Feature Types for Machine Learning
Programmers know data types, but what is a feature type to a programmer new to machine learning, given no mainstream programming language has native support for them?

Introduction
Newly minted programmers are familiar with strings, int, and booleans. Programming languages have language-level support for data types. But when you start programming with machine learning (ML) frameworks, the lack of language level support for feature types means that there is not the same well-defined set of operations on categorical variables, numerical variables, and embeddings. For example, in Python, you may use a machine learning framework such as Scikit-Learn, TensorFlow, XGBoost, or PyTorch, and in each framework, there is a different set of valid operations on these different feature types.
The feature store is a common data layer for ML frameworks, so support for feature types in feature stores needs clear and unambiguous operations, supported by as many higher level ML frameworks as possible.
Feature Store 101
We can start by first defining what a feature is (for you data engineers). A feature is simply a variable that is an input to a machine learning model. A feature store helps to compute and store features. Features are typically processed in batches - DataFrames - when you both train models and when you have a batch program making predictions with a model.
When you have an online application that makes predictions with a ML model, you typically need a row (or vector) of features. For example, to make a recommendation for a user to your retail website, you might want to compute features based on their current session (pages visited, items in basket), but also historical features about prior visits, and context features - what products are trending right now. Your web application is probably stateless, and the historical and context features have been precomputed and stored in the feature store. Your stateless web application retrieves them as rows (feature vectors) when needed to make a prediction. In Python ML frameworks, a feature vector that is used by the model to make a prediction is often a NumPy Array or an n-dimensional tensor.
Features are saved in your feature store as tabular data, in a row/column layout where columns are the features and the rows contain the feature values along with an entity (or primary) key and an optional event_time column, indicating when the feature values were observed.
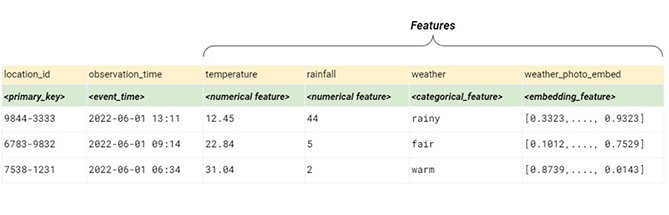
Features are stored as tabular data in a feature group (in the feature store)
Features Types
In the table above, each feature contains either quantitative or qualitative information. Quantitative data is numerical. For example, the amount of rainfall or the temperature. Qualitative data is discrete, with a finite number of well-known values, like weather_description in the above table.
Sometimes you transform quantitative data into qualitative data so that it is easier for machine learning to find patterns in the data. For example, you might decide that the rainfall and temperature feature values are sparse and you don’t have enough training data, so you transform them into categorical variables. For example, your training examples may have different values for the temperature and rainfall, and it becomes more difficult for your model to learn patterns in your data. However, if you transform rainfall into categories - [dry, damp, wet, torrential], your model can more easily learn to predict whether the amount of rainfall will be in one of those categories.
A taxonomy of feature types is shown in the figure below, where a feature can be a discrete variable (categorical), a continuous variable (numerical), or an array (many values). Just like a data type, each feature type has a set of valid transformations. For example, you can normalize a numerical variable (but not a categorical variable), and you can one-hot encode a categorical variable (but not a numerical variable). For arrays, you can return the maximum, minimum, or average value from a list of values (assuming those values are numerical). The feature type helps you understand what aggregations and transformations you can apply to a variable.
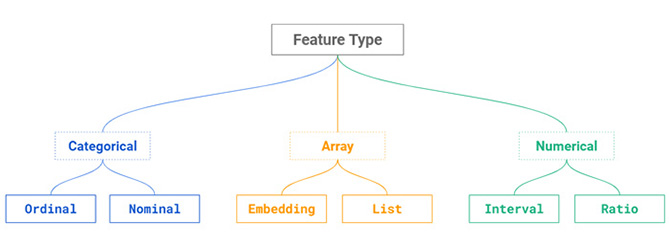
A taxonomy of machine learning feature types
Categorical features are based on discrete data. If a categorical feature has no natural ordering (such as the weather feature from the table above), we call it a nominal variable. One common operation on nominal variables is to count the frequency of occurrence of its different discrete values, often over windows of time. You can also identify the “mode” or most frequent discrete value in your nominal variable, but you cannot compute the median for a nominal variable.
If the categorical feature, however, has a natural ordering, it is called an ordinal variable. For example, our transformed rainfall feature from earlier (dry, damp, wet, torrential) can be considered an ordinal variable, as you can order the values based on the amount of rainfall. However, for ordinal variables, the difference between any two values has no mathematical meaning. For example, adding “dry” to “damp” does not make any mathematical sense. The median can often be computed for nominal variables. For example, “damp” is the median rainfall for Ireland.
A numerical variable describes quantitative data. Numerical variables are similar to ordinal variables except that with numerical variables the differences between values have a consistent meaning. In contrast to categorical variables, in general, you can add and subtract numerical variables and the results will have meaning. Numerical features are measured over a scale, where the scale can be either finite or infinite, and you can also compute measures of central tendency (mean, median, mode) as well as its measures of variability (variance and standard deviation). This is useful, for example, to help you replace missing values with the arithmetic mean or the median of the numerical variable. Numerical variables can be further subdivided into two different types: interval and ratio variables.
An interval variable is a numerical variable that does not have the concept of a true zero. That is, there is no ‘zero’ level measurement available for our feature. For example, an interval variable could be a weather_score (on a scale from 1 to 5). We can calculate useful statistics, like the mean weather_score, but there is no notion of a true zero - an absence of the thing you are trying to measure.
A ratio variable is a numerical variable with a meaningful zero value, for example, the temperature feature above. Interval variables do not have a true zero, so you can only add and subtract values together with meaning. Ratio variables, thanks to a true zero, can also be divided and multiplied, producing meaningful results. For example, if we say rainfall per month has doubled from 100mm, we know the result is 200mm because the doubling is relative to zero.
Our taxonomy of feature types is not complete, however. The final class of feature that we handle differently in feature stores is an array of variables. While arrays are not traditionally considered as a feature type, the set of valid mathematical operations and transformations you can perform on them is.
A feature store is more useful if it has native support for storing arrays of values. The array can be anything from an (unordered) vector of floating point numbers to an (ordered) list of values (multiple categorical variables).
An embedding is also an array - an array of numbers, often floats. More formally, an embedding is mapping from a discrete set to a vector space, called the embedding space. That is, an embedding is a lower dimensional representation of some input features that is computed using a feature embedding algorithm. For example in the table above there is a feature called weather_photo_embed. If you have photographs of the weather, an embedding algorithm will transform and compress the photos into a small fixed length array of floating point numbers - the embedding features. Embeddings can be used for similarity search. With our weather photos, you could potentially use the embedding to find weather similar to the weather in the photo. Embeddings can also be used to train a model that is based on a sparse categorical variable. The embedding can compress your sparse categorical variable, so the model can learn from the lower dimensional feature. An important hyperparameter of embeddings is their length - will they be 4 or 16 or 32 or 200 floats?
A feature store can also support a list of feature values as a single feature to help reduce development and optimize storage costs. Doordash supports lists of features to reduce storage costs by applying compression before storing lists in the feature store. Another example use-case for a list as a feature type is to replace 10 separate features, with the 10 best weather locations yesterday, with a single feature containing all 10 locations. Different users of the list feature can then transform it in different ways - get the top location, average weather at top-10 locations, etc.
While not specifically a feature type, it also can happen that some features used to train a model have no predictive power. Such features are irrelevant features, and should be identified and then removed from training data as they slow down training, make it harder for models to converge, and make models unnecessarily larger. The feature store can help you identify useless features by analyzing training data, for example, identifying highly correlated (redundant) features.
Given the different types of features defined here, it is interesting to note that features in a feature store can be reused across supervised, unsupervised, and self-supervised ML models. For supervised ML, a label may be a feature in the feature store or could come from an external data store. That is, a label in one model could be a feature in another model. Self-supervised training data may be large in volume and instead of copying a lot of data into the feature store, some feature stores support external tables, where the features may be registered in the feature store, but stored in different external sources (such as parquet files in a data lake or tables in a data warehouse like Snowflake, BigQuery, or Redshift).
Feature Types as Data Types
At this point, it is important to note that the feature types defined here are abstract, and you work with concrete data types when you program with Numpy arrays, Pandas or Spark dataframes, or SQL queries. The data types supported by your feature store should closely match the frameworks you use for feature engineering. All data types need to be converted into numerical data before being passed as training data or inference data. Machine learning models take numbers as input and predict a number as output, and feature types define the set of valid transformation functions that can be applied to a data type. Without the feature type, the feature store cannot always know what the valid transformations are that can be applied to a feature. Then, it is left to you, the programmer, to decide on how to transform the feature into a numerical format that will be accepted by your model.
Feature Types and Aggregations
As mentioned earlier, if you have an ordinal (categorical) feature, you may know that you can compute counts over its values, while if you have a numerical variable, you can compute descriptive statistics over it (mean, min, max, standard deviation). If you have features defined in your feature store with a known feature type, the feature store can help provide hints on what types of aggregations can be computed over features. If you only have that data in a data warehouse, with only data type information, then it is more difficult to provide hints on meaningful aggregations over the data type.
Feature Types, Feature Views, and Transformations
In Hopsworks, you write features to feature groups (where the features are stored) and you read features from feature views. A feature view is a logical view over features, stored in feature groups, and a feature view typically contains the features used by a specific model. This way, feature views enable features, stored in different feature groups, to be reused across many different models.
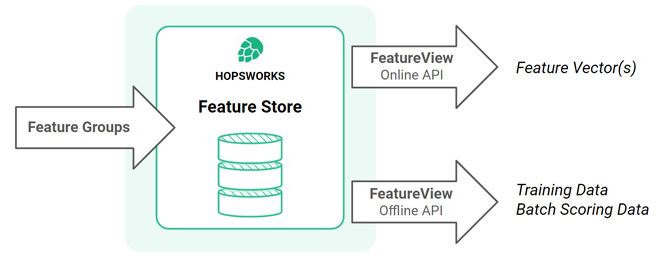
Transformations can be done either in feature engineering before writing to feature groups (reducing the latency for reading the feature, but making the feature less reusable in different models) or after the feature store (requiring an online transformation of the feature when it is read through a feature view, but making the feature more reusable in different models).
The Feature View is a logical view over (or interface to) a set of features that may come from different feature groups.

A Feature View is a logical view over features that are used by a model (for training and serving). Features in a Feature View contain both the data type and any transformation functions applied to the feature. As such, the Feature View extends the type of the feature from a feature group, adding an optional transformation function to the type.
In the illustration above, we can see that the features for a Feature View are joined together from the two feature groups: weather_feature_group and the surf_feature_group. You can also see that features in the feature view inherit not only the feature type from their feature groups, but also whether they are the primary key and/or the event_time. The figure also includes transformation functions that are applied to individual features after they are read from feature groups. Transformation functions are a part of the feature types included in the feature view. The transformation functions are applied both (1) when features are read as DataFrames using the Offline API (to create training data or for batch scoring) and (2) when features are read as feature vectors using the Online API. That is, a feature in a feature view is not only defined by its data type (int, string, etc) or its feature type (categorical, numerical, embedding), but also by any transformation function applied to it. The Feature View ensures that the transformation function is applied consistently when creating batches of data for training and individual rows (vectors) for online predictions. This solves the problem of training-serving skew, where transformation functions used to create training data and used for online feature vector processing may have different implementations, leading to difficult to diagnose model performance bugs.
Conclusions
Feature types are a useful extension to data types for understanding the set of valid operations on a variable in machine learning. The feature store can use the feature type to help identify valid transformations (normalize, one-hot-encode, etc) on features, and when visualizing feature metrics. Embeddings are a relatively new type of feature, and are arrays, and we believe the older textbook examples where features are only categorical or numerical need to be updated to reflect the first-class status of embeddings in feature stores such as Hopsworks.