How to Transform Snowflake Data into Features with Hopsworks
Learn how to connect Hopsworks to Snowflake and create features and make them available both offline in Snowflake and online in Hopsworks.

Before you get started, make sure you have created a free account on hopsworks.ai. Hopsworks.ai gives access to a managed cloud based deployment of the Hopsworks Feature Store, with free Hops credits to use.
Storage connector
The first step to integrate Hopsworks with an external Snowflake cluster is to configure the Snowflake storage connector. Hopsworks provides storage connectors to securely centralize and manage connection configurations and credentials to interact with external data stores. In this way users do not have to hardcode passwords and tokens in programs, and can control which users are given access to external data stores.
Hopsworks provides a storage connector and drivers for Snowflake. The storage connector can be configured using the feature store UI as illustrated below:
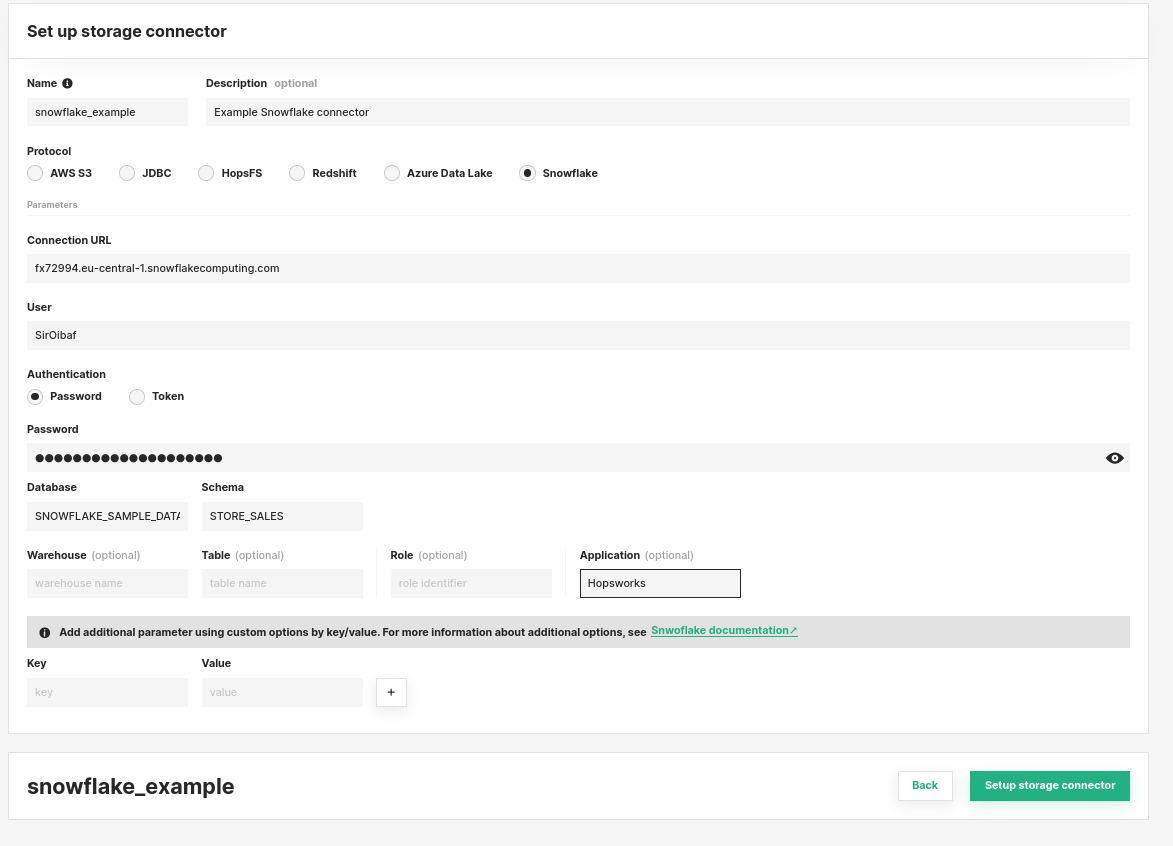
To configure the connector you need to provide the Connection URL of your cluster. The Snowflake storage connector supports both username and password authentication as well as token-based authentication. Token-based authentication is required when using OAuth to authenticate with Snowflake. To be able to use token-based authentication from Hopsworks, you will have to enable it on your Snowflake cluster, as explained in the Snowflake documentation.
The Hopsworks Snowflake storage connector allows users to specify several additional fields, though only two are mandatory: the database field and the schema field.
The role field can be used to specify which Snowflake security role to assume for the session after the connection is established.
The application field can also be specified to have better observability in Snowflake with regards to which application is running which query. The application field can be a simple string like “Hopsworks” or, for instance, the project name, to track usage and queries from each Hopsworks project.
Additional key/value options can also be specified to control the behaviour of the Snowflake Spark connector. The available options are listed in the Snowflake documentation.
On-Demand Feature Groups (External Tables)
Once the storage connector is configured, users can start defining on-demand feature groups. On-demand feature groups are external tables that can be defined on external SQL databases or tables stored on object stores (such as Parquet or Delta lake tables on S3 object storage). The data for an on-demand feature group is not copied into Hopsworks. Instead, it is stored in-place in the external data store, and is only read from the external store “on-demand”. For example, when its feature data is used to create training data or for batch inference. While data remains on the external store, the feature group metadata is stored in Hopsworks. More in-depth documentation for on-demand feature groups can be found here.
On-demand feature groups can be used in combination with cached feature groups to either create training datasets or to retrieve large volumes of feature data for batch inference.
An example of on-demand query definition is given below:
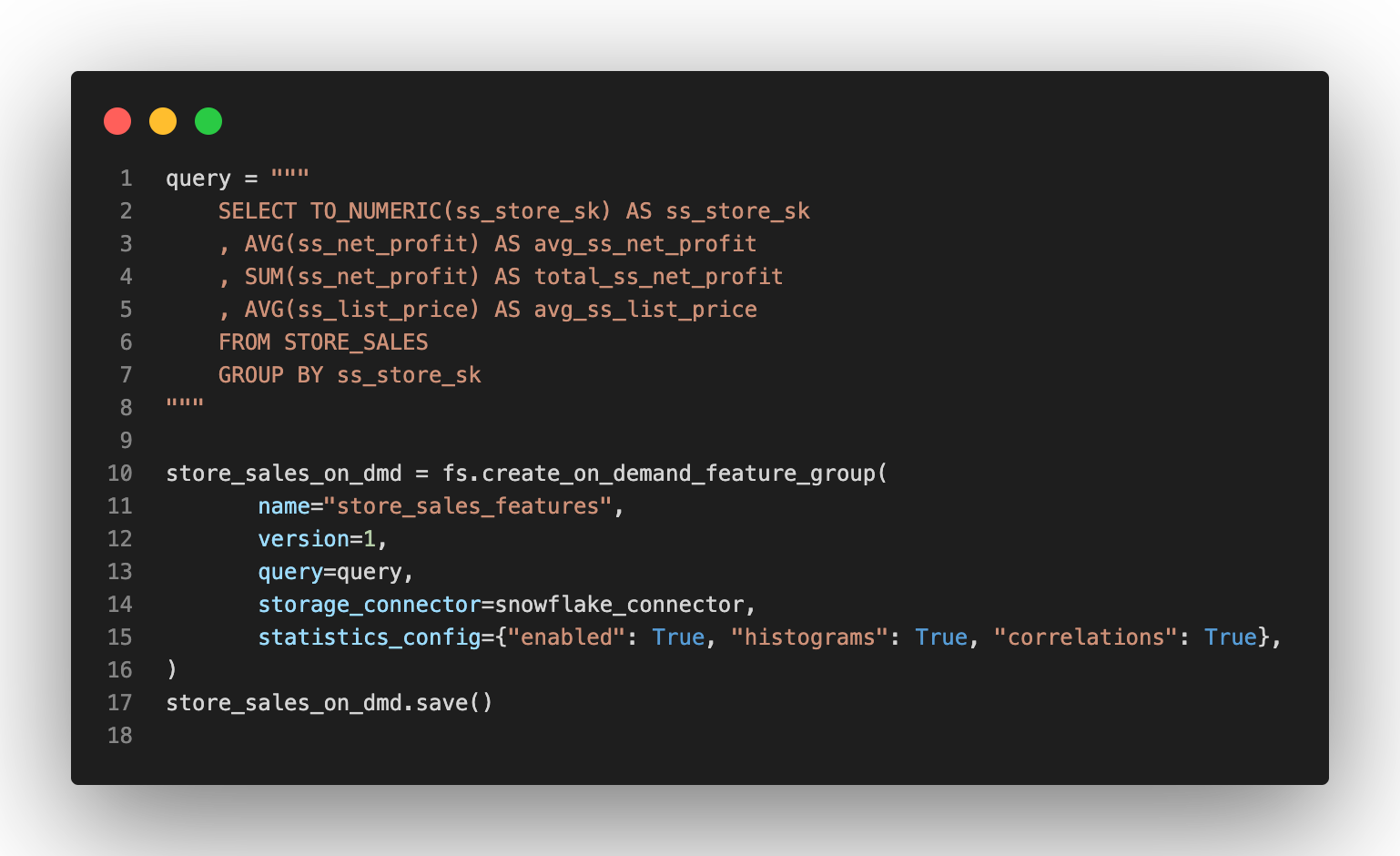
The above code defines avg_ss_net_profit, total_ss_net_profit and avg_ss_list_price as features in the store_sales_features feature group, and registers the feature group in the feature store.
Each time features are read from the on-demand feature group, the above query is pushed down to Snowflake for execution. When creating training data in a Spark program, the query result is returned using the Snowflake spark connector as a DataFrame, that can then be joined with features and then optionally materialized to a data store as machine-learning ready files (e.g., in .tfrecord file format).
Users can also compute statistics and define validation rules on the on-demand feature group data. More information can be found in our documentation. For data validation, in the case of an on-demand feature group, as the data is updated externally, a Spark program needs to be periodically run to explicitly validate the data. More details about data validation and alerting will be covered in a future blog post.
Create a Training Dataset
Training datasets are a concept of the Hopsworks Feature Store that allows data scientists to pick features from different feature groups, join them together and get the data in a ML framework friendly file format that can be used to train models in TensorFlow (.tfrecord), Pytorch (.npy), SkLearn (.csv), and others.
The training dataset concept provides additional benefits, such as having a snapshot of the data at a particular point in time, being able to compute statistics on that snapshot and compare them with the statistics on the incoming data being submitted for predictions.
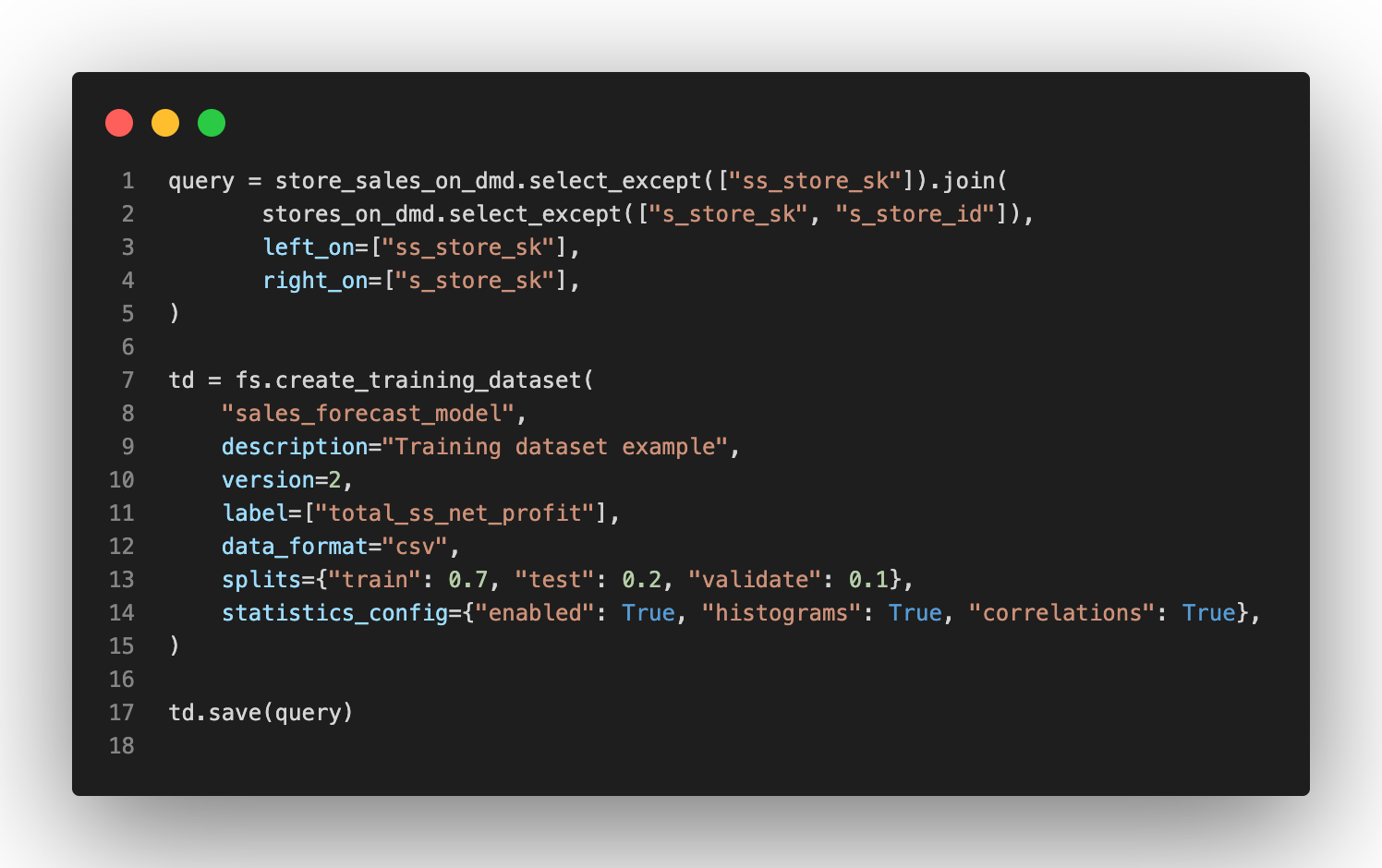
You can create a training dataset either using the HSFS library or using the user interface . In the example below, we join features from two different on-demand feature groups defined over the Snowflake database. It is also possible to join features from cached feature groups as well.
The training dataset in the example below is stored in TFRecords format ready to be used by a TensorFlow or Keras model. The training dataset itself can be stored on external stores like S3 or ADLS, as explained in the documentation.
Online Serving
After having trained the model and put it into production, users need to leverage the online feature store to provide the features required to make predictions.
Snowflake is a columnar database, not designed to provide low-latency access to data. To satisfy the latency requirements that a production system requires, we make the feature data available online using RonDB. RonDB is the database powering the Hopsworks online feature store.
To make the data available online, we need to create a cached feature group and set the online_enabled flag to True. For online storage, we don’t need to track data statistics. The online feature group will contain only the most recent values of each entity (e.g., the last feature vector available for a given store_id or customer_id).
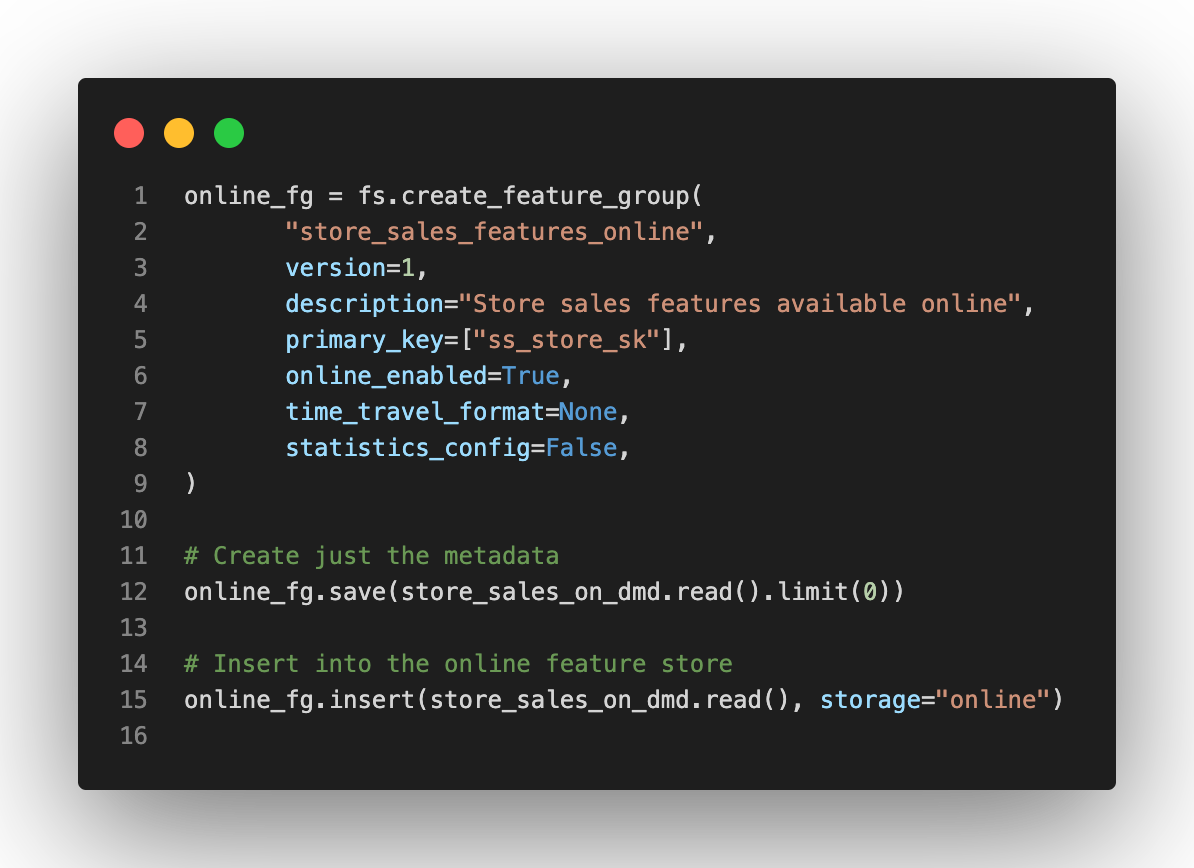
The above example makes the data available only at a specific point in time (i.e., the moment the online feature group was created). In Hopsworks, users can define a Spark/Python program that periodically refreshes the data according to the requirement of the specific use case. Hence making the most recent data always available online.
Examples
This blog post is also available as Jupyter notebooks that users can use to get started with the Hopsworks Snowflake connector. The example notebooks are available for Python and Scala.
You can run it for free by registering an account on Hopsworks.ai and receiving the free credits to experiment with the Hopsworks Feature Store.