Deep Learning: Use a Cluster Manager for GPUs
If you are employing a team of Data Scientists for Deep Learning, a cluster manager to share GPUs between your team will maximize utilization of your GPUs.

Anti-Patterns for Sharing GPUs
At Hopsworks we talk to lots of customers about how they share GPUs between their teams, and surprisingly many companies still resort to using Google calendars or fixed schedules to share GPUs. Many companies do not even share GPUs across lines of business, which is even worse. It goes without saying that these approaches are bad for getting the most out of your investments in GPUs and bad for developers – as they may not be able to use all available GPUs when they need them.
GPUs-as-a-Resource
Resource managers are used to manage the compute and GPU resources available in a Data Center or organization. Developers can run an applications using a Resource Manager by submitting an application request to the cluster: please start my application with X containers, where each container has Y CPUs and X GB of memory. The Resource Manager then schedules the application for execution when it can allocate those resources to the application. For Deep Learning, we need GPUs, and some modern Resource Managers support GPUs-as-a-Resource, where you can also request that a container has N GPUs attached to it. Deep Learning applications can make special demands on Resource Managers. For distributed training (with >1 GPU), applications request all of their GPUs at the same time – so-called, Gang Scheduling. However, for hyperparameter optimization, applications can start work with just 1 GPU and make use more GPUs as they are incrementally allocated by the Resource Manager. For both Gang Scheduling and Incremental Allocation to work correctly, support is needed in both the application software and the Resource Manager.

Distributed Training needs Gang Scheduling support from the Resource Manager to give it its GPUs at the same time. If Gang Scheduling is not supported or partly supported, Distributed Training can either be starved indefinitely or deadlock the Resource Manager.

Hyperparameter Optimization can use Incremental Allocation of GPUs by the Resource Manager. It can make progress with just 1 GPU or go faster with more available GPUs.
Machine Learning Workflows
When machine learning migrates from R&D into production, model training typically becomes one stage in a longer machine learning workflow that involves (1) collecting and preparing data for training, (2) training/validating the models, and (3) deploying the models for serving. If data volumes are large, stage (1) may require many containers with lots of CPUs for ETL and/or feature engineering. Spark/PySpark is a popular framework for this stage. For stage (2), training can be done with frameworks like PyTorch or Keras/TensorFlow. Distributed training can be done with the help of frameworks like HopsML. Finally, stage (3) involves deploying models to production for serving. This may be done on a different cluster or the same cluster. Kubernetes is a popular framework for model serving, due to its support for load-balancing and elasticity.
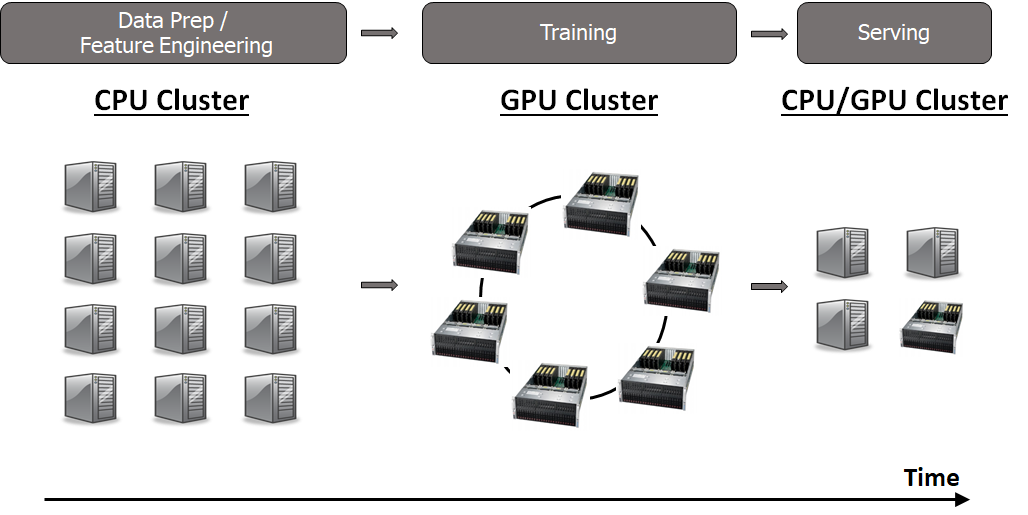
A Machine Learning workflow, consisting of a DataPrep phase, a training phase and a model serving phase will require different sets of resources from the cluster. DataPrep typically requires CPUs, training requires GPUs, and serving requires CPUs (and maybe GPUs for low latency model serving).
YARN, Mesos, Slurm, Kubernetes
There are a number of Data Center Resource Managers that support GPUs-as-a-Resource:
- YARN
- Kubernetes
- Mesos (DC/OS)
- Slurm
YARN is the dominant resource scheduler for on-premise data lakes, and since release 3.1 of Hadoop, it has full support for GPUs-as-a-Resource. Hops’ YARN is a fork of Hadoop that has supported GPU-as-a-Resource since October 2017. Neither version support gang scheduling, but Hops’ layers gang scheduling semantics over YARN using PySpark and the HopsML API. Essentially, training applications are run in a single map operation that is gang scheduled by HopsML on PySpark Executors. In Spark 2.4, there is a new barrier execution mode to also support Gang Scheduling for distributed training.
Mesos does not support gang scheduling, but, similar to how HopsML adds support for gang scheduling using Spark to YARN, Uber have added support gang scheduling for distributed training using Spark in a platform called Peleton. Unfortunately, Peleton is currently not open source, and Uber are talking about migrating Peleton to Kubernetes. Kubernetes is currently working on supporting gang-scheduling (or co-scheduling as they call it), and it can be expected to be included in frameworks like KubeFlow some time later in 2019. Slurm is traditionally used for HPC clusters, and is not widely adopted in the cloud or for data lake clusters, but supports gang scheduling natively.
We now discuss how Resource Managers are used by Data Scientists from two open-source frameworks: KubeFlow on Kubernetes and Hopsworks on Hops YARN.
Data Scientist experience with KubeFlow
Kubernetes provides support for creating clusters with GPUs using a cluster specification in YAML.
An example:
Data Scientists typically do not use Kubernetes directly, as this involves too much devops: YAML specifications, Dockerfiles to install Python libraries and other packages. Instead, Kubeflow is typically used to provision clusters and train deep neural networks using GPUs from the command-line.
First, Data scientists can use the command-line you can check the availability of GPUs in the cluster.
Using commands such as:
Then, assuming you have installed Kubeflow, such as using this tutorial, you can train deep neural networks using Kubeflow on GPUs using commands such as the following.
Kubeflow commands:
Data Scientist experience with Hopsworks
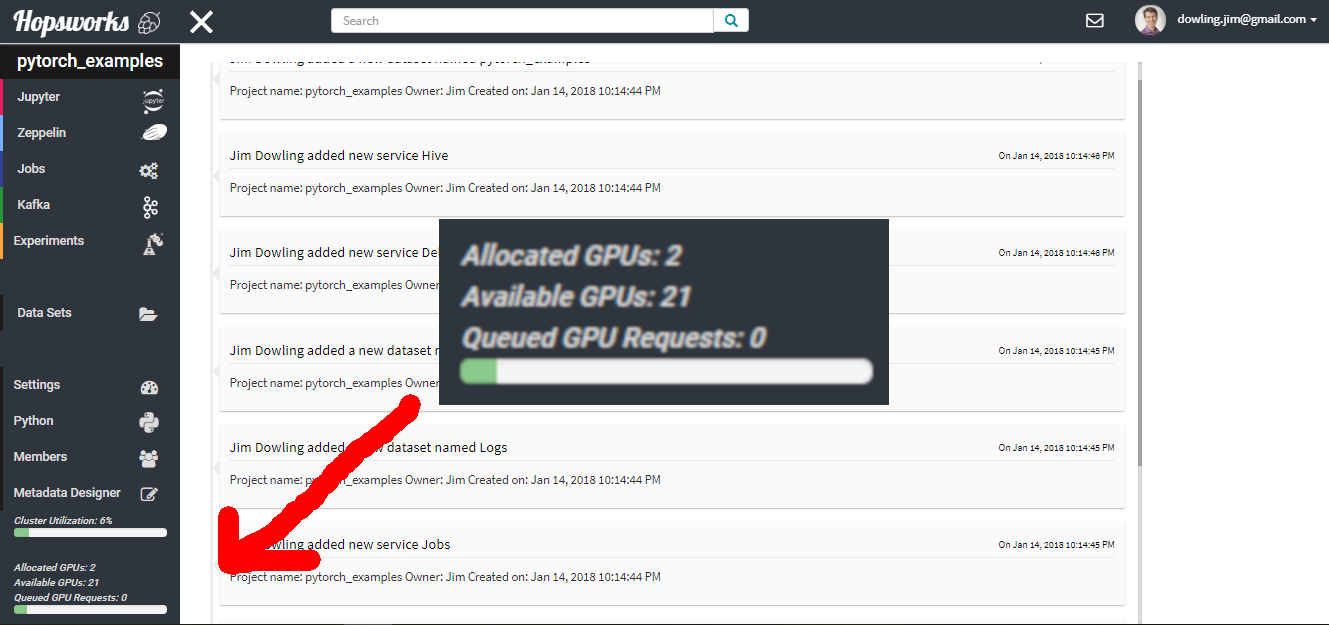
Hopsworks is our scale-out platform for machine learning and data analytics, based on a next-generation distribution of Hadoop called Hops. In the Hopsworks UI, a Data Scientist can quickly see the number of available GPUs in the cluster:
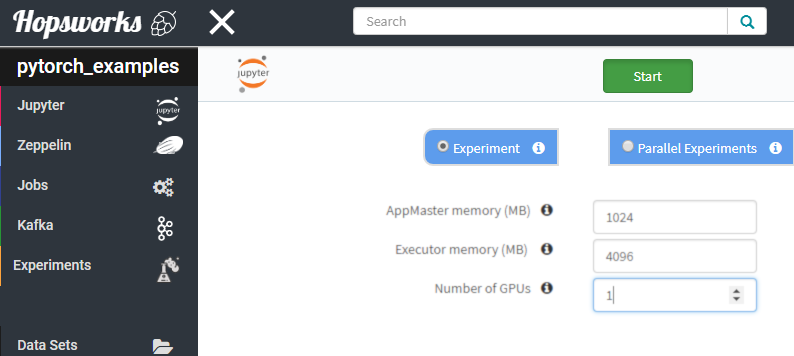
Launching a cluster with a number of GPUs is as simple as deciding on the number of GPUs and the amount of memory to allocate to the Application Master and the Executor:
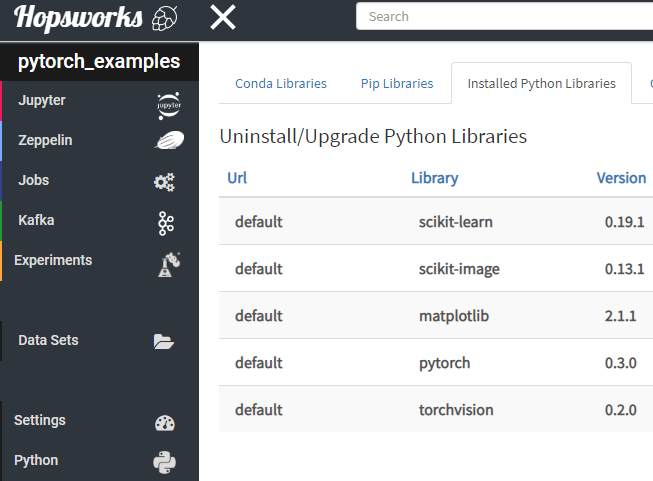
Finally, a Data Scientist can install Python libraries using pip and conda (there is no need to write a Dockerfile):
Machine Learning Workflows in Hopsworks
In Hopsworks, we support YARN for both (1) DataPrep and (2) Training stages, and (3) Kubernetes for model serving, see Figure below. Typically, DataPrep is done on PySpark or Spark and the output of that stage is that training data is written to our distributed filesystem, HopsFS. Training is typically done by launching PyTorch or TensorFlow/Keras applications using PySpark, and trained models are stored on HopsFS. Finally, models are served in Kubernetes by reading them from HopsFS.
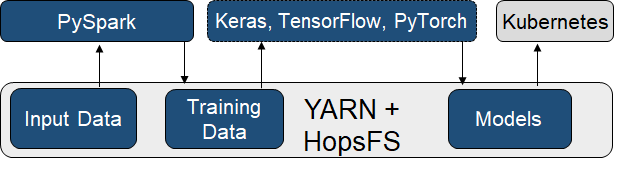
A Machine Learning workflow in HopsML can run the DataPrep stage on PySpark, (Distributed) Training on TensorFlow/PyTorch, and Model Serving on Kubernetes. A distributed filesystem, HopsFS, is used to integrate the different stages, and YARN is used to allocate both CPUs for the PySpark stage and GPUs for the training phase.
Is a Cluster Manager enough?
In our talk at the Spark Summit Europe 2018, we argued that a cluster manager by itself is not enough to make the most efficient use of your GPUs. Data scientists may write Python programs in Jupyter notebooks where they both train and visualize using the same resources. For example, a developer can write a cell in Jupyter to train a network on one or more GPUs, then write a subsequent cell to evaluate the performance of that model, and then have one or more cells to visualize or validate the trained model. While the Data Scientist is visually analyzing the trained model, she is unnecessarily using valuable GPU resources. GPUs should be freed immediately after training/evaluation has completed – unrelated to how you implement gang scheduling. You can make sure GPUs are freed up immediately by using (1) discipline and a distributed filesystem or (2) HopsML. For (1), developers can write their trained models and evaluation dataset to a distributed filesystem and shutdown the containers used to train the model when training has finished. Then open a new Python notebook with access to the same distributed filesystem to visually inspect the trained model. For (2), in HopsML, developers put their training code in a function in Python which is run on a GPU and when the function returns its associated GPU is released after a few seconds on inactivity. HopsML implements this behaviour using Dynamic Executors in PySpark – for more details check out our blog on 'Optimizing GPU utilization in Hops'.
An example of how to structure your code in HopsML is shown below:
Summary
A cluster manager, such as YARN for Hopsworks, will help you get the most value from your GPUs and keep your Data Scientists happy by enabling them to be more productive with both distributed training of models and hyperparameter optimization.