Build Vs Buy: For Machine Learning/AI Feature Stores
On the decision of building versus buying a feature store there are strategic and technical components to consider as it impacts both cost and technological debt.

Introduction
In the field of Machine Learning and Artificial Intelligence, feature stores take up a very interesting if only a bit peculiar place. Here’s why: when organizations get started with ML / AI, they often do so in the typical vein of innovative, agile, creative and experimental projects. They will do lots of trials, fail a million times along the way, and gain experience with the field in their particular business organization. This is how innovation happens: you have to pull yourself out of the mud by the straps of your own boots - which is where bootstrapping comes from, and why rubber boots often have straps.
This environment will be somewhat hacky, and will most likely have you tie different software components together with lots of duct tape. Noone starts their innovation process with a predefined notion of what the innovation should look like - it just does not work that way. Some chaos is inevitable. But then, as the technology matures, you obviously need to put some processes in place in the environment, make it more structured, and put some guardrails in place. But by then you have all this duct tape! The temptation will be real to add some more of that stuff, and to keep building on top of the fragile foundations of the infrastructure that you put in place in the early days!
This is precisely why the Build versus Buy decision for Feature Stores for ML/AI is such an interesting and important question. Make the decision too early and you hamper innovation. Make it too late and you incur lots of unnecessary technical debt. You don’t want to be getting the balance wrong - as it will be very, very costly. This is why we have been discussing this topic already in previous articles.
What should you consider when comparing Build versus Buy?
When you engage in this consideration, you will find that there are essentially two parts to the evaluation process: a strategic part, which is primarily concerned with the longer term effects of a potential Build decision (both from an infrastructure and a project point of view), and a technical component, which is concerned with the short term AND long term complexities of such a decision. Both are important - but they are very different considerations.
Strategic considerations for your infrastructure
Again, it’s quite important to understand the context of the Build versus Buy decision. The fact is, that for a piece of critical software like a feature store, which will become the beating heart of all of your critical Machine Learning infrastructure, we clearly don’t want to make this component into something that is isolated from the rest of your architecture. You do not want to build a feature store only, but an ML platform centered around or integrated with a feature store. The best known example is Uber, building Palette (its feature store) within the much bigger Michelangelo Platform. But look at another, much smaller and lower profile: Airwallex, an Australian online payment company worked 6 month on the initial stages of their feature store; it still lacks UI, Python or integration with serving and training.
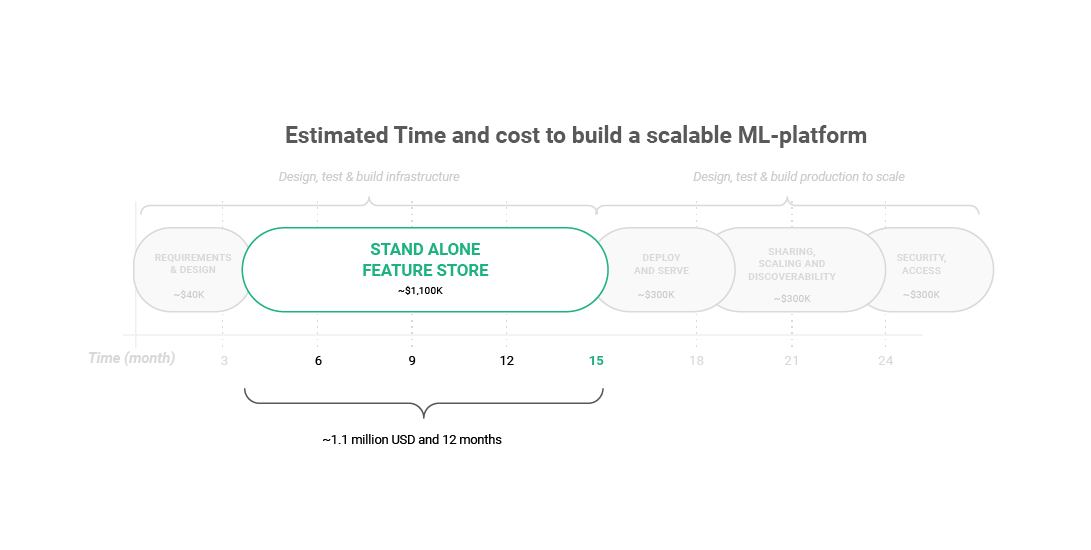
Figure 1: Estimated Time and cost to build a scalable ML-platform: Stand alone feature store
For an ML platform project, the time to get a viable product is estimated to be between 6 months to 2.5 years. For Uber, from the initial introduction of the concept to usage, it took over 2 years. Amit Nene, Tech lead at Palette mentioning “the threshold of usability clustered” after two years as they tried to scale. AirBnB mentioned an initial stage of 3 months of simply deciding what they wanted to build.
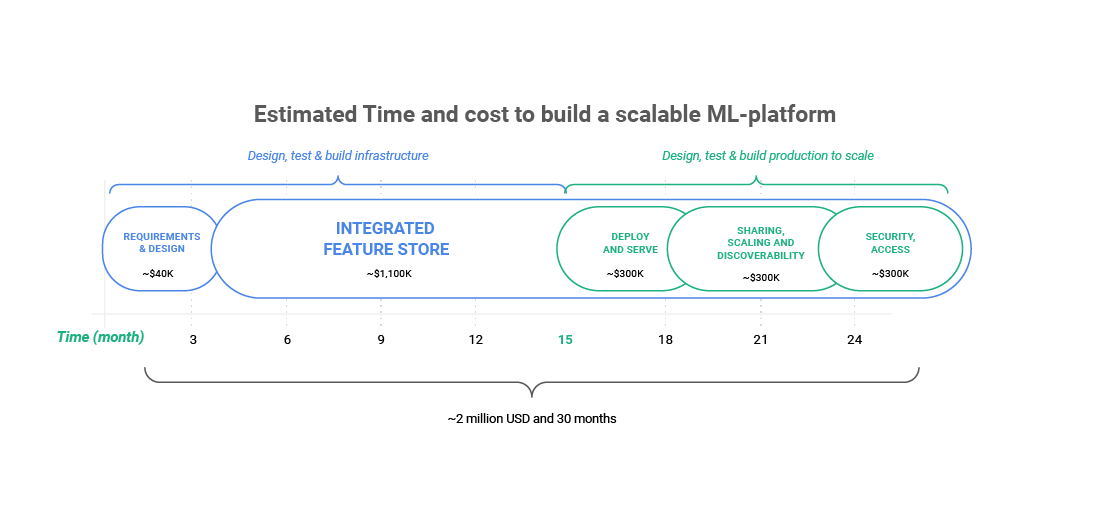
Figure 2: Estimated Time and cost to build a scalable ML-platform: The full journey
On top of that, everyone knows that to be building a feature store, means to never stop building it. You will have to take into account the fact that the initial infrastructure will not be the end of the story. You will build the initial infrastructure, then productionize it, then optimize it, and then scale it.
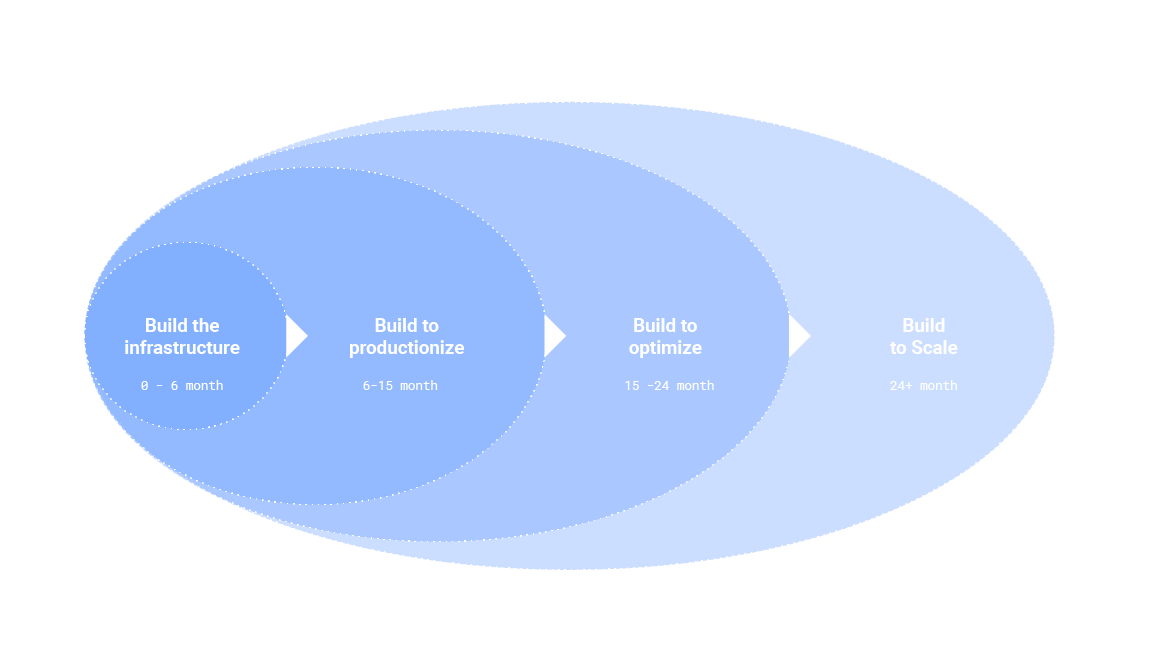
Figure 3: The continuous lifecycle of building infrastructure. Building means never stop building.
None of these phases are trivial or easy, as we will see when we discuss some of the technical considerations below.
When you boil down the strategic considerations for your infrastructure, it really comes down to an evaluation of the Maintenance Burden & Total Cost of Ownership (TCO): clearly, this is something that every mature IT organization will consider. Ultimately, this is related to the potential technical debt that this organization will want to incur, given the significant costs that could be associated with this down the line. It’s important to consider not just the short term, but also the longer term implications of a build vs. buy decision.
Strategic considerations for your projects
The strategic considerations for your infrastructure, obviously also impact your shorter term project goals. Think about things like the effort required for getting models in production: in the figure below, we clearly see that the blue line does not make sense. You cannot keep incurring more and more additional costs for putting more and more projects in production. Nobody wants to fund projects with these characteristics: it would be completely unaffordable and, therefore, unacceptable.
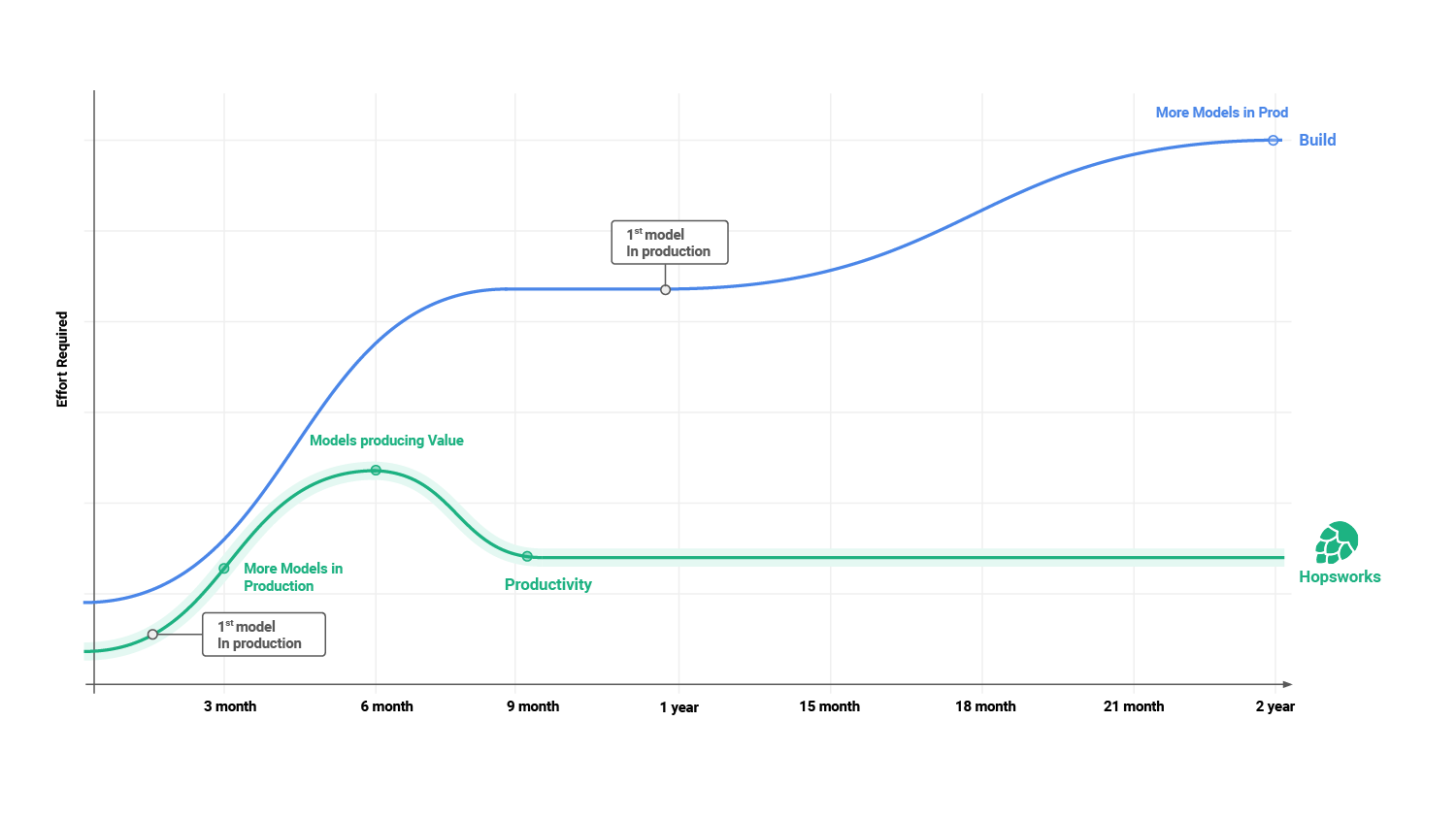
Figure 4: The effort required for models in production over time
What we want is something more like the green line: the effort required to put models in production should flatten, and effectively come down and become flat. This is partly caused by the productivity curve of ML and data engineers that are working on ML and AI projects: take a look at the blue and green lines below: what you don’t want is for every new project to be a struggle where productivity takes a hit.
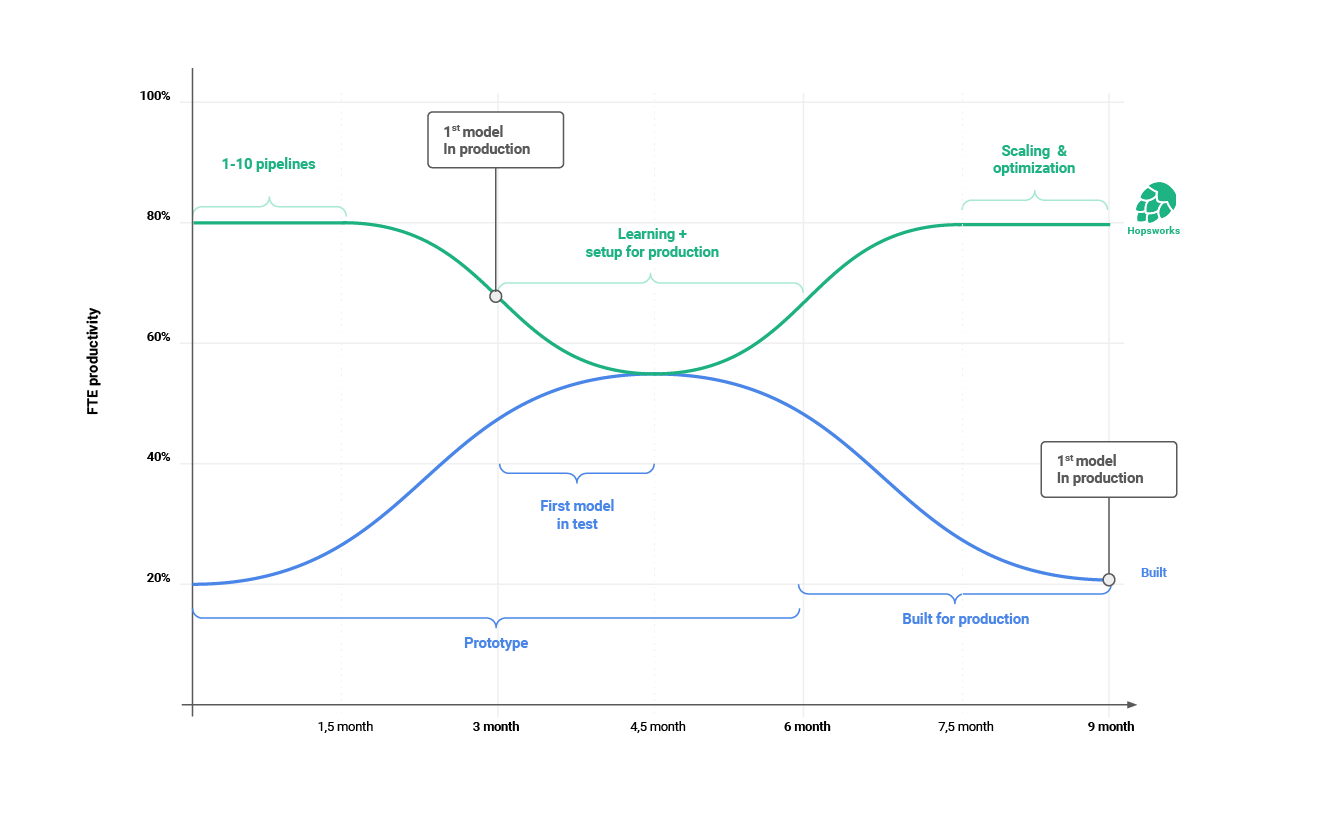
Figure 5: FTE Productivity over time
What we want to optimize for is, that, as we gain more experience with production-ready machine learning systems, the complexity goes away, fades into the background, and becomes an obvious and trivial piece of work that causes little or no additional work. We want people to spend more time on actually machine learning model development, and less on the technical trivialities of feature engineering:
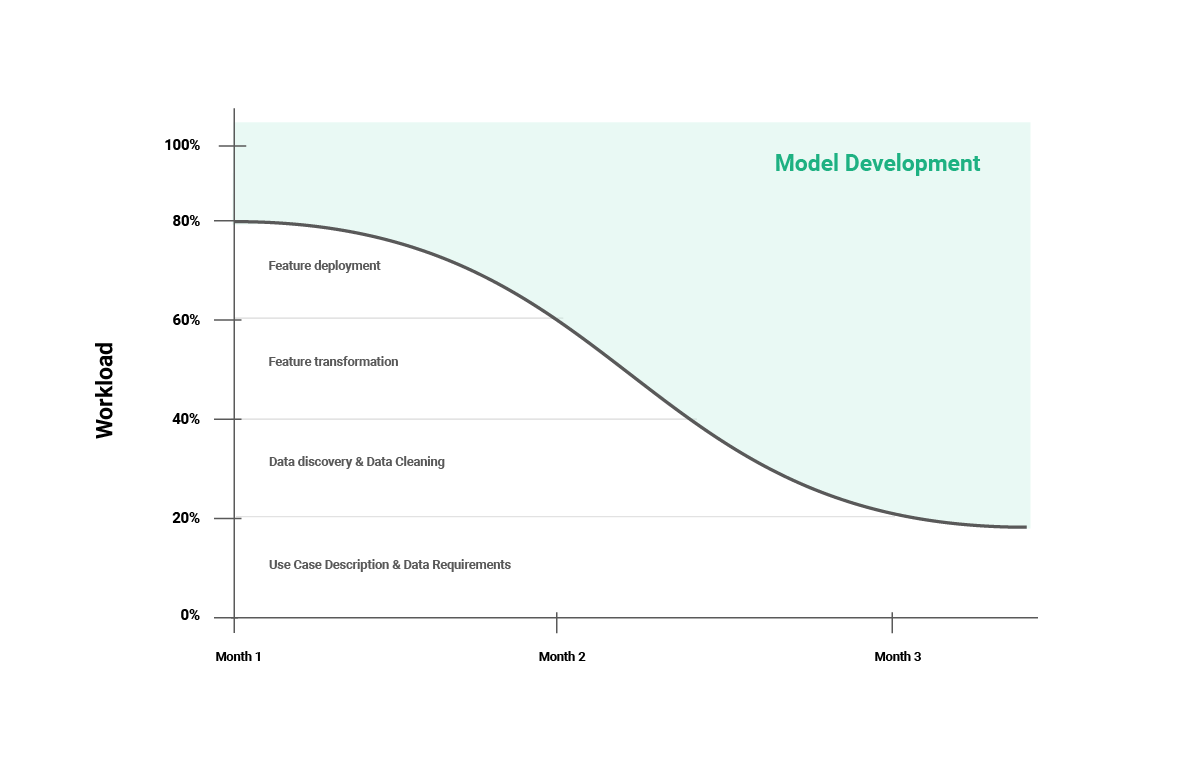
Figure 6: Data Scientists time on feature engineering
All of the above are strategic considerations that will massively impact your ability to deliver value-added projects for your organization. Which then obviously still leaves us to consider one last point: the technical complexity of building a feature store.
Technical considerations
Clearly, a piece of infrastructure software like a Feature Store, which will underpin all ML/AI applications that the organization would choose to develop, has a significant amount of technical complexity associated with it. It’s important to consider this, and to investigate the most crucial domains in which a “build” approach could encounter unexpected technical challenges. Let’s go through some of these characteristics one by one.
- Offline / Online sync: one of the key characteristics of a feature store is that it will both contain the historical data of a feature dataset, as well as the most recent values. Both have their use and purpose, and need to be kept in sync inside the feature repository. Feature Stores like Hopsworks do this for you, but in a “build” scenario you would need to take this into account and do all the ETL data lifting of keeping two data stores in sync and aligned, yourself.
- Reporting and search: in any large machine learning system where you have dozens/hundreds/thousands of models in production, you would want and need the feature data to be findable, accessible, interoperable, and reusable - according to the so-called “F.A.I.R.” principles that we have described in this post. This seems easy - but if you consider all of the different combinations that you could have between versions of datasets, pipelines and models, it is clear that this is not a trivial engineering assignment.
- Metadata for versioning and lineage: similar to the previous point, a larger ML/AI platform that is hosting a larger number of models, will need metadata for its online and offline datasets, and will need to accurately keep track of the versions and lineage of the data. This will increasingly become a requirement, as governance for ML/AI systems will cease to be optional. Implementations of and compliance with the EU AI Act, will simply mandate this - and the complexity around implementing it at scale is significant.
- Time-travel and Temporal joins: if we want to make the predictive results of our ML/AI systems explainable, we will need to be able to offer so-called “time travel” capabilities. This means that we can look at how a particular model yielded specific results based on the inputs that it received at a specific point in time. Feature Stores will need to offer this capability, on top of the requirement to guarantee that the models yield accurate and correct information at a given point in time - something we call “Point-in-time correctness”. Again, the technical complexity of implementing this yourself is not to be underestimated.
- Component integration and interoperability: a machine learning system will have many different components that will need to be integrated and configured as a system in order for you and your organization to effectively and efficiently seize the value of Machine Learning for your environment. That integration, not just once but forever after as new versions of each of the components are released and added to the mix, will be an important technical challenge that should be added to your considerations.
We hope to have demonstrated with this short overview that the technical complexity to building your own feature store platform is significant, and not to be underestimated. The whole reason for the feature store architecture to be considered as a new infrastructure component for ML / AI implementation, is that this architectural component makes classic machine learning so much easier:
The 2nd Why in Build versus Buy
In one of the previous discussions, we argued that the Build versus Buy question is actually to be understood in the context of “three why’s”. First, a customer should of course understand if they actually need a feature store infrastructure. Secondly, they need to decide why, and when, they should consider building or buying a feature store component to that infrastructure. And then thirdly and lastly, a client would decide which particular implementation of a Feature Store solution, like Hopsworks, would be most appropriate for their environment. We called these 3 questions the Golden Circle of Feature Stores, and you find the summary overview below. In the second, blue layer of the diagram below, we considered some of the reasons / criteria that would warrant you to look at the BUY option instead of the BUILD option.
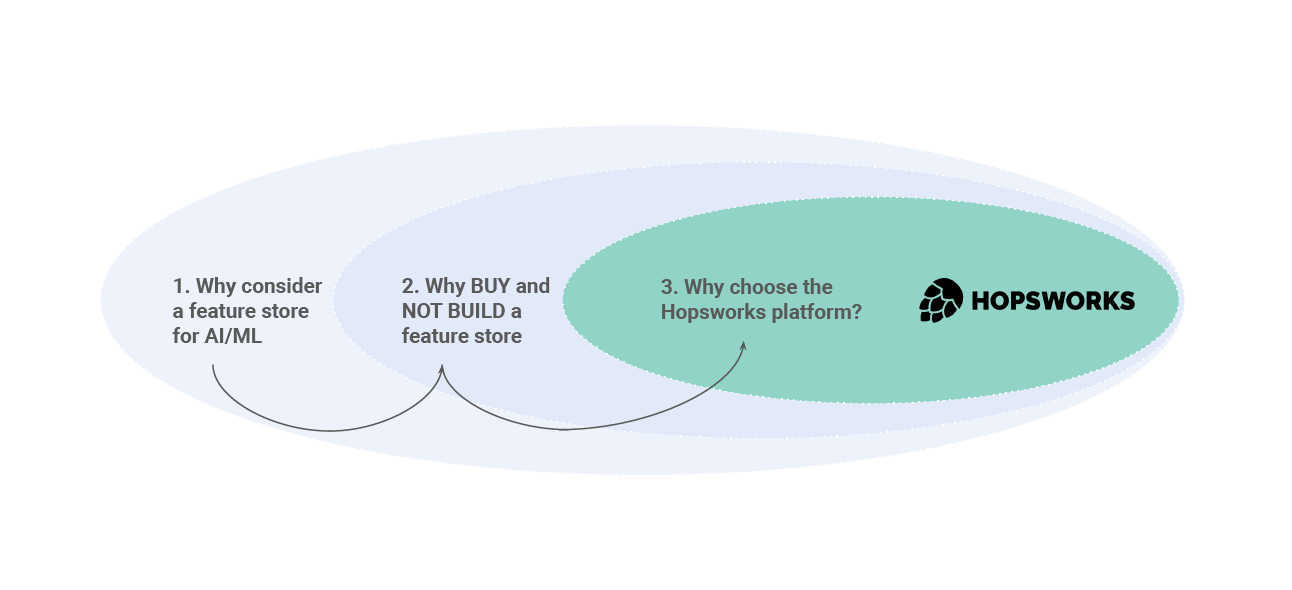
Figure 7: The Golden Circle of Feature Stores
As articulated above, some of these reasons have also been covered in a previous article, as well as in the follow-on article that we authored afterwards.
How Does Hopsworks Help?
Different stages have different engineering needs. It all can be simplified in two axes:
Engineering requirements & Production requirements. For classic ML structures, one scales with the other. As production requirements grow in complexity so do the platform capabilities and open source systems get less and less practical as the whole structure scales. During the Feature Store Summit, Uber indicated that they would trade potential optimizations with open source solutions to avoid the trade off operational burden. This is why we think that Hopsworks should make it easier for you, the user, and your organization to get to value more quickly, easily, with fewer headaches - whatever maturity stage you may find yourself in.
Hopsworks offers you 3 different deployment options, ranging from a serverless endpoint to a custom installation in your air-gapped on-prem environment, that will help you leverage the power of a professional, purpose built, modular, pre-configured machine learning feature store system.
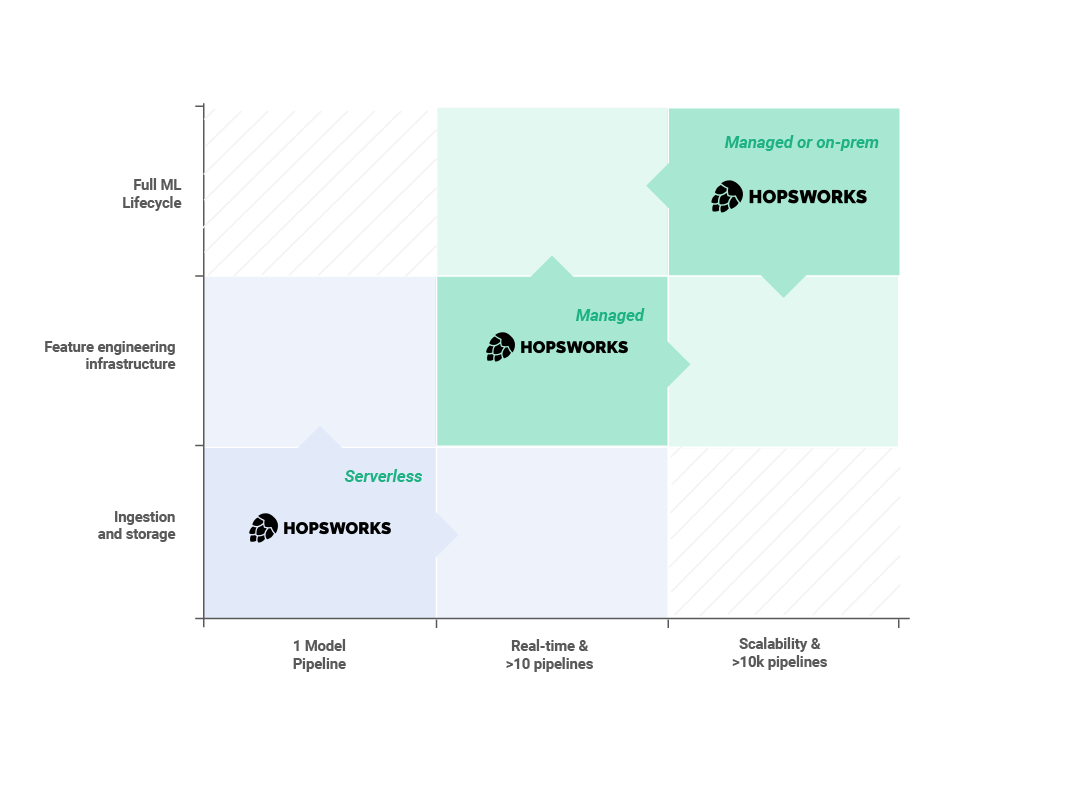
Figure 8: Different stages of engineering needs in relation to product requirements
Summary
When building AI systems from scratch, companies often end up duct-taping together a software solution as there is no predefined notion of what innovation looks like. Knowing which software solution to bring in, where, and when, and what you are able to build on your own is a fine balance. In this article, we have looked at strategic and technical considerations for building versus buying a feature store platform for ML/AI. We examine components that have short-term and long-term effects, respectively, on a company’s tech journey and where and when feature stores are beneficial.