5 Machine Learning Myths Debunked
Common Misconceptions about MLOps, LLMs and Machine Learning in production
The rapid development pace in AI is the cause for a lot of misconceptions surrounding ML and MLOps. In this post we debunk a few common myths about MLOps, LLMs and machine learning in production.

As AI and machine learning (ML) are in a state of constant change and development, new frameworks, technology and implementations continuously appear. To navigate the influx of information can be challenging, making it easy to misunderstand or confuse a particular machine learning concept. In this article we attempt to highlight and break down some common misconceptions about MLOps and machine learning in production.
ML Myth 1: MLOps is all about tooling and automation
False! While tools and automation are essential components of MLOps, similarly to DevOps it should be thought of as a set of principles that contribute to building Machine Learning Systems and keeping it operational. Typically this would include: automated versioning, automated monitoring and automated testing.
MLOps should be considered as a set of principles that involves people, processes and technologies (which include frameworks). It encompasses the entire machine learning lifecycle and includes collaboration among data scientists, engineers, and operations teams. However, one aspect where many go wrong is thinking of MLOps as a waterfall software architecture.
Figure 1: The 2023 MAD (Machine learning, Artificial intelligence & Data) Landscape
The MAD (Machine learning, Artificial intelligence & Data) landscape (pictured above) covers the vast majority of tools, software and technologies throughout the different lifecycle stages of MLOps.
In our blog “From MLOps to ML Systems” we provide a different approach for building machine learning (ML) Systems with the FTI (Feature, Training & Inference) pipelines. With the FTI architecture, there is no single ML pipeline but three independently developed and operated pipelines: feature, training and inference pipelines. This architecture describes both batch and real-time ML systems, making it easier for developers to move to and from batch and real-time systems. Ultimately, the FTI approach for ML systems enables easier collaboration between data and ML teams.
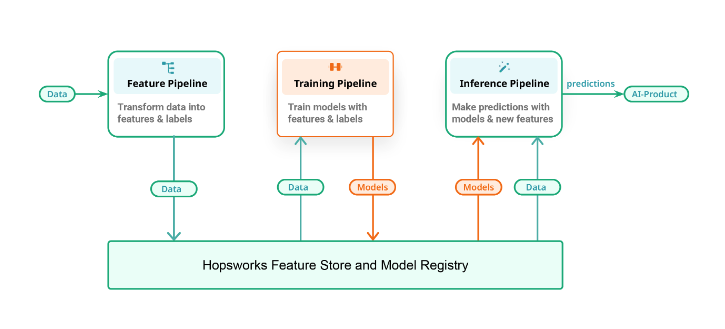
Figure 2: A unified architecture for ML systems consisting of three individual pipelines; a feature pipeline, training pipeline and an inference pipeline.
ML Myth 2: It takes months to get your machine learning models in production
True… with a caveat! While bringing models to a production environment might sometimes take months, with an iterative approach (thinking agile and MVPs), ML models can be deployed in production in a matter of weeks and continuously improved.
While model development is a crucial phase, it is one part of the entire ML lifecycle and deploying a machine learning model in production can be time-consuming or may sometimes end up never happening at all. Most companies take more than a month to first train and deploy a machine learning model in production. This largely is due to the fact that many organizations lack the systems needed to organize the pipelines that connect models to the data sources (the features!).
In order to get your models to production you need to feed data and connect your feature, training and inference pipelines to a unified infrastructure. A way of demonstrating how fast machine learning models can be put in production is through creating a MVPs (Minimal Viable Production Service). A MVPs is the simplest end-to-end ML system that includes the three main ML pipelines: a feature pipeline, a training pipeline, and an inference pipeline, and uses a feature store and model registry. The idea behind the MVPs is to quickly demonstrate how the model will be used in the production environment to AI-enable an existing or new predictive service, as well as provide a measurement for improvement and how the model performance is related to business KPIs.
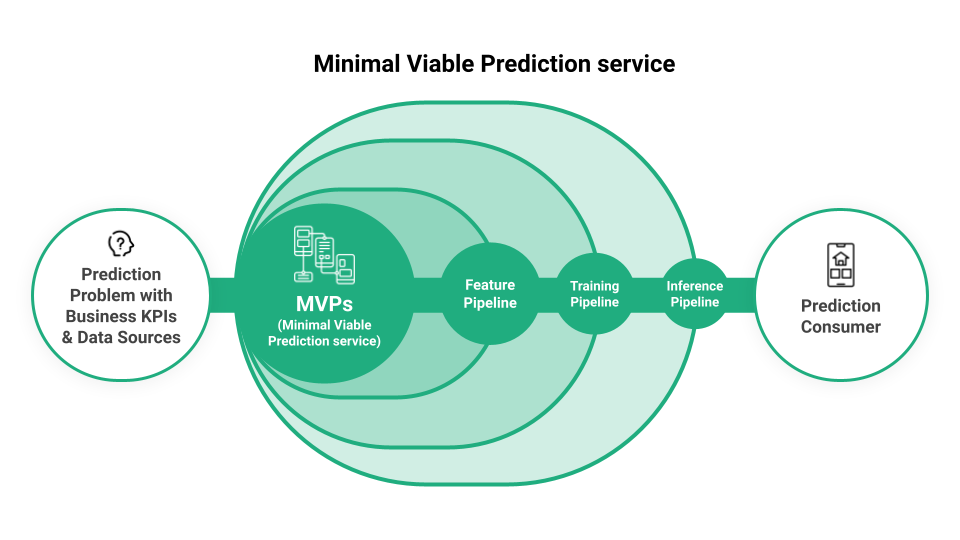
Figure 3: Structure for building a MVPs
ML Myth 3: Once the model is in production, the work is done
False! Continuous model and feature monitoring is required to ensure model performance and improvement over time.
Continuous monitoring, feedback loops, and model retraining are essential for maintaining model performance over time. Practitioners should recognize the need for continuous integration and continuous deployment (CI/CD) pipelines to facilitate seamless updates and improvements to ML systems.
ML models are not perfect, their performance can degrade over time due to changes in data distributions or other external factors. Continuous monitoring can be an essential strategy to detect issues such as data quality problems or changes in the environment that can impact model accuracy. Additionally; teams should strive to improve the current accuracy of their models in production; strategies to log feedback and re-train the model should be implemented. A machine learning system with models in operation should be seen as an ever-evolving system; nothing is static.
If you are curious to learn more about feature monitoring, we did a webinar on how to monitor features with a feature store.
ML Myth 4: Feature Stores are only beneficial for big Data Science teams with tons of Data
The reality: Despite being particularly beneficial for larger Data Science teams, a feature store is a valuable part in the MLOps practices for organizations of all sizes and with different data volumes.
Even small to medium-sized businesses as well as ML freelancers with smaller amounts of data will benefit from implementing a feature store. By using a feature store, data science teams can streamline their machine learning in production workflows, improve collaboration, structure data and ensure the reliability of ML systems. Ultimately, an ML system with a feature store can be adapted to fit the scale, requirements and data amount of different organizations.
Another common misconception is that MLOps is expensive and the hassle of installing different software makes the implementation into your infrastructure difficult. The fact is that there are a bunch of open source and free ML platforms out there that can be implemented into your ML system’s infrastructure seamlessly and with little or no cost. With this in mind, even small ML teams or individual users can create streamlined, serverless workflows for machine learning models in production.
If you need inspiration on where to begin, there is a great community out there for people who are passionate about building serverless ML systems as well as a free course that teaches you all you need to know about how to build one of these systems.
ML Myth 5: Real-time data and feature stores are not necessary for LLMs
Well, it depends! Real-time data may not be needed for all applications and use of large language models but it’s an essential component for personalized LLMs.
If your application requires time-dependent information on your user, such as latest clicks or actions to provide context for the LLM recommendation; your ML system requires access to fresh data, and fast. This is where vector databases need to be complemented with a robust feature store layer supporting embeddings and fast retrieval.
Watch our webinar to get a deep dive into LLMs: