maschinelles Lernen zu skalieren, und einige Teams zögern sogar, maschinelles Lernen angesichts der hohen technischen Kosten einzuführen.
Die Verwendung eines Feature-Stores ist Best Practice für MLOps-Pipelines, da sie die technische Schuld von Workflows für maschinelles Lernen reduzieren kann.
Pipeline-Dschungel lassen sich nur vermeiden, wenn man ganzheitlich über Datenerfassung und Feature-Extraktion nachdenkt.
Data Engineering ist das schwierigste Problem beim maschinellen Lernen
Daten sind der schwierigste Teil von ML und der wichtigste Teil, der richtig gemacht werden muss.. Modellierer verbringen die meiste Zeit damit, Features zur Trainingszeit auszuwählen und zu transformieren und dann die Pipelines zu erstellen, um diese Features an Produktionsmodelle zu liefern. Fehlerhafte Daten sind die häufigste Ursache für Probleme in Produktions-ML-Systemen.
– Uber [2]
Abbildung 2. Die Modellentwicklung ist nur ein Teil der Arbeit, die in ein maschinelles Lernprojekt gesteckt wird.
Die Bereitstellung von Lösungen für maschinelles Lernen in der Produktionim großen Maßstab unterscheidet sich stark von der Anpassung eines Modells an einen präparierten Datensatz. In der Praxis wird ein großer Teil des Aufwands, der in die Entwicklung eines Modells gesteckt wird, für Feature Engineering und Data Wrangling aufgewendet.
Es gibt viele verschiedene Möglichkeiten, Features aus Rohdaten zu extrahieren, aber zu den üblichen Schritten gehören:
- Konvertieren von kategorialen Daten in numerische Daten;
- Normalisieren von Daten (um Probleme bei der Optimierung aufgrund unterschiedlicher Verteilungen der Features zu vermeiden);
- One-Hot-Encoding / Binarisierung;
- Feature binning (z.B. Konvertierung kontinuierlicher Features in diskrete);
- Feature hashing (z.B. um den Speicherbedarf von one-hot-encodierten Features zu reduzieren);
- Berechnen von polynomischen Features;
- Repräsentationslernen (z.B. Extraktion von Features durch Clustering, Embeddings oder generative Modelle);
- Berechnen von aggregierten Features (z.B. Anzahl, Minimum, Maximum, Standardabweichung).
Um die Bedeutung der Featuregenerierung zu verdeutlichen, betrachten wir eine Klassifikationsaufgabe auf einem Datensatz mit nur einem Feature, x1, der so aussieht:
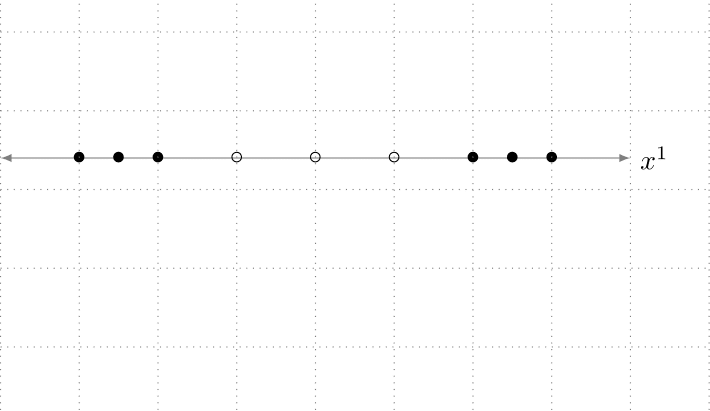
Abbildung 3. Ein Datensatz mit einem einzigen Merkmal, x1, das zwei Klassen (gefüllter Kreis und nicht gefüllter Kreis) hat, die nicht linear trennbar sind.
Wir sind zum Scheitern verurteilt, wenn wir versuchen, ein lineares Modell direkt auf diesen Datensatz zu trainieren, da er nicht linear separierbar ist. Während der Featuregenerierung können wir ein zusätzliches Feature, x2, extrahieren, bei dem die Funktion zur Ableitung von x2 aus dem Rohdatensatz x2 = (x1)^2 ist. Der resultierende zweidimensionale Datensatz könnte wie in Abbildung 2 dargestellt aussehen.
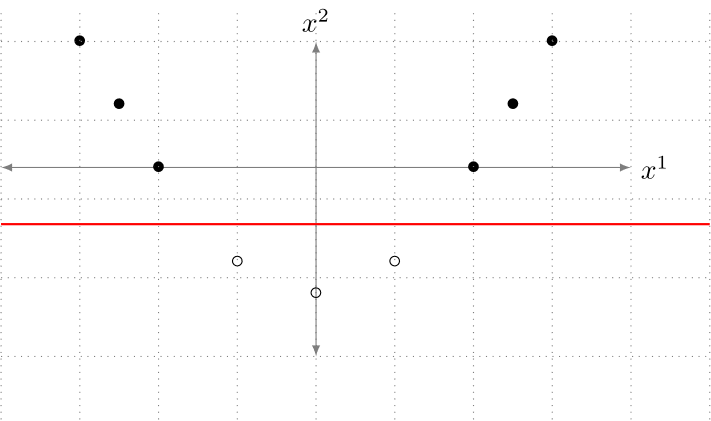
Abbildung 4. Ein Datensatz mit zwei Merkmalen, x1 und x2, die zwei Klassen (gefüllter Kreis und nicht gefüllter Kreis) haben, die linear trennbar sind (z. B. durch die rote Linie).
Durch Hinzufügen eines zusätzlichen Features wird der Datensatz linear trennbar und kann von unserem Modell gelernt werden. Dies war ein einfaches Beispiel, in der Praxis kann der Prozess der Featuregenerierung viel komplexere Transformationen beinhalten.
Im Falle des Deep Learnings tendieren die Modelle dazu, mit umso mehr Trainingsdaten umso besser zu performen (mehr Daten während des Trainings können einen regulierenden Effekt haben und Überanpassung bekämpfen). Folglich ist ein Trend im Machine Learning, auf immer größere Datensätze zu trainieren.
Dieser Trend erschwert den Prozess der Featuregenerierung weiter, da Daten-Ingenieure auch an Skalierbarkeit und Effizienz in Bezug auf die Featuregenerierung denken müssen. Mit einer standardisierten und skalierbaren Feature Plattform kann die Komplexität der Featuregenerierung effektiver verwaltet werden.
Das Leben ohne Feature Store
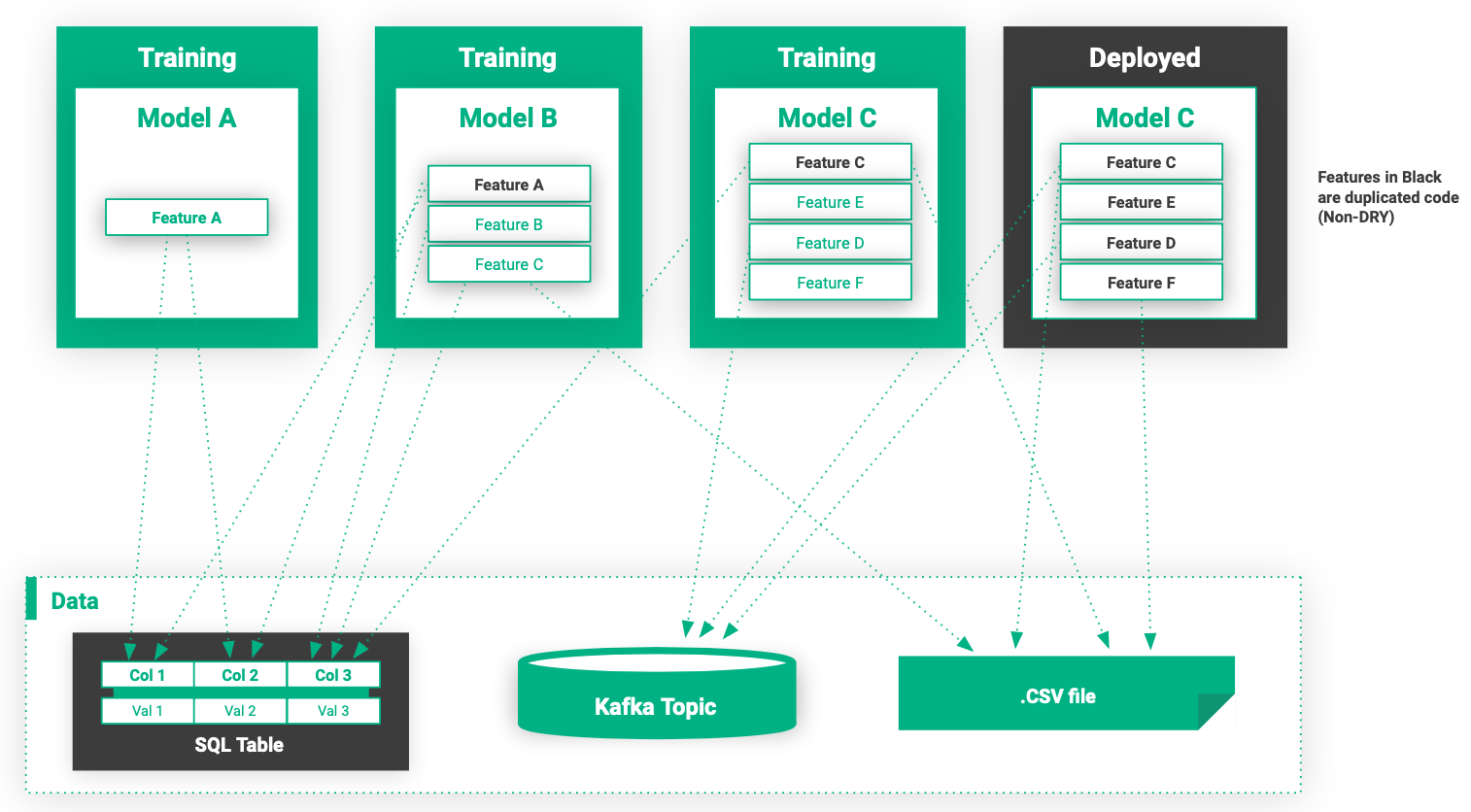
Abbildung 5. Eine typische Pipeline-Infrastruktur für maschinelles Lernen ohne Feature Store.
Kein Feature-Store
In Abbildung 5 wird der Code zur Feature-Generierung über Trainingsjobs hinweg dupliziert, und es gibt auch Features mit unterschiedlichen Implementierungen: eine für das Training und eine für die Bereitstellung (Inferenz) (Modell C). Das Vorhandensein unterschiedlicher Implementierungen für die Feature-Generierung für Training und Bereitstellung führt zu Nicht-DRY-Code (DRY = ”Don't Repeat Yourself”,) und kann zu Problemen bei der Vorhersage führen.
Darüber hinaus sind Features ohne einen Feature Store normalerweise nicht wiederverwendbar, da sie in Trainings-/Serving-Jobs eingebettet sind. Dies bedeutet auch, dass Data Scientists Low-Level-Code für den Zugriff auf Datenspeicher schreiben müssen, was Data-Engineering-Kenntnisse erfordert. Es gibt auch keinen Dienst zum Suchen nach Feature-Implementierungen, und es gibt keine Verwaltung oder Steuerung von Features.
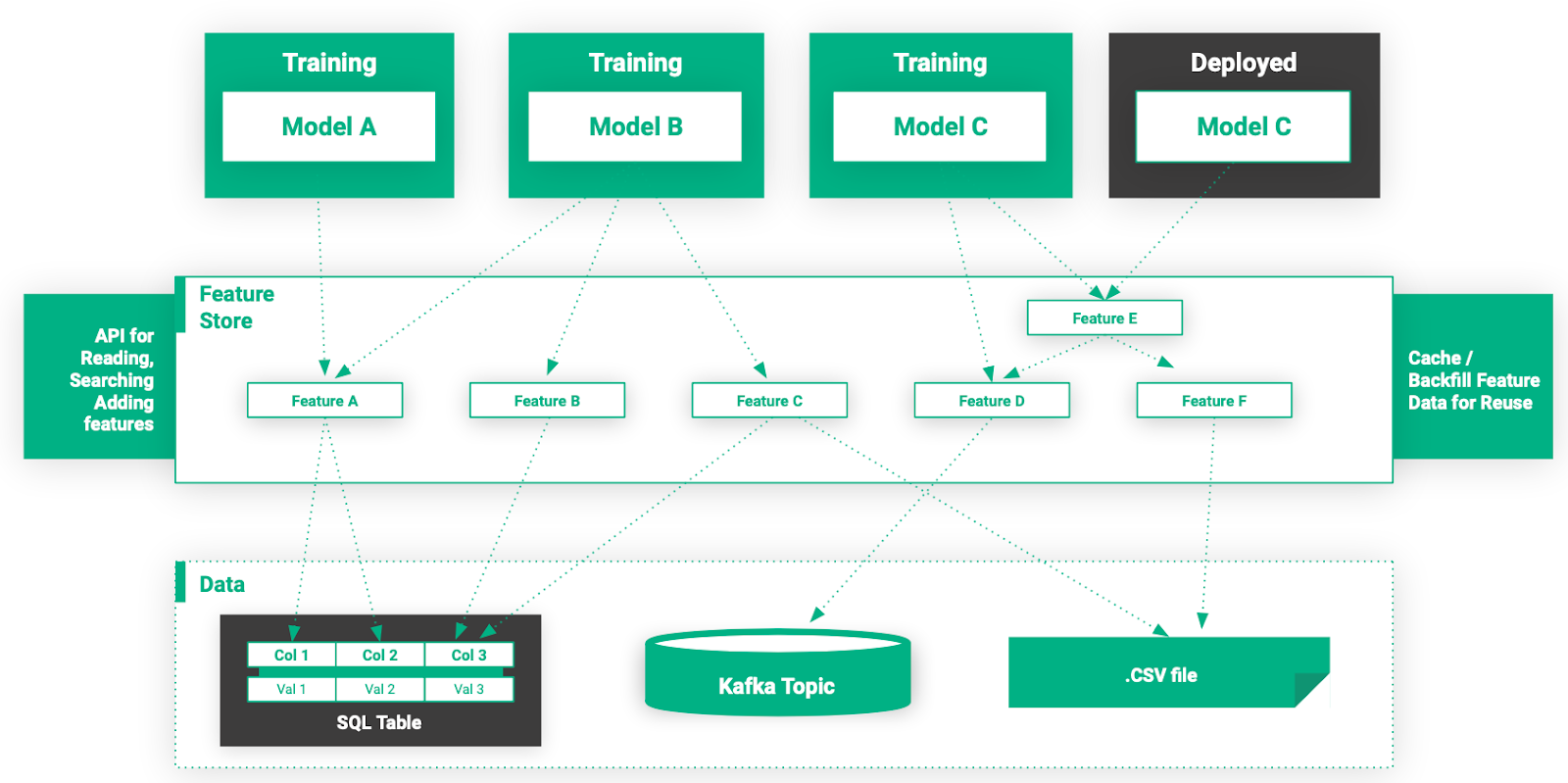
Abbildung 6. Eine MLOps-Infrastruktur mit einem Feature Store.
Mit einem Feature-Store
Data Scientists können jetzt nach Features suchen und diese mit API-Unterstützung einfach verwenden, um Modelle mit minimalem Einsatz von Data Engineering zu erstellen. Darüber hinaus können Features zwischengespeichert und von anderen Modellen wiederverwendet werden, wodurch die Modelltrainingszeit und die Infrastrukturkosten reduziert werden. Features sind jetzt ein verwaltetes, geregeltes Gut im Unternehmen.
Skaleneffekte für MLOps
Ein häufiger Fallstrick für Organisationen, die maschinelles Lernen anwenden, besteht darin, dass Data-Science-Teams als separate Gruppen betrachtet werden, die unabhängig voneinander mit begrenzter Zusammenarbeit arbeiten. Diese Denkweise führt zu Machine-Learning-Workflows, bei denen es keine standardisierte Möglichkeit gibt, Features über verschiedene Teams und Machine-Learning-Modelle hinweg zu teilen.
Die fehlende Möglichkeit, Features zwischen Modellen und Teams gemeinsam zu nutzen, schränkt die Produktivität von Data Scientists ein und erschwert die Erstellung neuer Modelle. Durch die Verwendung eines gemeinsam genutzten Feature Stores können Unternehmen Skalierungs-Effekte erzielen. Wenn der Feature Store mit mehr Features bestückt wird, wird es einfacher und billiger, neue Modelle zu erstellen, da die neuen Modelle Features wiederverwenden können, die bereits im Feature Store verfügbar sind.
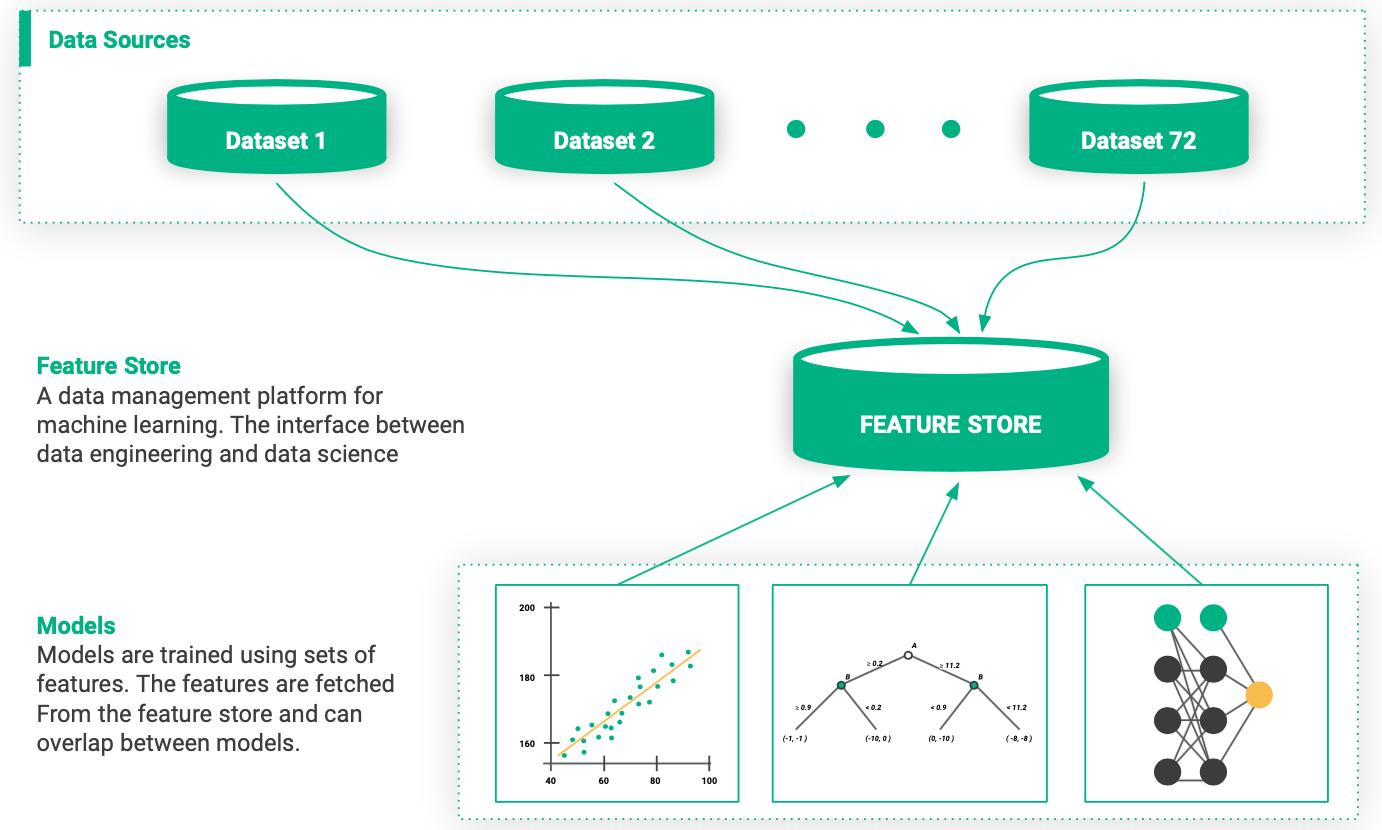
Abbildung 7. Durch die Zentralisierung der Funktionsspeicherung innerhalb der Organisation wird die Anlaufphase für neue Modelle und Machine-Learning-Projekte verkürzt.
Die Komponenten eines Feature Stores und ein Vergleich bestehender Feature Stores
Im Laufe des Jahres 2018 kündigten eine Reihe großer Unternehmen, die bei der Anwendung von maschinellem Lernen in großem Maßstab an vorderster Front stehen, die Entwicklung proprietärer Feature-Stores an. Uber, LinkedIn und Airbnb bauten ihre Feature Stores auf Hadoop Data Lakes auf, während Comcast einen Feature Store auf einem AWS Data Lake und GO-JEK einen Feature Store auf der Datenplattform von Google erstellte.
Diese bestehenden Feature Stores bestehen aus fünf Hauptkomponenten:
- Die Feature-Engineering-Jobs, die Berechnung von Features, die dominierenden Frameworks für die Feature-Berechnung sind Samza (Uber [4]), Spark (Uber [4], Airbnb [5], Comcast [6]), Flink (Airbnb [5], Comcast [6]) und Beam (GO-JEK [7]).
- Die Speicherebene zum Speichern von Feature-Daten. Gängige Lösungen zum Speichern von Features sind Hive (Uber [4], Airbnb [5]), S3 (Comcast [6]) und BigQuery (GO-JEK [7]).
- Die Metadatenebene, die zum Speichern von Code zum Berechnen von Features, Feature-Versionsinformationen, Feature-Analysedaten und Feature-Dokumentation verwendet wird.
- Die Feature-Store-API, die zum Lesen/Schreiben von Features aus dem/in den Feature-Store verwendet wird.
- Die Featureregistrierung, ein Benutzeroberfläche (UI), bei dem Data Scientists die Berechnung von Features freigeben, entdecken und anordnen können.
Bevor wir uns mit der Feature-Store-API und ihrer Verwendung befassen, werfen wir einen Blick auf den Technologie-Stack, auf dem wir unseren Feature-Store aufgebaut haben.
Hopsworks Feature Store-Architektur
Die Architektur des Feature Stores ist in Abbildung 8 dargestellt.
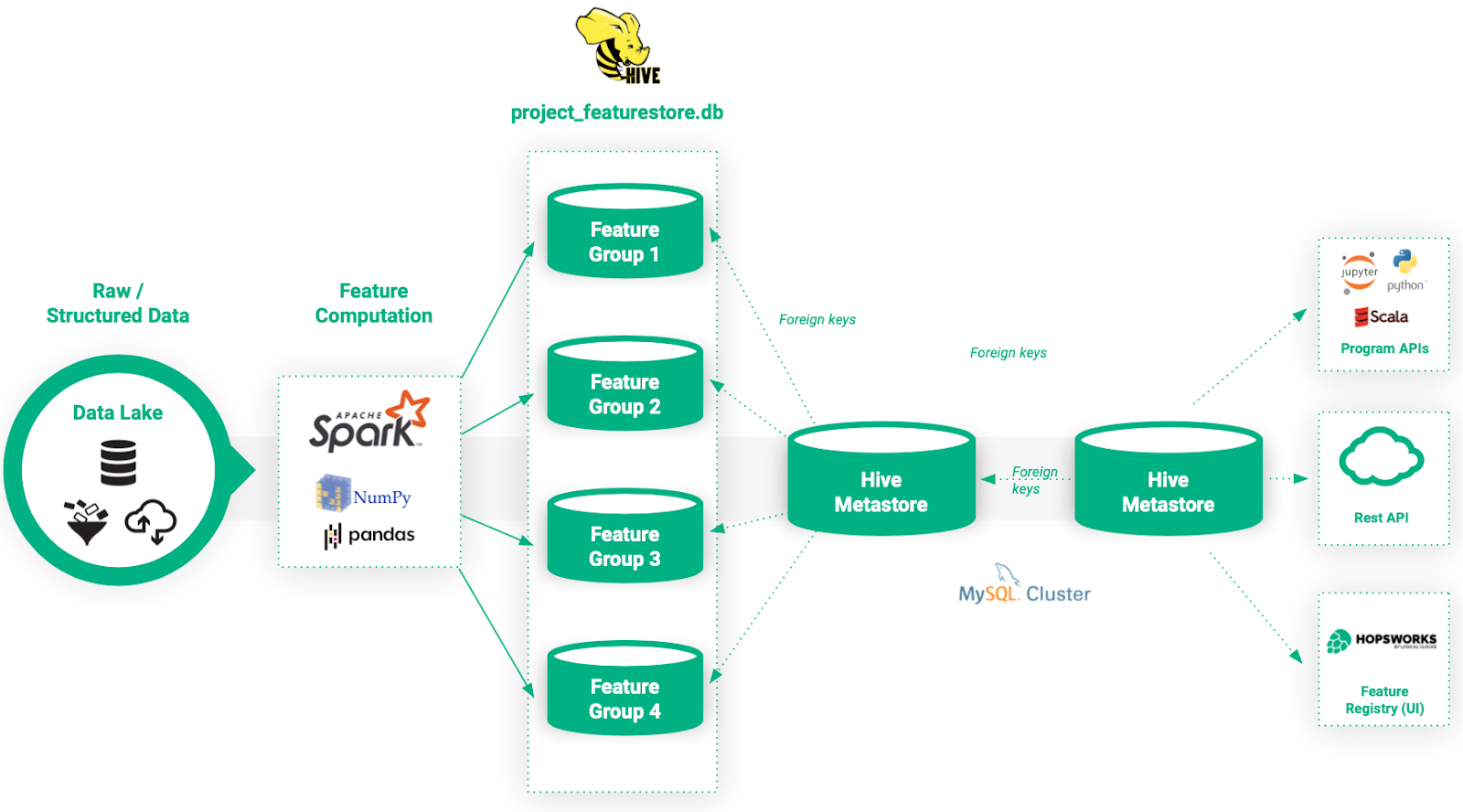
Abbildung 8. Architektur des Hopsworks Feature Store.
Feature-Generierungs-Frameworks
Bei Hopsworks spezialisieren wir uns auf Python-first ML-Pipelines und konzentrieren uns bei der Feature-Generierung auf Spark, PySpark, Numpy und Pandas. Der Grund für die Verwendung von Spark/PySpark zur Feature-Generierungist, dass es die bevorzugte Wahl für Datenaufbereitung unter unseren Nutzern ist, die mit großen Datensätzen arbeiten.
Allerdings haben wir auch beobachtet, dass Nutzer, die mit kleinen Datensätzen arbeiten, die Feature-Generierung lieber mit Frameworks wie Numpy und Pandas durchführen, weshalb wir beschlossen haben, auch native Unterstützung für diese Frameworks zu bieten. Nutzer können den Code für die Feature-Generierung auf der Hopsworks-Plattform mit Notebooks, Python-Dateien oder .jar-Dateien einreichen.
Der Storage Layer
Wir haben den Storage Layer für die Feature-Daten auf Hive/HopsFS aufgebaut, mit zusätzlichen Abstraktionen speziell für das Modellieren von Features.
Der Grund für die Verwendung von Hive als unterliegender Speicherungsebene ist zweifach: (1) es ist nicht ungewöhnlich, dass unsere Nutzer mit Datensätzen in Terabyte-Größe oder größer arbeiten und skalierbare Lösungen fordern, die auf HopsFS bereitgestellt werden können (siehe Blog-Post über HopsFS [9]); und (2) das Modellieren von Features erfolgt natürlich in relationaler Weise, indem relationale Features in Tabellen gruppiert werden und SQL verwendet wird, um den Feature Store abzufragen.
Diese Arten von Datenmodellierung und Zugriffsmechanismen passen gut zu Hive, insbesondere in Kombination mit spaltenorientierten Speicherformaten wie Parquet oder ORC.
Die Metadaten-Ebene
Um automatische Versionierung, Dokumentation, Analyse und das Teilen von Features zu ermöglichen, speichern wir erweiterte Metadaten über Features in einem Metadaten-Speicher. Für den Metadaten-Speicher nutzen wir NDB (MySQL Cluster), mit dem wir Feature-Metadaten speichern können, die konsistent mit anderen Metadaten in Hopsworks sind, wie bspw. Metadaten über Feature-Generierungs-Jobs und Datensätze.
Modellierung von Feature Daten
Wir stellen unseren Nutzern drei neue Konzepte zur Modellierung von Daten im Feature Store vor.
- Das Feature ist eine individuelle, versionierte und dokumentierte Datenspalte im Feature Store, z.B. die durchschnittliche Bewertung eines Kunden.
- Die Feature Groupist eine dokumentierte und versionierte Gruppe von Features, die als Hive-Tabelle gespeichert werden. Die Feature Groupist mit einem bestimmten Spark / Numpy / Pandas-Job verknüpft, der Rohdaten eingibt und die berechneten Featuresausgibt.
- Der Trainingsdatensatz ist ein versioniertes und verwaltetes Datenset von Features und Labels (potenziell aus mehreren verschiedenen Feature Groups). Trainingsdatensätze werden in HopsFS als tfrecords, oder parquet, csv, tsv, hdf5, oder .npy files.
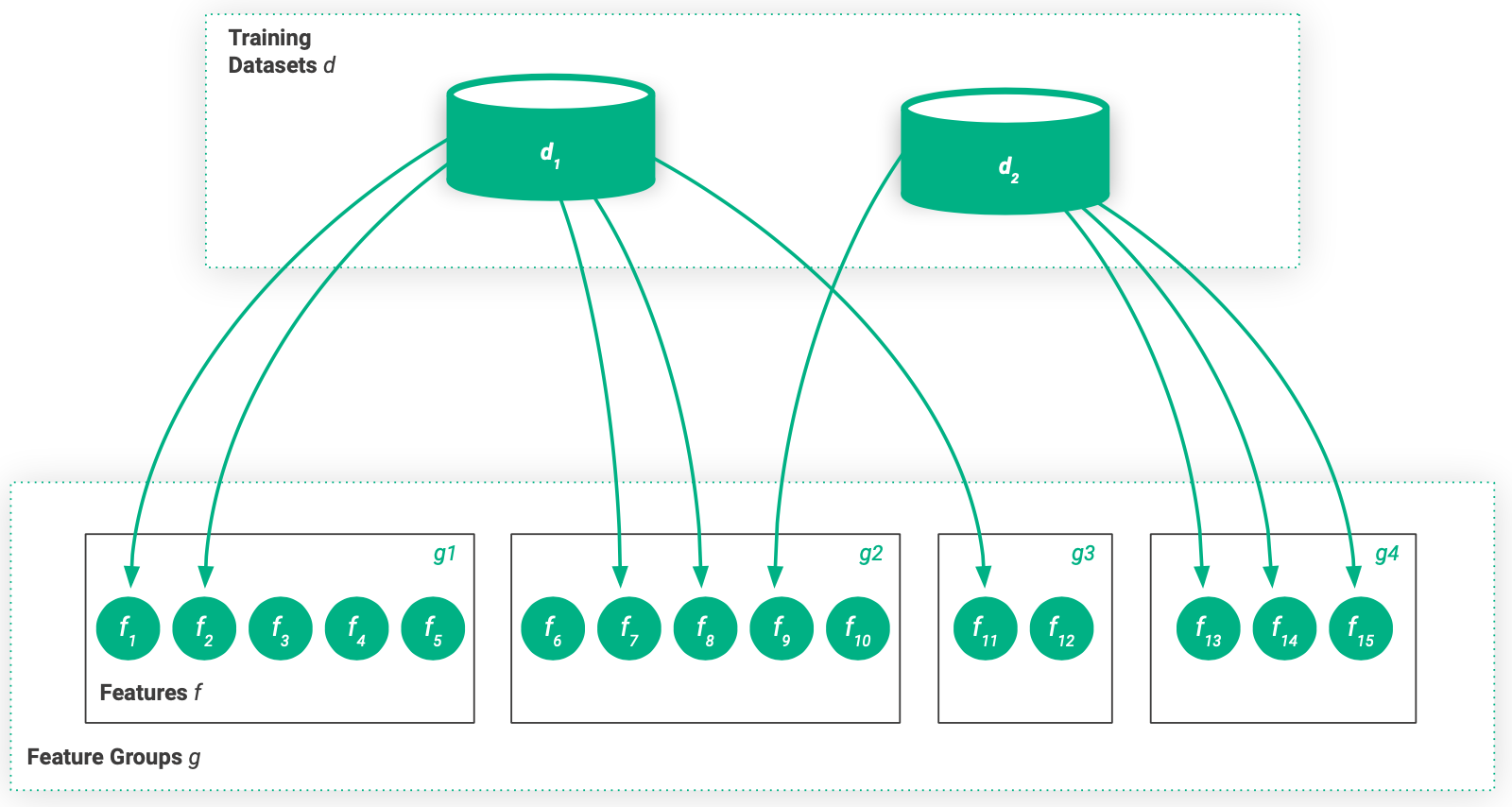
Abbildung 9. Eine Merkmalsgruppe enthält eine Gruppe von Merkmalen und ein Trainingsdatensatz enthält einen Satz von Merkmalen, möglicherweise aus vielen verschiedenen Merkmalsgruppen.
Beim Entwerfen von Feature Groups ist es eine beste Praxis, dass alle Features, die aus den gleichen Rohdatensätzen berechnet werden, in der gleichen Feature Group enthalten sind. Es ist üblich, dass es mehrere Feature Groups gibt, die eine gemeinsame Spalte teilen, wie einen Zeitstempel oder eine Kunden-ID, die es ermöglicht, Feature Groups zu einem Trainingsdatensatz zusammenzuführen.
Die Feature Store API
Der Feature Store hat zwei Schnittstellen; eine Schnittstelle zum Schreiben von ausgewählten Features in den Feature Store und eine Schnittstelle zum Lesen von Features aus dem Feature Store zum Training oder Servieren.
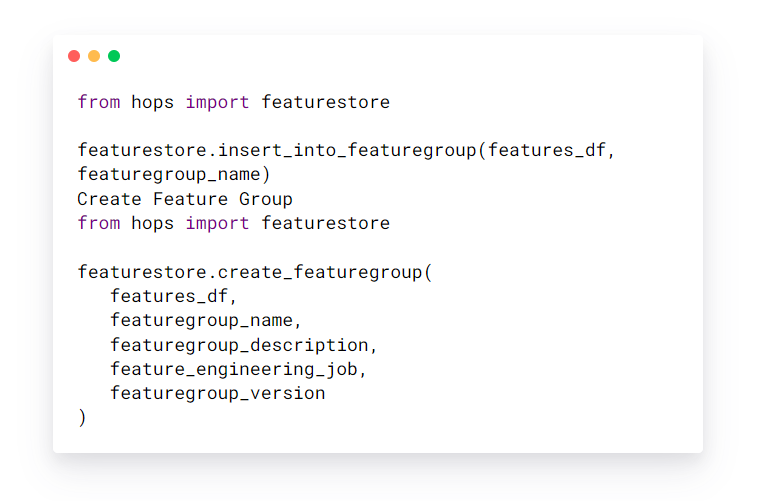
Features erstellen
Der Feature Store ist agnostisch gegenüber der Methode zur Berechnung der Features. Die einzige Anforderung ist, dass die Features in einem Pandas, Numpy oder Spark-Dataframe gruppiert werden können. Der Nutzer gibt ein Dataframe mit Features und den dazugehörigen Featuredaten (Metadaten können später auch über die Feature-Registrierungs-UI bearbeitet werden) an und die Feature Store-Bibliothek kümmert sich um die Erstellung einer neuen Version der Feature Groups, die Berechnung von Feature-Statistiken und die Verknüpfung der Features mit dem Job, um sie zu berechnen.
Features einfügen
Feature Groups erstellen
Lesen aus dem Feature Store (Abfrageplaner)
Um Features aus dem Feature Store zu lesen, können Benutzer entweder SQL oder APIs in Python und Scala verwenden. Basierend auf unserer Erfahrung mit Benutzern unserer Plattform können Data Scientists unterschiedliche Hintergründe haben. Obwohl einige Data Scientists mit SQL sehr vertraut sind, bevorzugen andere APIs auf höherer Ebene.
Dies motivierte uns, einen Abfrageplaner zu entwickeln, um Benutzerabfragen zu vereinfachen. Der Abfrageplaner ermöglicht es Benutzern, das Nötigste an Informationen zum Abrufen von Features aus dem Feature Store anzugeben.
Beispielsweise kann ein Benutzer 100 Features anfordern, die auf 20 verschiedene Featuregruppen verteilt sind, indem er einfach eine Liste mit Featurenamen bereitstellt. Der Abfrageplaner verwendet die Metadaten im Feature Store, um abzuleiten, woher die Features abgerufen und wie sie zusammengefügt werden.
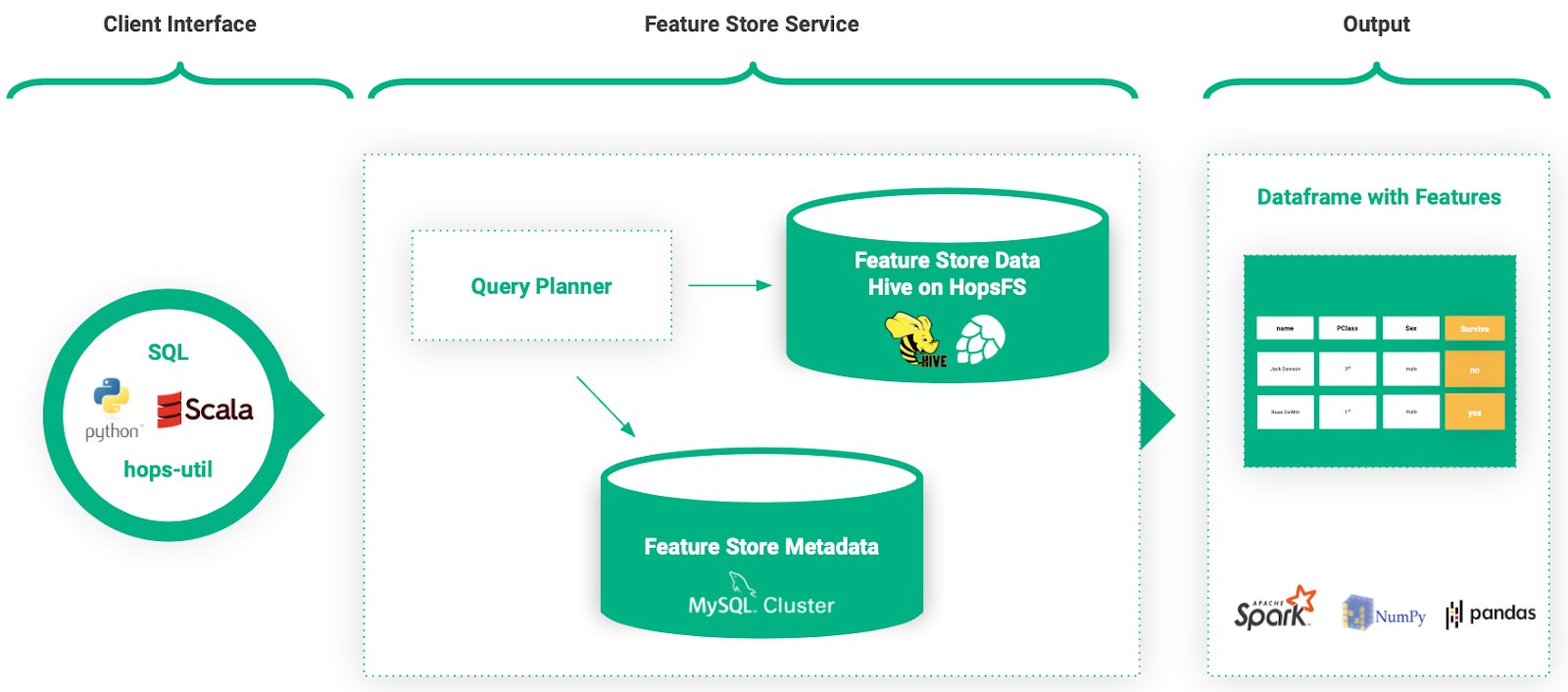
Abbildung 10. Benutzer fragen den Feature Store programmgesteuert oder mit SQL-Abfragen ab. Die Ausgabe wird als Pandas-, Numpy- oder Spark-Datenrahmen bereitgestellt.
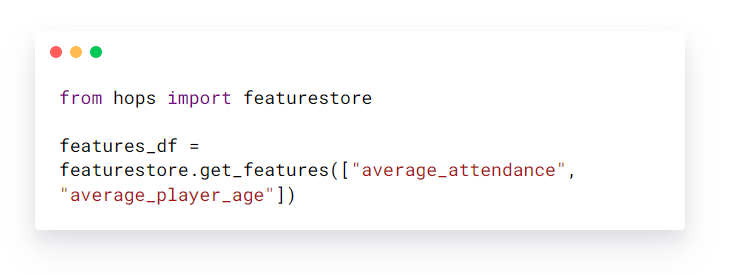
Um die Features „average_attendance“ und „average_player_age“ aus dem Feature Store abzurufen, muss der Benutzer nur Folgendes schreiben.
Beispiel zum Abrufen von Features
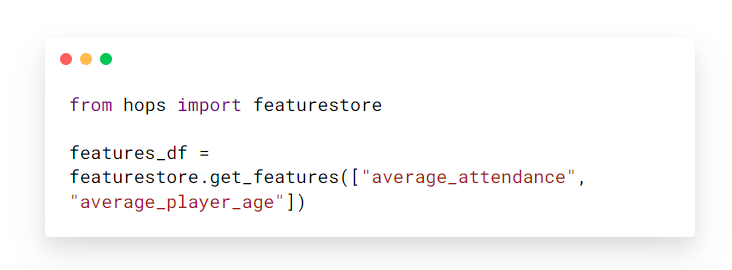
Das zurückgegebene „features_df“ ist ein Datenrahmen (Pandas, Numpy oder Spark), der dann verwendet werden kann, um Trainingsdatensätze für Modelle zu generieren.
Erstellen von Trainingsdatensätzen
Organisationen verfügen in der Regel über viele verschiedene Arten von Rohdatensätzen, die zum Extrahieren von Features verwendet werden können. Beispielsweise kann es im Zusammenhang mit Benutzerempfehlungen einen Datensatz mit demografischen Daten von Benutzern und einen anderen Datensatz mit Benutzeraktivitäten geben. Features aus demselben Dataset werden natürlich in einer Featuregruppe gruppiert, und es ist üblich, eine Featuregruppe pro Dataset zu generieren.
Wenn Sie ein Modell trainieren, möchten Sie alle Features mit Vorhersagekraft für die Vorhersageaufgabe einbeziehen. Diese Features können möglicherweise mehrere Featuregruppen umfassen. Dazu wird die Trainingsdatensatz-Abstraktion im Hopsworks Feature Store verwendet. Das Trainings-Dataset ermöglicht es Benutzern, eine Reihe von Features mit Labels zu gruppieren, um ein Modell für eine bestimmte Vorhersageaufgabe zu trainieren.
Sobald ein Benutzer eine Reihe von Features aus verschiedenen Feature-Gruppen im Feature Store abgerufen hat, können die Features mit Labels (im Falle von überwachtem Lernen) verbunden und in einem Trainingsdatensatz materialisiert werden.
Durch Erstellen eines Trainings-Datasets mit der Feature-Store-API wird das Dataset vom Feature-Store verwaltet. Verwaltete Trainingsdatensätze werden automatisch auf Datenanomalien analysiert, versioniert, dokumentiert und mit der Organisation geteilt.
Abbildung 11. Der Lebenszyklus von Daten in HopsML. Rohdaten werden in Features umgewandelt, die zu Trainingsdatensätzen zusammengefasst werden, die zum Trainieren von Modellen verwendet werden.
Um einen verwalteten Trainingsdatensatz zu erstellen, stellt der Benutzer einen Pandas-, Numpy- oder Spark-Datenrahmen mit Features, Beschriftungen und Metadaten bereit.
Erstellen Sie einen verwalteten Trainingsdatensatz
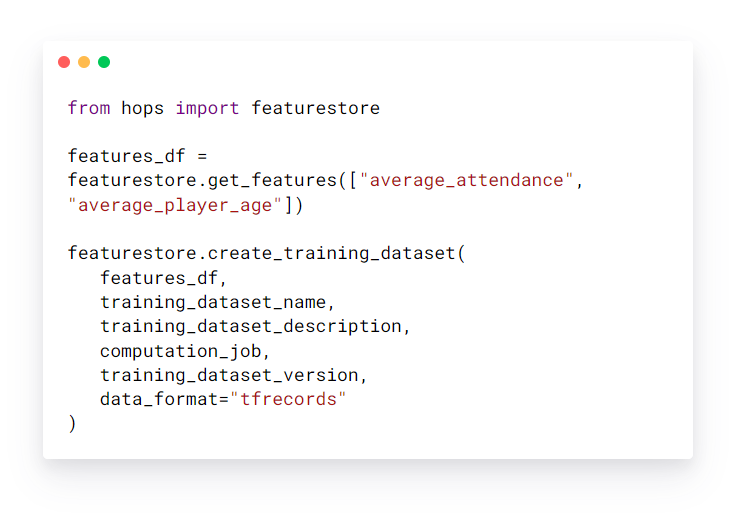
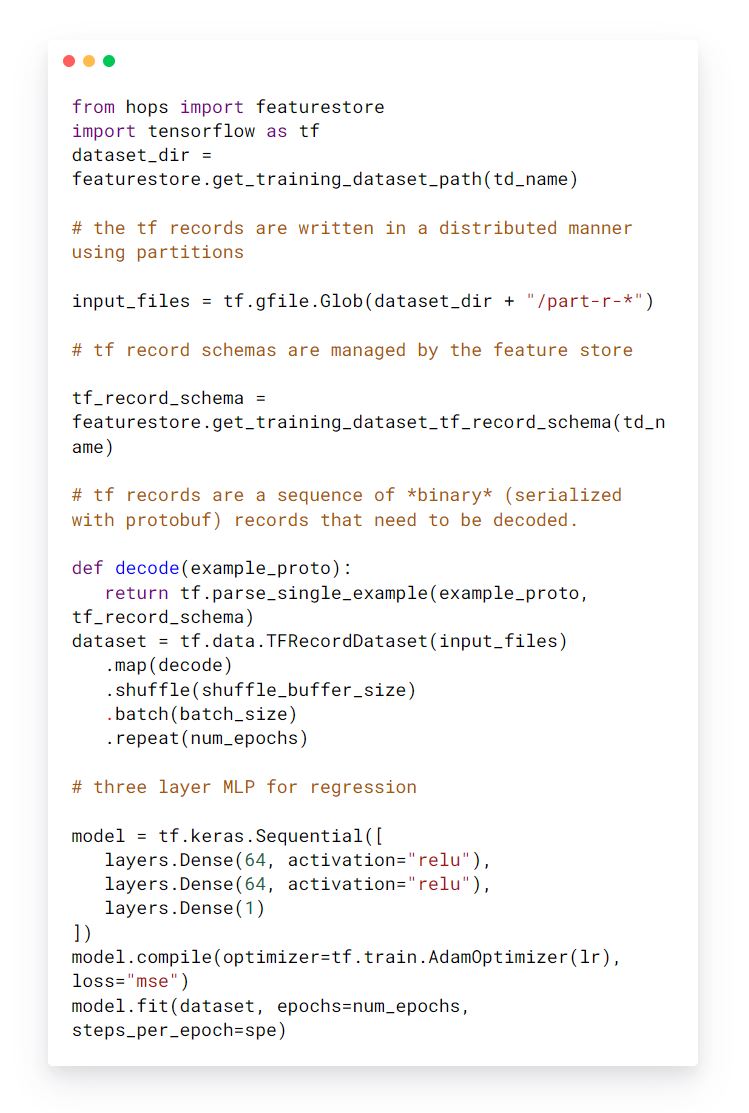
Sobald der Trainingsdatensatz erstellt wurde, ist er in der Feature-Registrierung auffindbar und für Benutzer zum Trainieren von Modellen verwendbar. Unten finden Sie ein Beispielcode-Snippet zum Trainieren eines Modells mit einem Trainingsdatensatz, der verteilt im tfrecords-Format auf HopsFS gespeichert ist.
Trainieren eines Modells mit einem Trainingsdatensatz.
Die Feature-Registrierung
Die Feature-Registrierung ist die Benutzeroberfläche zum Veröffentlichen und Ermitteln von Features und Trainings-Datasets. Die Featureregistrierung dient auch als Werkzeug zur Analyse der Featureentwicklung im Laufe der Zeit durch den Vergleich von Featureversionen. Wenn ein neues Data-Science-Projekt gestartet wird, beginnen Data Scientists innerhalb des Projekts in der Regel damit, die Feature-Registrierung nach verfügbaren Features zu durchsuchen und nur neue Features für ihr Modell hinzuzufügen, die noch nicht im Feature Store vorhanden sind.
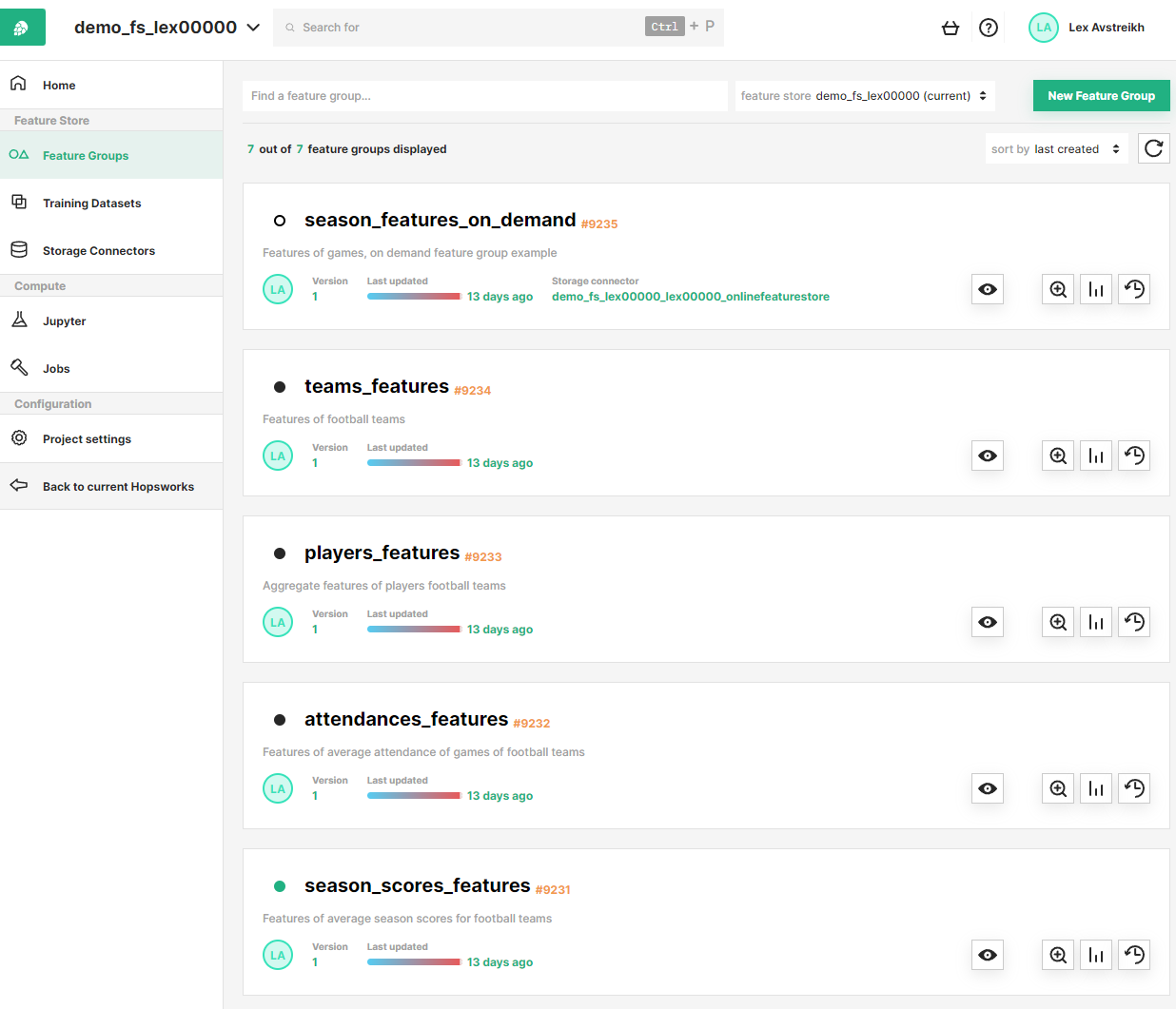
Abbildung 12. Funktionsregistrierung auf Hopsworks
Die Featureregistrierung bietet:
- Stichwortsuche nach Metadaten von Features/Feature Groups/Trainingsdatensätzen
- Vorgänge für Feature-/Feature-Gruppen-/Trainingsdatensatz-Metadaten erstellen/aktualisieren/löschen/anzeigen
- Automatische Feature-Analyse
- Feature-Abhängigkeits-Tracking
- Feature-Jobs Monitoring
- Feature-Datenvorschau
Automatische Feature-Analyse
Wenn eine Feature Group oder ein Trainingsdatensatz im Feature Store aktualisiert wird, wird ein Datenanalyseschritt durchgeführt. Insbesondere betrachten wir Clusteranalysen, Feature-Korrelationen, Feature-Histogramme und deskriptive Statistiken.
Wir haben festgestellt, dass dies die häufigsten Arten von Statistiken sind, die unsere Benutzer in der Feature-Modellierungsphase nützlich finden. Beispielsweise können Feature-Korrelationen verwendet werden, um redundante Features zu identifizieren, Feature-Histogramme können verwendet werden, um die Verteilung von Features zwischen verschiedenen Versionen eines Features zu überwachen, um Kovariatenverschiebungen zu entdecken. Clusteranalysen können verwendet werden, um Ausreißer zu erkennen. Der Zugriff auf solche Statistiken in der Feature-Registrierung hilft Benutzern bei der Entscheidung, welche Features verwendet werden sollen.
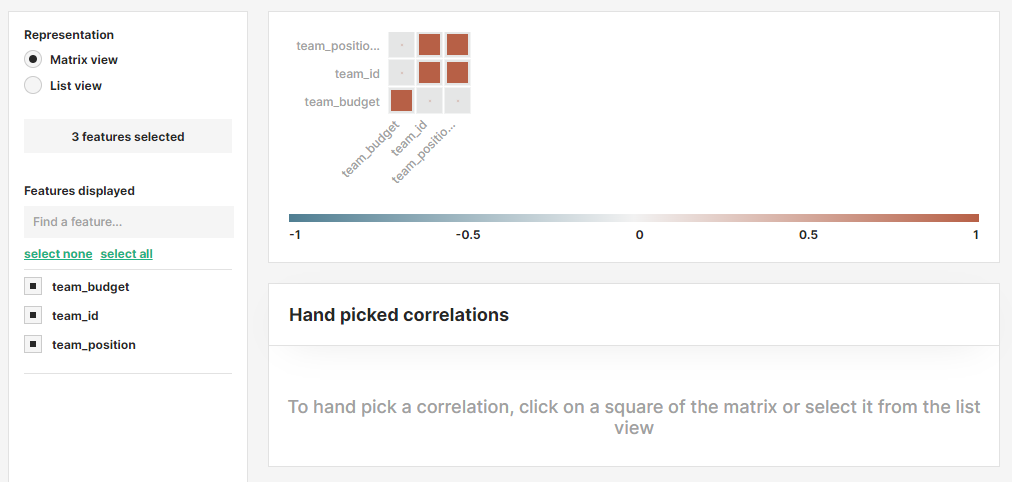
Abbildung 13. Anzeigen der Feature-Korrelation für ein Trainings-Dataset mithilfe der Feature-Registrierung.
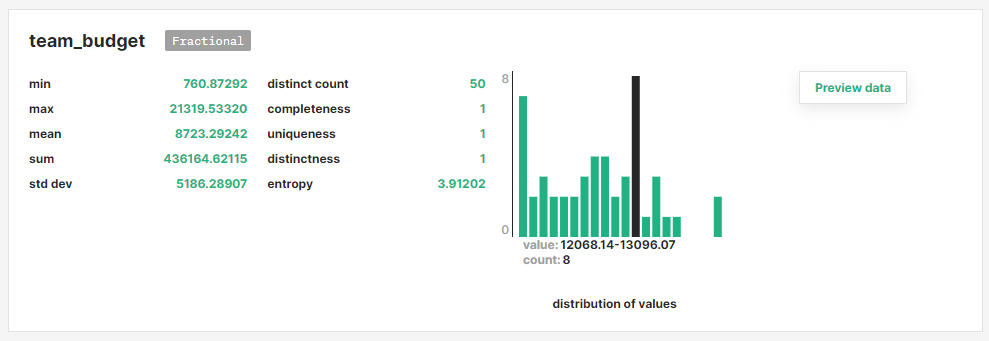
Abbildung 14. Anzeigen der Verteilung eines Features in einer Featuregruppe mithilfe der Featureregistrierung.
Feature-Abhängigkeiten und automatische Auffüllung
Wenn der Feature Store an Größe zunimmt, sollte der Prozess des Planens von Jobs zum Neuberechnen von Features automatisiert werden, um einen potenziellen Verwaltungsengpass zu vermeiden. Feature Groups und Trainingsdatensätze im Hopsworks Feature Store sind mit Spark/Numpy/Pandas-Jobs verknüpft, was die Reproduktion und Neuberechnung der Features bei Bedarf ermöglicht.
Darüber hinaus kann jede Feature Groupund jeder Trainingsdatensatz eine Reihe von Datenabhängigkeiten aufweisen. Durch die Verknüpfung von Feature Groups und Trainingsdatensätzen mit Jobs und Datenabhängigkeiten können die Features im Hopsworks-Feature-Store automatisch mit Workflow-Management-Systemen wie Airflow [10] nachgefüllt werden.
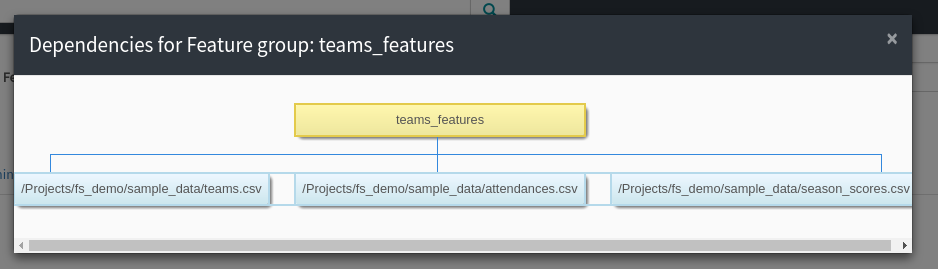
Abbildung 15. Nachverfolgung von Funktionsabhängigkeiten.
Ein Multi-Tenant Feature Store Service
Wir glauben, dass der größte Vorteil eines Feature Stores darin besteht, dass er in der gesamten Organisation zentralisiert ist. Je mehr hochwertige Features im Feature Store verfügbar sind, desto besser. Beispielsweise berichtete Uber im Jahr 2017, dass sie ungefähr 10000 Features in ihrem Feature Store hatten [11].
Trotz des Vorteils der Zentralisierung von Features haben wir die Notwendigkeit festgestellt, die Zugriffskontrolle auf Features durchzusetzen. Mehrere Organisationen, mit denen wir gesprochen haben, arbeiten teilweise mit sensiblen Daten, die bestimmte Zugriffsrechte erfordern, die nicht jedem in der Organisation gewährt werden. Beispielsweise ist es möglicherweise nicht möglich, Features, die aus sensiblen Daten extrahiert werden, in einem Feature Store zu veröffentlichen, der innerhalb der Organisation jedem zugänglich ist.
Um dieses Problem zu lösen, nutzen wir die in die Architektur der Hopsworks-Plattform integrierte Multi-Tenancy-Eigenschaft [12]. Feature Stores in Hopsworks sind standardmäßig projekt-privat und können projektübergreifend gemeinsam genutzt werden, was bedeutet, dass eine Organisation öffentliche und private Feature Stores kombinieren kann. Eine Organisation kann einen zentralen öffentlichen Feature Store haben, der für alle in der Organisation freigegeben ist, sowie private Feature Stores, die Features vertraulicher Art enthalten, auf die nur Benutzer mit den entsprechenden Berechtigungen zugreifen können.
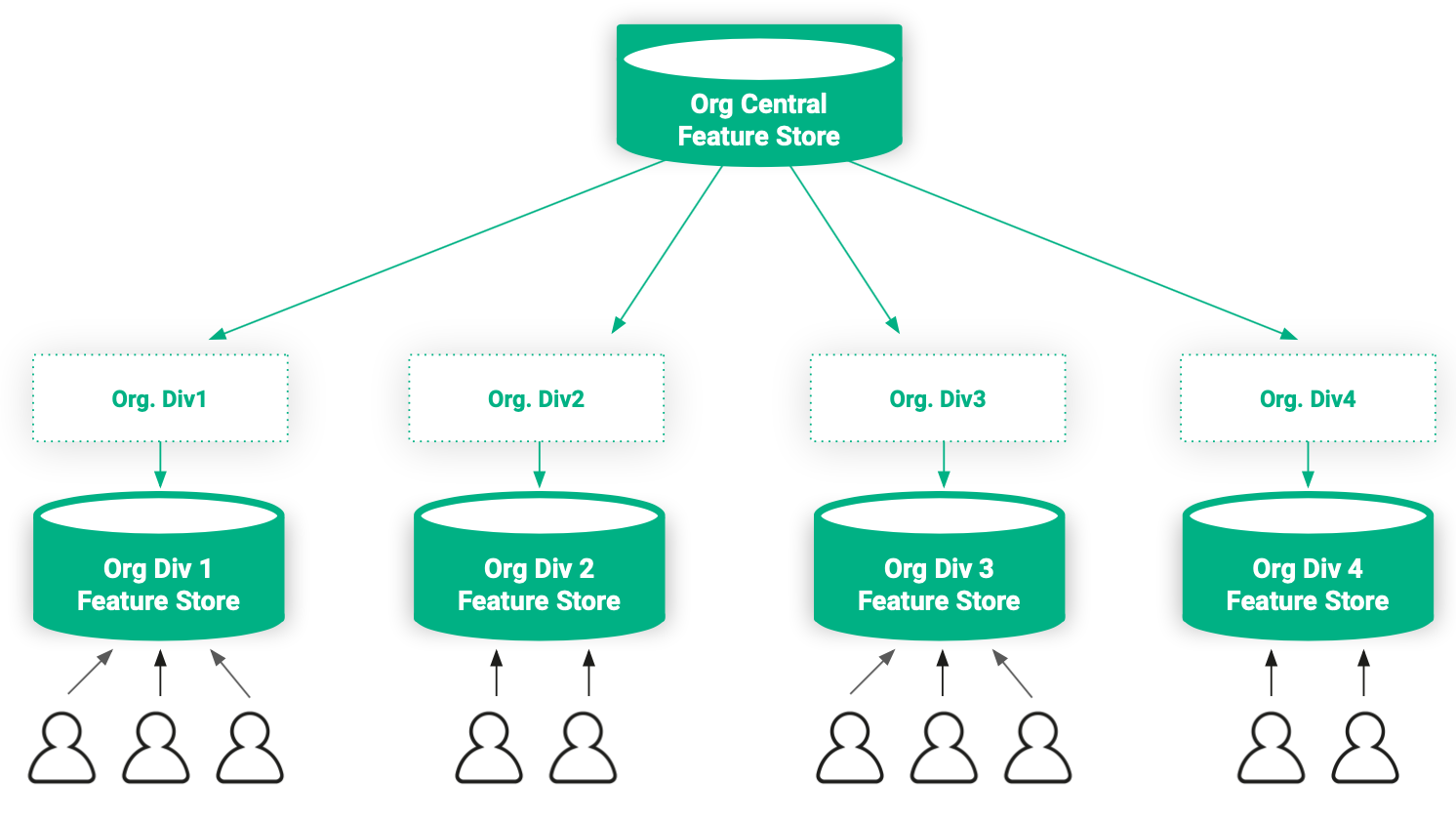
Abbildung 16. Basierend auf den Anforderungen der Organisation können Features in mehrere Feature Stores aufgeteilt werden, um die Datenzugriffskontrolle beizubehalten.
Zukünftige Arbeit
Der in diesem Blogbeitrag behandelte Feature Store ist ein sogenannter Batch-Feature-Store, was bedeutet, dass es sich um einen Feature Store handelt, der für das Training und die Bereitstellung von Nicht-Echtzeitmodellen entwickelt wurde. In Zukunft planen wir, den Feature Store zu erweitern, um Echtzeitgarantien zu erfüllen, die während der Bereitstellung von benutzerorientierten Modellen erforderlich sind.
Darüber hinaus sind wir derzeit dabei, die Notwendigkeit einer domänenspezifischen Sprache (DSL) für das Feature-Engineering zu evaluieren. Durch die Verwendung einer DSL können Benutzer, die Spark/Pandas/Numpy nicht beherrschen, eine abstrakte deklarative Beschreibung bereitstellen, wie Features aus Rohdaten extrahiert werden sollen, und die Bibliothek übersetzt diese Beschreibung dann in einen Spark-Job zum Berechnen der Features.
Schließlich prüfen wir auch die Unterstützung von Petastorm [13] als Datenformat für Trainingsdatensätze. Durch das Speichern von Trainingsdatensätzen in Petastorm können wir Parquet-Daten auf effiziente Weise direkt in maschinelle Lernmodelle einspeisen. Wir betrachten Petastorm als potenziellen Ersatz für tfrecords, der die Wiederverwendung von Trainingsdatensätzen für andere ML-Frameworks als Tensorflow, wie z. B. PyTorch, erleichtern kann.
Zusammenfassung
Der Aufbau erfolgreicher KI-Systeme ist schwierig. Bei Logical Clocks haben wir beobachtet, dass unsere Benutzer viel Aufwand in die Data-Engineering-Phase des maschinellen Lernens investieren. Ab der Veröffentlichung von Version 0.8.0 bietet Hopsworks den weltweit ersten Open-Source-Feature-Store. Ein Feature Store ist eine Datenverwaltungsebene für maschinelles Lernen, die es Data Scientists und Data Engineers ermöglicht, Features zu teilen und zu entdecken, Features im Laufe der Zeit besser zu verstehen und den Machine Learning-Workflow zu verbessern.
This article was first published on December 30th 2018, updated on February 2nd 2023.