MLOps vs. DevOps: Best Practices, Challenges and Differences
Explore the convergence of MLOps and DevOps. Learn about their purposes, differences, and areas of integration and discover best practices, challenges, and their future potential.

Introduction
In the ever-evolving landscape of technology and software development, two methodologies have emerged as crucial pillars for effective and efficient project management: MLOps and DevOps. These approaches have emerged as essential frameworks for ensuring efficient, scalable, and reliable deployment of software applications and machine learning models. While both MLOps and DevOps share common objectives of improving collaboration, automation, and deployment practices, they possess distinct characteristics and cater to unique requirements within their respective domains.
Throughout this article, we will explore the similarities and differences between MLOps and DevOps, delve into their key principles, methodologies, and tools, and discuss how organizations can benefit from adopting these practices. By understanding the unique aspects of MLOps vs DevOps, we can effectively harness their capabilities to ensure seamless, scalable, and secure software development and machine learning deployments.
DevOps: Enhancing Collaboration, Automation, and Continuous Delivery
DevOps, an amalgamation of "development" and "operations," has transformed the software development landscape by introducing a new set of principles, practices, and tools that foster collaboration, automation, and continuous delivery. In this section, we will explore the core concepts and principles of DevOps, its origins, and its impact on software development.
Originating from the need to bridge the gap between development and operations teams, DevOps emerged as a response to the traditional siloed approach to software development. Historically, development teams focused on creating software, while operations teams handled its deployment and maintenance. However, this fragmented approach often led to inefficiencies, communication gaps, and slower time to market.
DevOps addresses these challenges by promoting a culture of collaboration, shared responsibilities, and streamlined processes. It encourages development and operations teams to work together throughout the software development lifecycle, right from planning and development to testing, deployment, and monitoring.
At the core of DevOps lie collaboration, automation, and continuous delivery.
Collaboration emphasizes the need for cross-functional teams to work together, share knowledge, and collectively take ownership of the software development process.
Automation is another crucial principle of DevOps. It involves automating manual and repetitive tasks across the software delivery pipeline, including building, testing, and deployment. Automation reduces human error, accelerates processes, and ensures consistency, enabling teams to focus on higher-value activities and innovation.
Continuous delivery, the third pillar of DevOps, revolves around the concept of continuously delivering software updates and improvements to users. It involves the integration of development, testing, and deployment processes into a seamless, automated pipeline. Continuous delivery allows organizations to release software frequently, reliably, and with minimal risk, facilitating faster time to market and rapid feedback loops.
To implement DevOps practices effectively, organizations rely on a wide range of tools and methodologies. Popular DevOps tools include version control systems like Git, continuous integration servers like Jenkins or CircleCI, configuration management tools like Ansible, infrastructure management tools like Terraform, and containerization platforms like Docker and Kubernetes.
DevOps methodologies, such as Agile, also play a significant role in driving its practices. Agile methodologies emphasize iterative development, frequent feedback, and adaptive planning, aligning well with DevOps's focus on incremental changes and continuous improvement.
Incorporating these principles, tools, and methodologies, DevOps empowers organizations to overcome traditional development and operations challenges. In the next section, we will shift our focus to MLOps, exploring its unique characteristics, purpose, and impact on machine learning deployments.
MLOps: Bridging the Gap between Machine Learning and DevOps
MLOps, an abbreviation for Machine Learning Operations, has emerged as a specialized field that combines machine learning techniques with DevOps practices to address the unique challenges posed by deploying and maintaining machine learning models. In this section, we will explore the significance of MLOps, the challenges it addresses, and its role in ensuring efficient model development, reproducibility, scalability, and monitoring.
Machine learning models introduce a new set of complexities compared to traditional software applications. These models rely on vast amounts of data, and complex algorithms, and often require specialized hardware or infrastructure. Additionally, they demand continuous retraining, versioning, and monitoring to ensure their accuracy and effectiveness.
The deployment and maintenance of machine learning models include managing large datasets, orchestrating complex workflows, handling versioning and reproducibility, ensuring scalability and performance, and monitoring model behavior and performance in real time. These complexities necessitate a dedicated set of practices and tools to streamline the development and deployment of machine-learning models.
MLOps practices address these challenges by borrowing concepts and principles from DevOps and applying them to the machine learning lifecycle. By integrating machine learning workflows into established DevOps pipelines, MLOps enables efficient collaboration, automation, and continuous integration and delivery of machine learning models.
Efficient model development is crucial in MLOps. It involves establishing reproducible and scalable processes for training, evaluating, and deploying models. MLOps practices facilitate version control of datasets and models, ensuring the traceability and reproducibility of experiments.
Scalability is a critical factor in MLOps, as machine learning models often need to handle massive amounts of data and accommodate fluctuating workloads. MLOps practices enable the deployment of models on scalable infrastructure, such as cloud platforms or container orchestration systems, allowing models to scale dynamically based on demand.
Monitoring machine learning models is another vital aspect of MLOps. Models need to be monitored continuously to detect drift in performance, identify biases, and ensure that they are delivering accurate and reliable predictions. MLOps practices incorporate robust monitoring and alerting mechanisms to track model behavior and performance metrics, enabling proactive identification and resolution of issues.
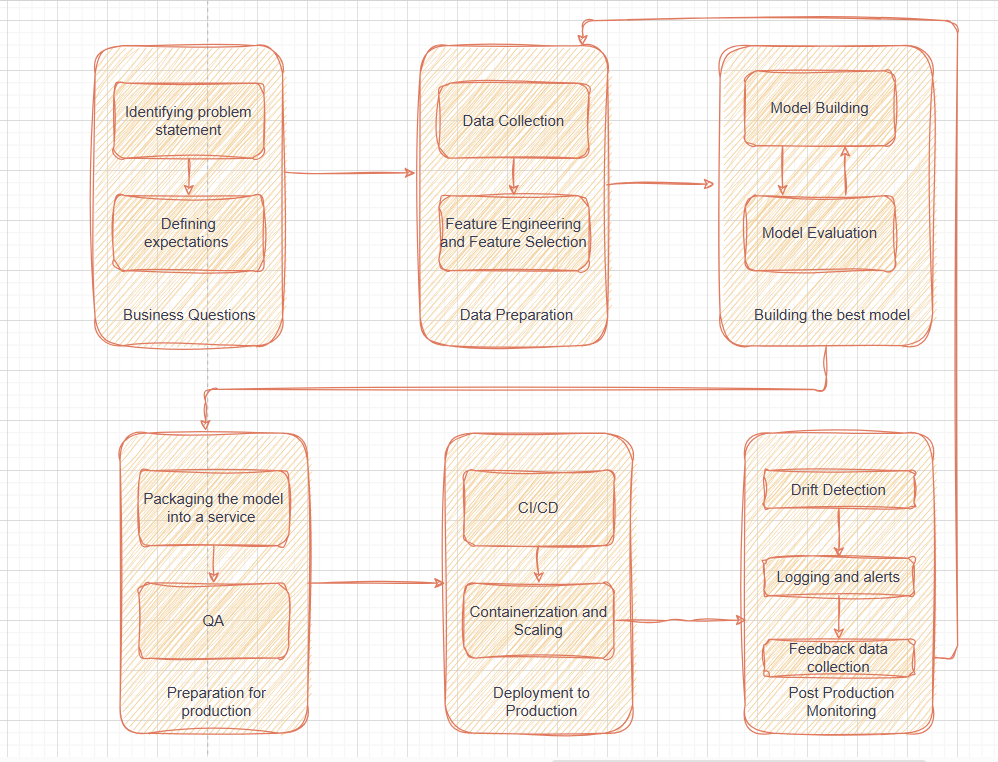
Figure 1: MLOps lifecycle
Comparing MLOps vs. DevOps
MLOps and DevOps, while sharing some common goals and principles, exhibit fundamental differences due to the unique nature of machine learning models. One critical aspect of MLOps is the efficient handling of features, which are crucial inputs to ML models. Feature Stores provide a centralized platform for managing, versioning, and serving features, addressing key challenges such as data consistency, reproducibility, and feature engineering. In this section, we will explore the key distinctions between MLOps vs. DevOps, shedding light on how each discipline addresses the challenges posed.
- Data Management Considerations: Another differentiating factor is the unique considerations for data management in MLOps. MLOps teams need to ensure data lineage, data versioning, and data quality control throughout the machine learning pipeline. This involves managing large volumes of data, implementing data pipelines, and maintaining data consistency, which may differ from traditional software development workflows. Feature Stores play a crucial role in data management by providing a centralized and organized repository for storing and managing features used in machine learning. They offer a structured and standardized approach to feature storage, ensuring consistency and accessibility of data across different stages of the machine learning lifecycle. Feature Stores enable efficient data discovery, retrieval, and versioning, making it easier to track the lineage and quality of features. They also assist in data governance by enforcing policies for data usage, access control, and auditing. Overall, Feature Stores enhance data management practices, improving the reliability, reproducibility, and efficiency of machine learning workflows.
- Deployment and Monitoring Requirements: DevOps focuses on deploying applications or services to infrastructure, often utilizing containerization and orchestration tools like Docker and Kubernetes. In contrast, MLOps requires the deployment of machine learning models, which involves considerations such as model serving, scaling, and monitoring for model performance and drift detection. In terms of monitoring, Feature Stores facilitate the tracking and monitoring of feature drift and quality. By capturing feature metadata and versioning, they enable monitoring pipelines to compare the distribution and characteristics of features over time and detect any deviations or changes that could impact model performance. This allows for proactive monitoring, alerting, and triggering of retraining or revalidation processes as needed. Feature Stores thus contribute to robust and accurate model deployment and ongoing monitoring of feature consistency and performance.
- Level of Automation: Automation is a crucial aspect of both MLOps and DevOps, but the level and focus of automation differ between the two. DevOps emphasizes automating software development processes, continuous integration, and continuous deployment (CI/CD). MLOps, in addition to CI/CD automation, includes automation for model training, hyperparameter tuning, feature engineering, and model selection. Feature stores streamline the creation and management of features. They provide a centralized and efficient way to retrieve features in real-time, ensuring consistent and reliable access to the required inputs for model predictions. Overall, Feature Stores automate and streamline critical aspects of feature management, reducing manual effort, improving efficiency, and enhancing the overall automation of MLOps processes.
- Nature of Artifacts: DevOps primarily deals with code as its central artifact, focusing on software development, testing, and deployment. On the other hand, MLOps revolves around machine learning models as its primary artifacts. These models require specialized considerations such as feature engineering, hyperparameter tuning, and model versioning, which are not typically part of traditional software development.
By understanding and acknowledging these distinctions, organizations can effectively bridge the gap between MLOps and DevOps, adopting tailored practices and tools to ensure the successful deployment and management of both code and machine learning models within their software development pipelines.
Pipelines in MLOps
In MLOps, feature, model training, and inference pipelines are key components of the end-to-end machine learning workflow. Let's explore each of them in detail.
- Feature Pipelines: Feature pipelines refer to the series of steps involved in processing, transforming, and engineering features for machine learning models. These pipelines handle tasks such as data preprocessing, feature extraction, and feature selection. Feature pipelines ensure that the input data is transformed into a format suitable for training the ML models. To build a Feature pipeline one must have expertise in data manipulation, possess domain knowledge, and have knowledge of feature extraction techniques.
- Model Training Pipelines: Model training pipelines are responsible for training the machine learning models using the prepared features and labeled data. These pipelines typically involve steps such as data splitting, model selection, hyperparameter tuning, and model training. Model training pipelines use algorithms and techniques to train ML models on the prepared data and optimize them to achieve the desired performance metrics. They may include steps for cross-validation, regularization, or other techniques to improve model accuracy and generalization. Model training pipelines require expertise in the selection of algorithms, hyperparameter tuning, and model evaluation. In addition to that, statistical concepts, software engineering skills, and domain knowledge are indispensable for implementing a model training pipeline.
- Inference Pipelines: Inference pipelines are used for deploying and serving machine learning models in production environments to make predictions or generate outputs based on new, unseen data. These pipelines involve steps such as model deployment, input data preprocessing, feature extraction, and model inference. Inference pipelines are designed to efficiently process incoming data, apply the trained ML model, and generate predictions or outcomes in real-time or batch mode, depending on the use case. Creating an Inference pipeline involves expertise in deploying models, handling input data preprocessing, and ensuring efficient and reliable real-time or batch prediction serving. The data processing code for getting the model features should align with the code used during feature engineering and this process involves retrieving features from the feature store.
Each pipeline has its specific tasks, considerations, and challenges, and understanding their distinct life cycles is crucial for the successful implementation and management of end-to-end machine learning systems in MLOps.
MLOps specific tools
There are several MLOps-specific tools available that help streamline and automate the various stages of the machine learning lifecycle. Here are some popular ones:
- Hopsworks: Hopsworks is a comprehensive data platform for ML with a Python-centric Feature Store and MLOps capabilities. It offers a modular solution, serving as a standalone Feature Store, managing and serving models, and enabling the development and operation of feature pipelines, training pipelines, and inference pipelines. Hopsworks facilitates collaboration for ML teams by providing a secure and governed platform for developing, managing, and sharing ML assets such as features, models, training data, batch scoring data, and logs.
- Seldon: Seldon is an open-source platform for deploying and managing machine learning models on Kubernetes. It provides tools for building scalable, production-ready inference servers, and features for A/B testing, canary deployments, and monitoring of deployed models.
- MLflow: MLflow is an open-source platform for managing the ML lifecycle. It offers components for experiment tracking, model packaging, and deployment. MLflow allows organizations to track experiments, reproduce models, and deploy them across different platforms and frameworks.
- Apache Airflow: Apache Airflow is an open-source platform for creating, scheduling, and managing workflows. It allows users to define and execute complex data pipelines, including ML workflows. Airflow supports task dependencies, retries, and monitoring, making it suitable for orchestrating and automating ML tasks.
- Apache Hudi: Apache Hudi is an open-source data management framework that provides efficient and scalable storage for large-scale, streaming, and batch data processing. It enables incremental data processing, and near real-time analytics, and simplifies data ingestion and processing workflows.
- Databricks: Databricks is a cloud-based platform that provides a unified environment for data engineering, data science, and MLOps. It offers collaborative notebooks, distributed data processing capabilities, and integrations with popular ML frameworks. Databricks enables end-to-end data management, model training, and deployment.
These are just a few examples of the MLOps-specific tools available in the market. The choice of tools depends on the specific requirements of your organization, the technology stack you use, and the complexity of your ML workflows. It's important to evaluate different tools and select the ones that best fit your needs.
Challenges and Best Practices in MLOps and DevOps Adoption
While the adoption of MLOps and DevOps practices can bring significant benefits, organizations may encounter several challenges along the way. Understanding and implementing effective strategies to address these challenges is crucial for successful implementation and integration.
- Cultural Barriers: One of the primary challenges organizations face is the cultural shift required to embrace MLOps and DevOps. Resistance to change, siloed mindsets, and lack of collaboration between teams can hinder the adoption process. To overcome cultural barriers, organizations should foster a culture of collaboration, open communication, and shared responsibility. Encouraging cross-functional teams and providing training and education on the benefits of MLOps and DevOps can help create a shared understanding and mindset across the organization.
- Skill Gaps: Adopting MLOps and DevOps practices often requires a diverse skill set that combines expertise in data science, machine learning, software engineering, and operations. Organizations may face challenges in finding individuals with the necessary skills or upskilling existing employees. Addressing skill gaps can be achieved through training programs, workshops, and mentorship opportunities.
- Governance and Compliance: Ensuring governance and compliance in MLOps and DevOps environments can be complex, particularly when dealing with sensitive data and regulatory requirements. Organizations need to establish clear policies and guidelines for data privacy, security, and ethical considerations. Regular audits, monitoring, and adherence to industry standards and regulations are essential for maintaining compliance.
- Testing and Validation in ML Deployments: Machine learning models require rigorous testing and validation to ensure their accuracy, robustness, and generalization. The dynamic nature of ML deployments introduces additional complexities. Organizations should establish comprehensive testing frameworks that encompass unit tests, integration tests, and end-to-end validation. Implementing practices such as A/B testing, model explainability, and monitoring model performance in production environments is vital to mitigate risks and maintain the reliability of ML deployments.
Conclusion
In conclusion, this article explores the significance of MLOps and DevOps in modern software development and machine learning deployments. It emphasizes the collaborative and continuous delivery-focused approach of DevOps and acknowledges MLOps as a specialized field addressing challenges specific to machine learning models.
The article also compares MLOps and DevOps, highlighting their differences in artifacts, data management, deployment, monitoring, and automation, while also identifying areas of synergy between the two. It addresses challenges in adopting MLOps vs DevOps, such as cultural barriers and skill gaps, and provides strategies like cross-functional teams and continuous learning to overcome them.
Overall, MLOps and DevOps play crucial roles in enabling efficient and scalable software development and machine learning deployments. Integrating these disciplines and embracing collaboration, automation, and continuous delivery can drive successful and transformative deployments, shaping the landscape of modern software engineering and data science for future innovation and progress.