How to use external data stores as an offline feature store in Hopsworks with Connector API
In this blog, we introduce Hopsworks Connector API that is used to mount a table in an external data source as an external feature group in Hopsworks.

Introduction
Enterprise data in the cloud is stored in a plethora of data storage services, from data lake based services like AWS S3, ADLS, and GCS, to data warehouses like Redshift, BigQuery, Snowflake, and Delta Lake - to name just a few. In this blog post, we explore how we can easily connect Hopsworks to commonly used data stores and use them as an offline store for features in Hopsworks. In effect, Hopsworks can be a virtual feature store, where you leverage your existing data lake or warehouse as an offline store, and Hopsworks manages both the metadata and online features.
Before we dive into the Connector API, let's briefly understand what an external feature group is.
A feature group is a table of features (columns) that are updated by a feature pipeline program. Feature stores provide two different APIs for reading features:
- an Offline API to read large volumes of historical feature data for training or batch inference;
- an Online API to read precomputed features at low latency for real-time inference.
Given these requirements, most feature stores are implemented as dual database systems, with one column-oriented offline store implementing the Offline API and a row-oriented online store implementing the Online API. The online store is a low-latency database that stores and serves the latest values of features. The offline store serves as a data warehouse to store historical values of features and requires low cost storage of large data volumes, efficient push down filter queries, efficient point-in-time Joins, and time-travel for features to be able to read historical values for features.
External feature groups enable the benefits of centralized feature management and reuse along with the storage of features on existing data platforms. Often, Enterprises have built feature pipelines on an existing data lake or data warehouse, and would like to reuse those features in a feature store without rewriting the feature pipelines. Also, many Enterprises do not like to introduce an additional data store, and would like to keep their features on their existing data platform. For these scenarios, external feature groups are an attractive proposition.
Connector API
The Connector API enables you to mount an existing table in your external data source (Snowflake, Redshift, Delta Lake, etc) as an offline feature group in Hopsworks. This means you can use its features exactly like any other offline feature, for example, joining different features together from different data sources, to create feature views, training data, and feature vectors for online models.
In the image below, we can see that Hopsworks Feature Store (HSFS) currently supports a plethora of data sources, including any JDBC-enabled source, Snowflake, Data Lake, Redshift, BigQuery, S3, ADLS, GCS, and Kafka.
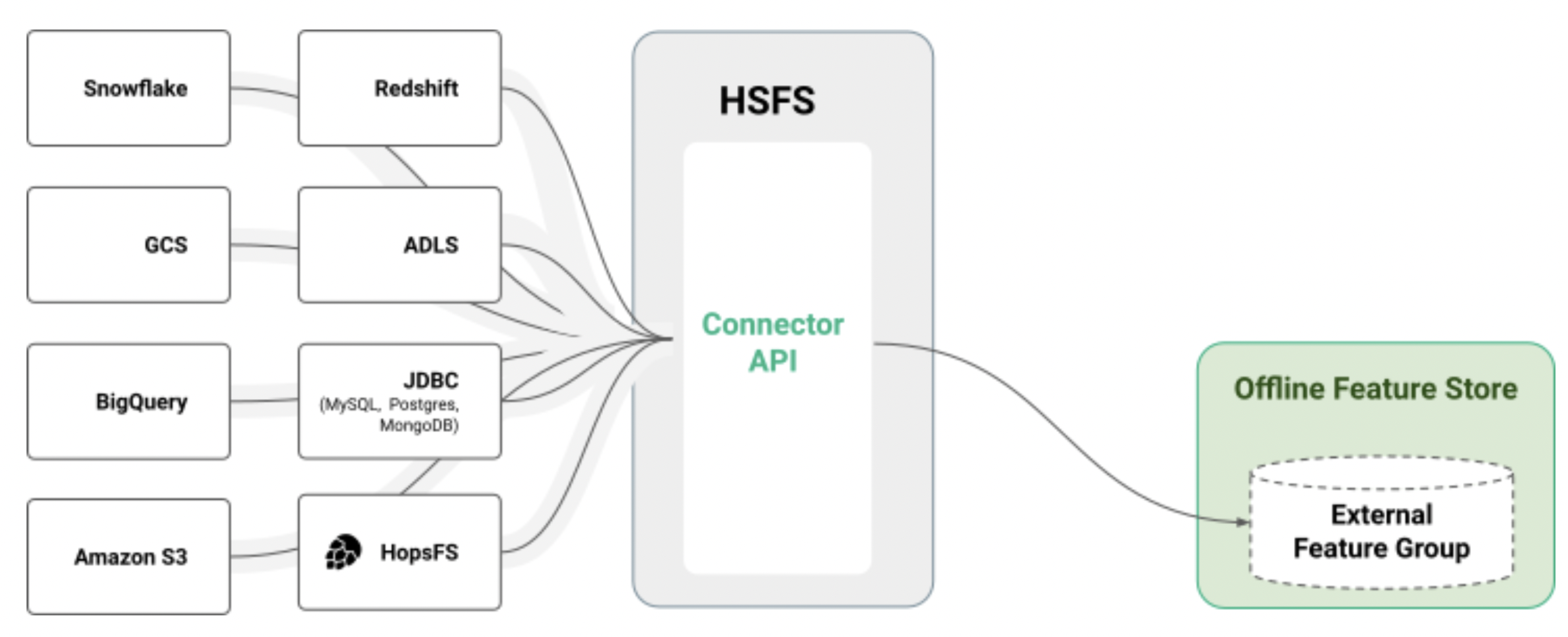
Figure 1. Connector API
Hopsworks only stores the metadata about such features, but not the actual data itself. This opens up the possibility to use your existing data storage and utilize it as an external table without the hassle of migrating the data into Hopsworks. If you do decide to store your offline features in Hopsworks, they are stored in Hudi tables in S3/GCS/ADLS.
The Connector API requires a storage connector, which securely stores the authentication information about how to connect to an external data store, to enable the feature store client library, HSFS, to retrieve data from the external table. Once a storage connector is created for the desired data source, it can seamlessly be used to create external feature groups from that data source. Storage connectors are also used in other applications like reading data for batch inference or streaming sources and also for creating training datasets.
We now take a look at an example of how to create an external feature group programmatically using the Connector API.
Create a storage connector
Our first step is to create a storage connector from the UI. In the screenshot below, we see an example of creating a storage connector for GCS. Detailed information about how to create a storage connector is found here.
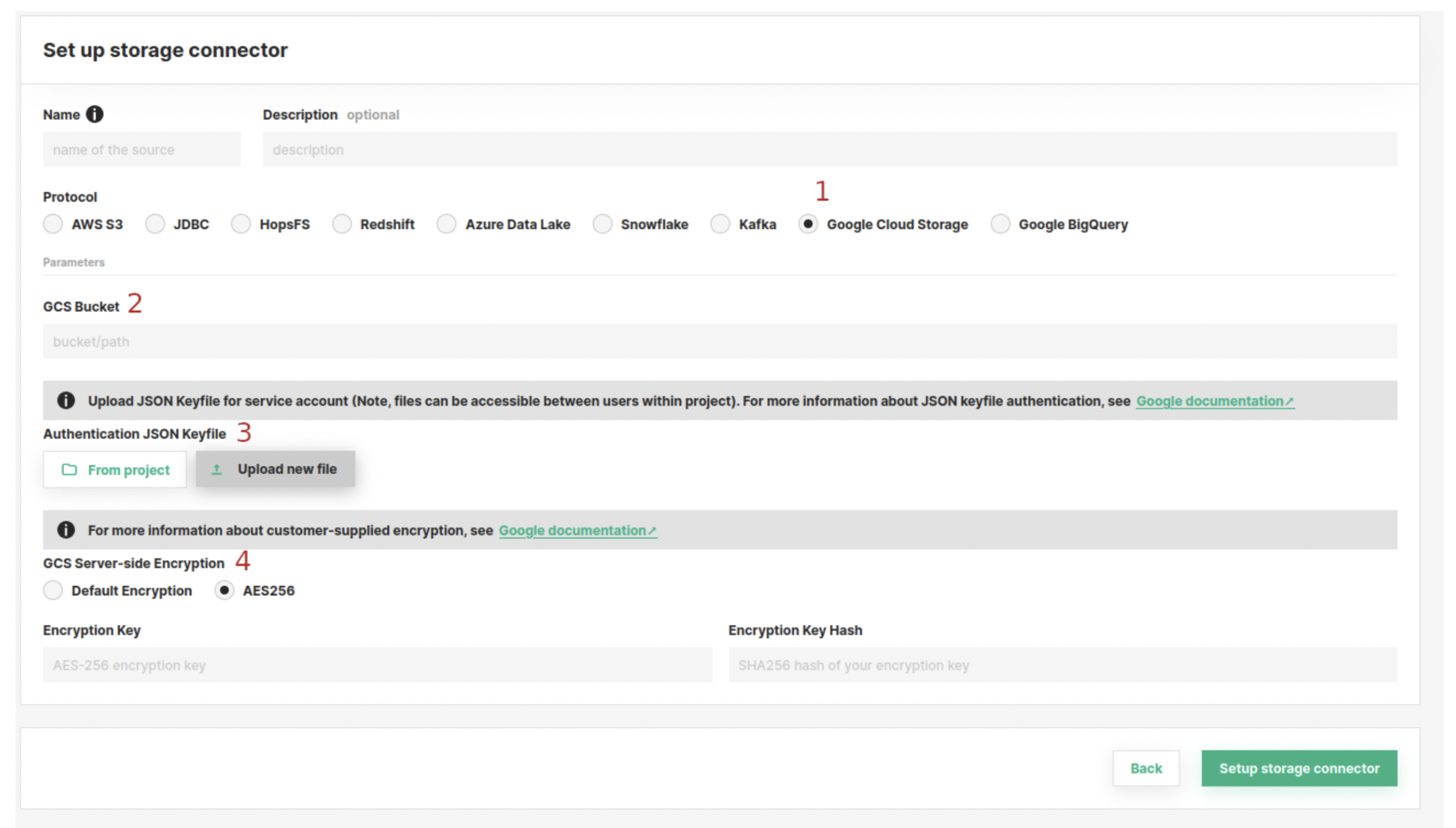
Figure 2. Hopsworks UI - Storage Connector
We retrieve the storage connector object using the feature store connection object as follows:
Note, the above connector object contains only metadata for the external data source. There is no active connection yet to the external data source, so the call returns quickly.
Create external feature group
The method call to create an external feature group is create_external_feature_group. It takes name as mandatory parameter, for the name of the feature group being created. Depending on the type of the external data source, we can set either the path or query argument, as shown below.
- Data Lake based external feature group
For data lake based external sources (AWS S3, GCS), the path to the data object to be used as an external feature group needs to be set. It can be set while creating the storage connector in the bucket field or setting it to the path argument, which is appended to the bucket path mentioned while creating the storage connector. Secondly, the format of the data needs to be set in data_format argument, which can typically be any spark data format (csv, parquet, orc, etc.).
- SQL based external feature group
For external sources based on a data warehouse (e.g., JDBC, Snowflake, Redshift, BigQuery) the user provides a SQL string for retrieving data and even computing the features. Your SQL query can include operations such as projections, aggregations, and so on, including.
We can also optionally specify which columns should be used as primary key, and event time.
The create method creates the metadata object of the feature group but does not persist it. Upon calling save, the feature group metadata gets stored in Hopsworks. At this point, Hopsworks will also execute the SQL query and compute descriptive statistics and feature distributions over the data returned, saving the results as metadata.
That's it! This creates an external feature group in Hopsworks while the actual data still lives only in the external storage!
Summary
The Connector API makes it very easy to connect to an external data source and create offline feature groups in Hopsworks. Hopsworks supports a large variety of external data sources like Snowflake, Data Lake, Redshift, BigQuery, S3, ADLS, GCS, and Kafka.
These external feature groups can be used like any other offline feature group, for example, to create feature views, batch inference data, and training data for models. This brings up the benefit of leveraging existing data storage and reading features seamlessly to Hopsworks as needed, without the cost and operational overhead of data migration.
For more information on the Connector API, checkout Hopsworks Documentation.