Deep Learning for Anti-Money Laundering with a feature store
Deep learning is now the state-of-the-art technique for identifying financial transactions suspected of money laundering. It delivers a lower number of false positives and with higher accuracy.


Financial institutions invest huge amounts of resources in both identifying and preventing money laundering. Many companies have systems that automatically flag financial transactions as ‘suspect’ using a database of static rules that generate alerts if they match for a transaction, see Figure below. Flagged transactions can be either withheld and/or investigated by human investigators. As anti-money laundering (AML) is a pattern matching problem, and many institutions have terabytes (TBs) of labelled data for historical transactions (transactions are labelled as either ‘good’ or ‘bad’), many banks and companies are investigating deep learning as a potential technology for classifying transactions as "good" or "bad", see Figure below.
However, supervised machine learning is not a viable approach due to the typical imbalance between the number of “good” and “bad” transactions, where you may only have 1 “bad” transaction for every million transaction or more. What are the alternatives? Well, in 2019, unsupervised learning and self-supervised learning have taken deep learning by storm, with self-supervised solutions now the state-of-the-art systems for both Natural Language Processing (NLP), RobertA by Facebook, and image classification for ImageNet, Noisey Student and AdvProp both by Quoc Le’s team at Google.
Self-supervised learning is autonomous supervised learning, that doesn’t always require labelled data, as self-supervised learning systems extract and use some form of feature or metadata as a supervisory signal. In contrast, unsupervised learning has a long history of being used for anomaly detection, and in this blog we describe how we have worked on an AML solution based on Deep Learning, and how we moved through unsupervised, self-supervised, to semi-supervised to arrive at our method of choice - Generative Adversarial Networks (GANs).

Rules-based AML versus Deep-Learning AML using models.
The Class Imbalance Problem for AML
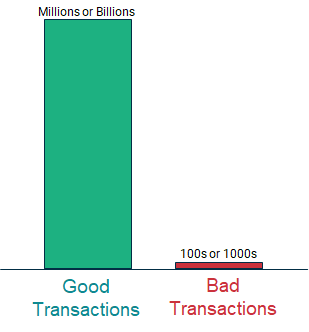
In the figure above, we can see the huge data imbalance between good and bad transactions found in a typical AML transaction dataset. A supervised deep learning system could be used to train a binary classifier that predicts with 99.9999% accuracy whether a transaction was involved in money laundering or not. Of course, it would always predict ‘good’, and only get wrong the very small number of ‘bad’ transactions! This classifier would, of course, be useless.
The problem we are trying to solve is to predict correctly when ‘bad’ transactions are bad, and minimize the number of ‘good’ transactions that we predict as bad. In ML terminology, we say we want to maximize true positives (miss no bad transactions), and minimize false negatives (good transactions predicted as bad), see the confusion matrix below. False negatives get you in trouble with the regulator and authorities, false positives create unnecessary work and cost for your company.
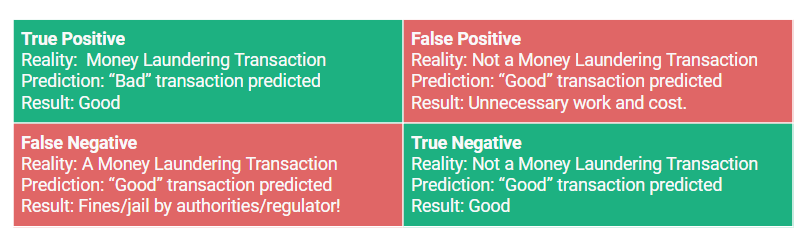
Confusion matrix of our Binary Fraud Classifier with all possible predictions and their consequences. You could use a variant of the F1 score to evaluate models (precision and recall should not be weighted equally).
Our solution will have to address the class imbalance problem, as you may have thousands or millions or good transactions for every one transaction that is known to be bad. Supervised machine learning algorithms, including deep learning, work best when the number of samples in each class are roughly equal. This is a consequence of the fact that most supervised ML algorithms maximize accuracy and reduce error.
Unfortunately, over-sampling the minority class, undersampling the majority class, synthetic sampling, and cost-function approaches will not help us solve the class imbalance problem, due to the sheer scale of typical data imbalance. Other classical techniques such as One-Class support vector machines or Kernel Density Estimators (KDE) will not scale enough as they “require manual feature engineering to be effective on high-dimensional data and are limited in their scalability to large datasets”.
AML as Anomaly Detection
Anomaly detection follows quite naturally from a good unsupervised model
- Alex Graves (Deep Mind) at NeurIPS 2018.

As AML problems are not easily amenable to supervised machine learning, much ongoing research and development concentrates on treating AML as an Anomaly detection (AD) problem. That is, how can we automatically identify suspected money-laundering transactions as anomalies? The domain of AML is also challenging due to its non-stationarity - new money transfer schemes are constantly being introduced into the market, whole countries may join or leave common payment areas or currencies, and, of course, new money launderingschemes are constantly appearing. AML is a living organism and any techniques developed need to be able to be quickly updated in response to changes in its environment.
Traditional machine learning approaches to solving anomaly detection have involved using unsupervised learning approaches, see Figure above. An unsupervised approach to AML would be to find a “compact” description of the “good” class, with “bad” transactions being anomalies (not part of the “good” class). Examples of unsupervised approaches to AD include k-means clustering and principal component analysis (PCA).
However, AML is not a classical use-case for anomaly detection techniques as we typically have labelled datasets - financial institutions typically know which transactions were “good” and which transactions were “bad”. We should, therefore, exploit that labelled data when training models. That is, we have semi-supervised learning - it is not fully unsupervised learning as there is some labeled training data available.
What are useful Features for AML and how do we manage them?
Before we get into semi-supervised ML, we need to discuss the features that can be used to train your AML model. Firstly, you should only train your AML model on features that will be accessible in your production AML binary classifier. If you access to features while in development that will never be usable in production, don’t even use them out of curiosity. Don’t kill the cat. If you are designing an AML classifier for an online application, then it is important that you know that you can access the features used to train your model at very low latency in production.
Typically, this requires an online feature store, such as the Hopsworks Feature Store (see End-to-End figure later). If you are training a classifier for an offline batch application, then you typically do not need to worry about low latency access to feature data, as you will probably have feature engineering code in the batch application (or in the Feature Store) that pre-computes the features for your classifier.
The most obvious features that are available for AML are the features that arrive with the transaction itself: sending customer, receiving customer, sending/receiving bank, the amount of money being transferred, the date, etc). Other examples of useful features include how many transactions the sending/receiving account has executed in the last day, week, or month; whether the transaction date/time is “special” (holiday, weekend, etc), the graph of customers connected to the sender/receiver accounts over different time windows (last hour/day/week/month/year); credit scores for accounts, and so on.
Typically, these features are not available in your online application and you do not want to rewrite your feature engineering code in your online AML classifier application, so you use the Feature Store to lookup those features at runtime when the transaction arrives. When you have queried those features from the Online Feature Store, you can join them (in the correct order) with the transaction-supplied features and then send the complete feature vector to the network-hosted model for a prediction of whether the transaction is “good” or “bad”.
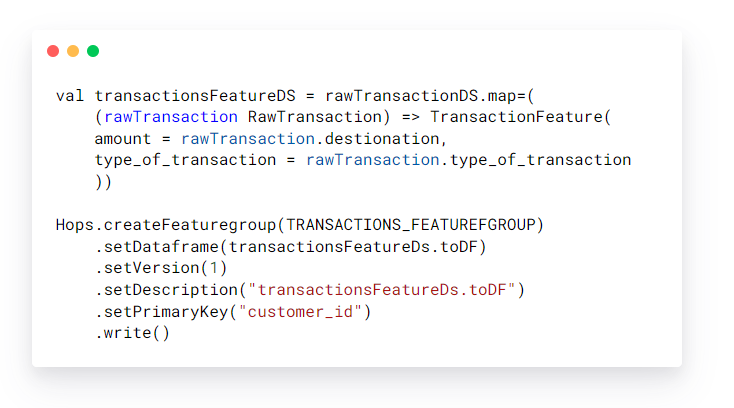
Writing to the feature store:
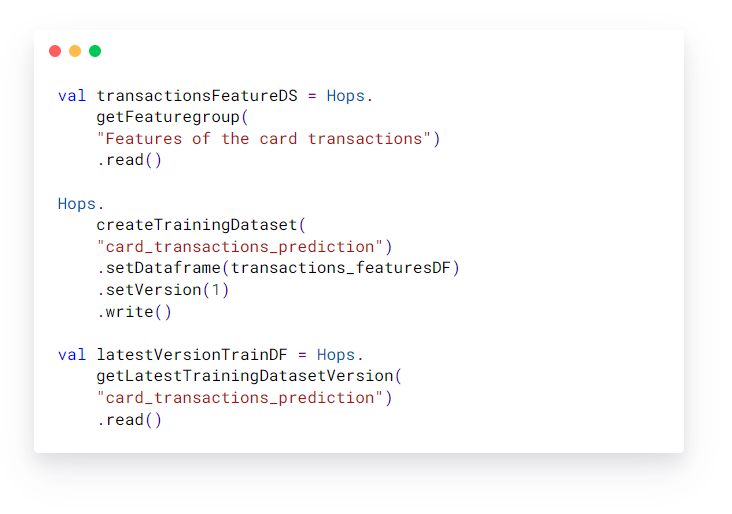
Reading from the feature store:
Semi-Supervised Learning for Anomaly detection
“Semi-supervised learning is a class of machine learning tasks and techniques that also make use of unlabeled data for training – typically a small amount of labeled data with a large amount of unlabeled data.”
In semi-supervised learning, we use many of the techniques from unsupervised learning - you train a good model of the data, then you can see how likely something is under that model. In AML, we could use, for example, one-class novelty detection, to train one GAN on the large class of ‘good’ transactions as the novelty detector, and another GAN that supports it by enhancing the inlier samples and distorting the outliers.
Generative Adversarial Networks (GANs)
Generative models involve building a model of the world that enable you to act under uncertainty. More precisely, they are able to model complex and high dimensional distributions of real-world data. We use GANs for anomaly detection by modeling the normal behavior of some training data using adversarial training and then detecting anomalies using an anomaly score. To evaluate our performance, we use Precision, Recall and F1-Score metrics.
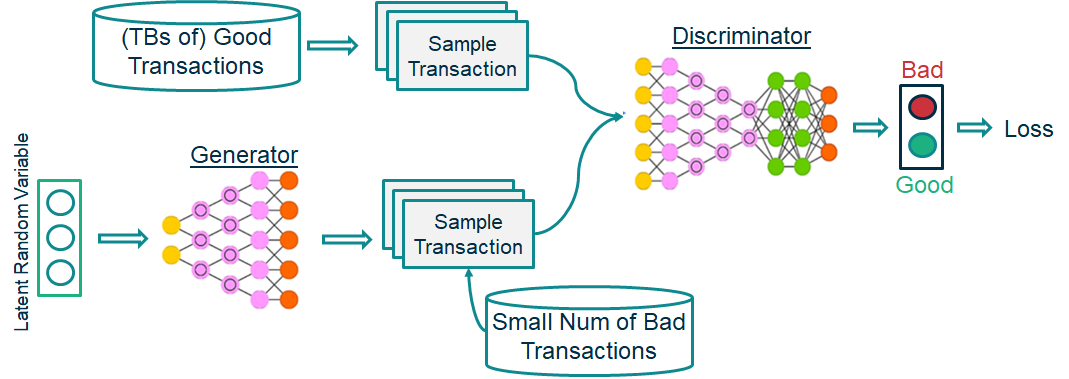
Training a GAN with Transactions classified as ‘good’ and ‘bad’.
GANs are generally very difficult to train - there is a significant risk of mode-collapse - where the generator and discriminator do not learn from one another. You will need to carefully consider the architecture you use. To quote Marc Aurelio Ranzato (Facebook) at NeurIPS 2018 “the Convolutional Neural Network architecture is more important than how you train (GANs)”. You will need to dedicate time and GPU resources to hyperparameter tuning due to the sensitivity of GANs and the risk of mode-collapse.
Hyperparameter Tuning for Training GANs in Hopsworks and Maggy
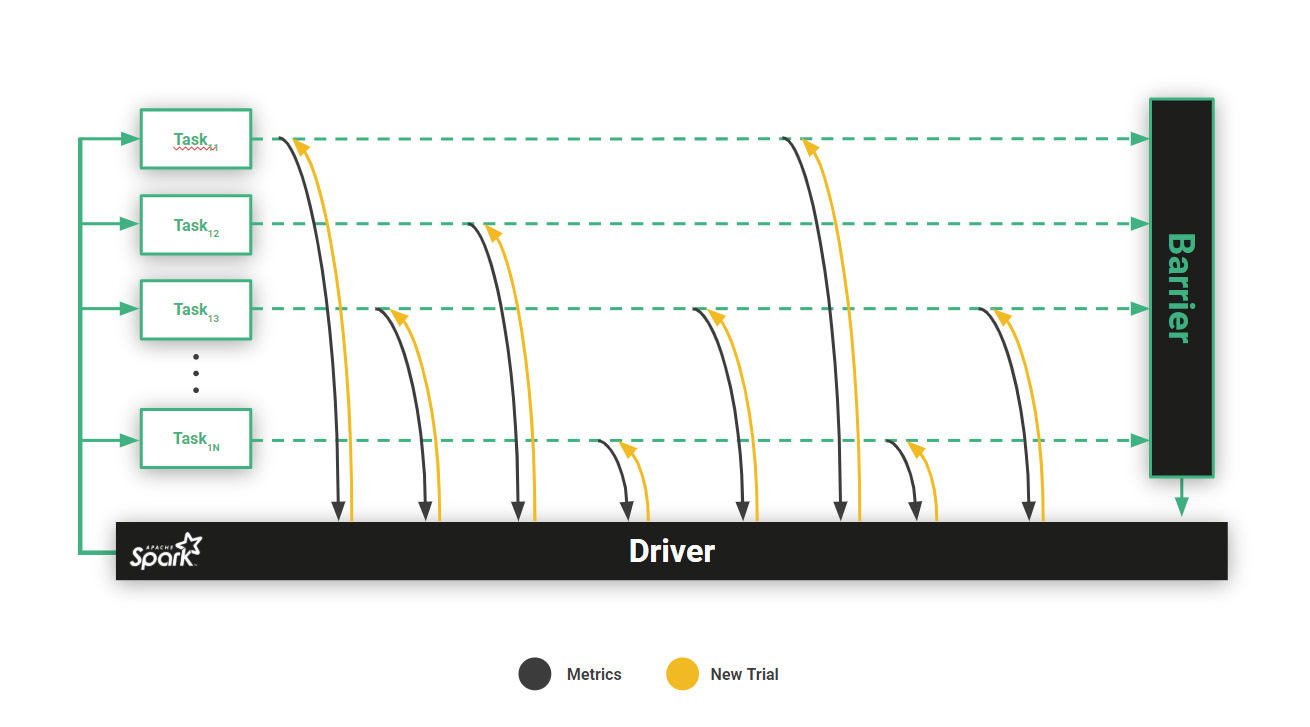
The Maggy framework on Hopsworks uses PySpark to distribute hyperparameter tuning tasks to GPUs running TensorFlow/Keras/PyTorch ocde. Maggy supports state-of-the-art asynchronous directed search, such as ASHA, as well as custom optimizers.
You need to have the tools and platform to do hyperparameter sweeps at scale with GANs, due to their sensitivity. Hopsworks uses PySpark and the Maggy framework to distribute hyperparameter trials to GPUs running TensorFlow/Keras/PyTorch code. Hopsworks/Maggy supports state-of-the-art asynchronous directed hyperparameter search, which can provide up to 80% more efficient use of GPUs when tuning sensitive GANs, compared to other hyperparameter tuning approaches using PySpark. Read our Maggy blog post to find out more.
Similar to MLFlow, Hopsworks also provides an experiment service where you can manage all hyperparameter trials as experiments. Experiments supports Tensorboard, tabular results for trials, and any images generated during training. This makes training runs and models easier to analyse and reproduce.
Putting your GAN in production
If you have now successfully trained a GAN that performs well on your test dataset (keep the last year/months of your transaction data as holdout data), you can save that the discriminator as a model for use on new transactions. Typically, you want further model validation - the what-if tool is a good way to evaluate black-box models in Jupyter notebooks on on Hopsworks - before you deploy your model from your model registry into production for either online applications or batch applications.
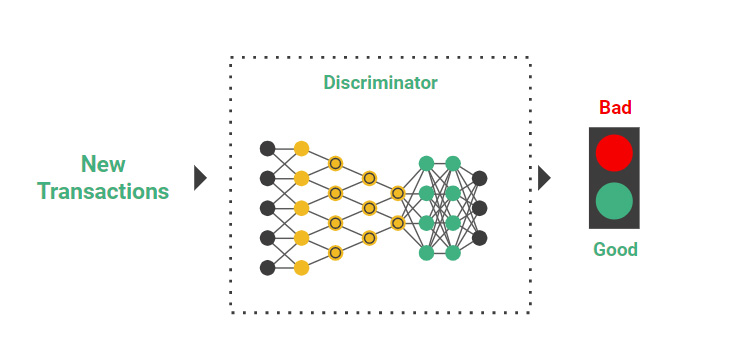
Save just the Discriminator from your original GAN to classify new transactions as either ‘good’ or ‘bad’.
Will GANs increase True Fraud Detection and reduce False Fraud Detection?
While there is no guarantee that GANs will magically make money laundering disappear overnight, they appear to be a much more powerful tool for correctly identifying fraudulent transactions and for minimizing the number of false alerts that need to be manually investigated. In China, GANs are already being used in production at two banks: “Two commercial banks have reduced losses of about 10 million RMB in twelve weeks and significantly improved their business reputation”, GAN-based telecom fraud detection at the receiving bank. Another example shown below was recently presented at the Spark/AI Summit EU 2019.
There is also the issue of explainability (particularly in the EU), where it is unclear how regulators will handle the use of black-box techniques in making fraud classification decisions. The first step to take is to augment existing systems with extra input from a GAN-based system, and evaluate for a period of time before discussing how to proceed with the regulators.

Expected results from using GANs (Anomaly Detection at Spark/AI EU Summit 2019)
End-to-End Workflow on Hopsworks for GANs
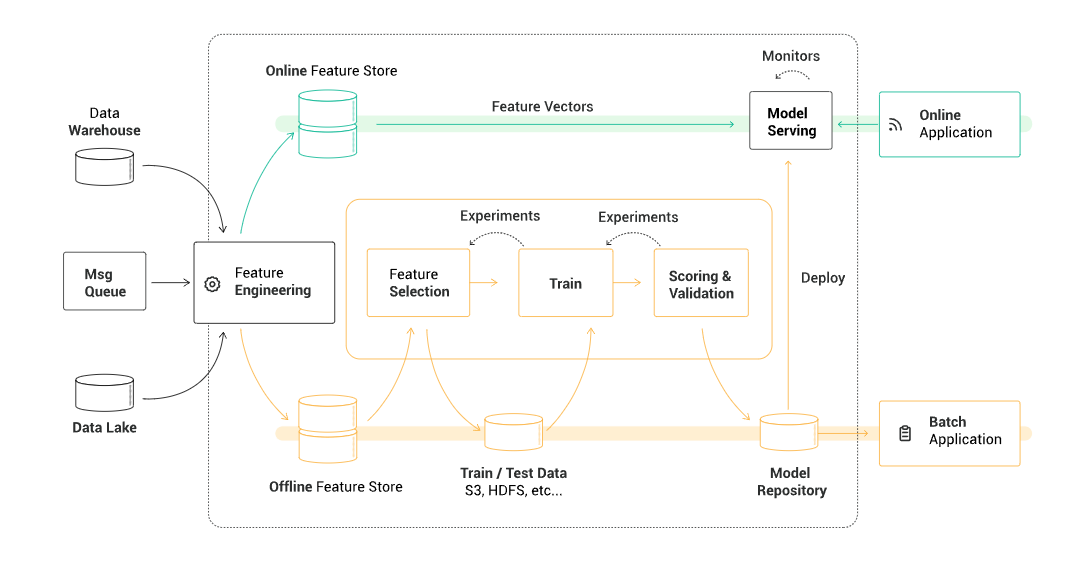
Machine Learning Pipeline With Hopsworks
Hopsworks enables automated end-to-end ML workflows for taking historical financial transactions from production backend data systems (data warehouses, data lakes, Kafka), feature engineering with Spark/PySpark, feature storage in the Feature Store. For orchestrating such feature pipelines, Hopsworks includes Airflow as a service. Airflow is also used by Data Scientists to orchestrate Jupyter notebooks for (1) selecting features to create train/test data, (2) finding good hyperparameters, (3) training a model, (4) evaluating the model before deploying it into production.
Finally, online AML detection applications need to enrich their feature vectors with transaction window counts and other features not available locally. The Hopsworks’ online Feature Store is a low latency highly available database, based on MySQL Cluster, that enables online AML applications to access their pre-engineered feature data with very low latency (<10 ms). The Hopsworks Feature store is modular with a REST API, so all steps 1-5 in the above figure can either be run on the Hopsworks platform itself or on external platforms. You decide.
Summary
Deep learning is revolutionizing how we identify money laundering, and it has unique challenges related to huge data volumes and massive data imbalances. At Logical Clocks, we have worked on a semi-supervised approach based on GANs, enabled by Hopsworks that scales to process huge datasets, and graph embeddings at scale, using Spark. The result is new state-of-the-art results for money laundering. The next phase is to put this model into production.