Beyond Self-Driving Cars
This blog introduces the feature store as a new element in automotive machine learning (ML) systems and as a new data science tool and process for building and deploying better Machine learning models

Machine learning beyond just self-driving cars
Changes in consumer behaviour and technology are disrupting traditional modes of operation. To succeed, carmakers, dealers, and other automotive ecosystem companies must adapt quickly to the changing environment, embracing challenges and opportunities by exploiting the power of data.
The current generation of vehicles are software-enabled, data generating, connected devices, opening up opportunities for new (data ) products and services. Automobile data science isn’t just about self-driving cars. Data science and machine learning technologies can help keep carmakers competitive by improving everything from research to design manufacturing to marketing processes.
Automotive industry players have to innovate with data management to get the biggest bang for their buck from the data generated by their vehicles and customers. Acquiring, unifying, and gaining insight from data is a vital part of this innovation process. The Internet of Things and connected systems will have a significant influence on automotive innovation. Recent research says that by 2025, roughly 470 million cars will be collecting data from sensors and making it available online.(PWC report, p9). In addition, research suggests that the availability of connected systems will be vital in winning the Millennial market and retaining its loyalty.(Cars 2025, Goldman Sachs, trend 6 “The Internet of Cars”)
Given these trends, the automotive industry needs to have a data strategy for connected cars. The richest data set for vehicle-specific data is recorded on the CANBUS, and the automakers have the easiest access to that data. This access puts automakers in the best position to decide who can utilise the data and how.
New machine learning solutions are being implemented in the automotive industry each year. In the “Future Automotive Industry Structure - FAST 2030” report, seven trends are mentioned (see figure 1) to shape the automotive vertical by 2030, such as self-driving, connected vehicles, and e-mobility. Most of these trends will have elements of applied machine learning enabling the solutions that predict, recommend and classify.
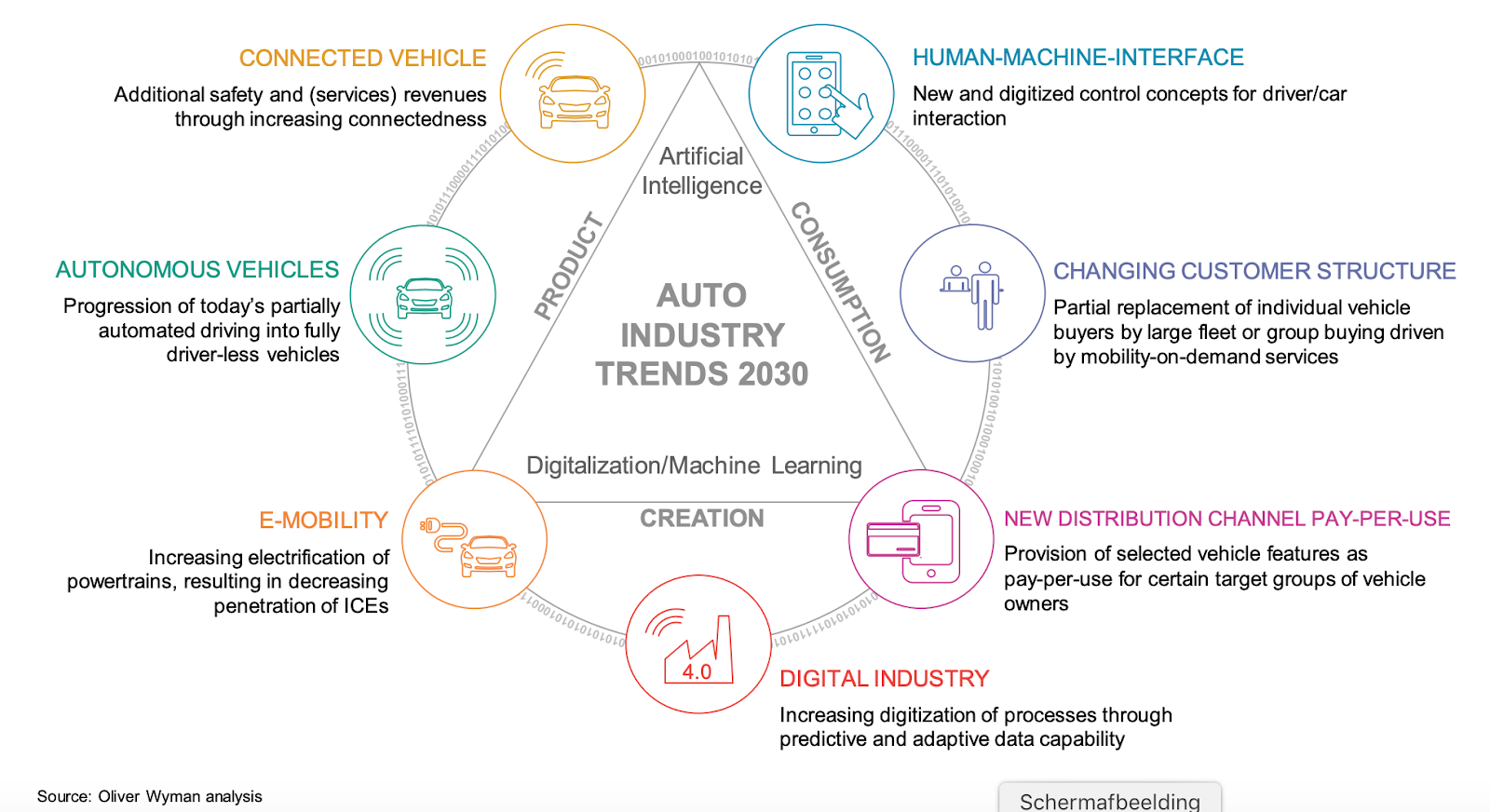
Seven trends shaping the automotive industry by 2030 Source: Oliver Wyman analysis from “Future Automotive Industry Structure - FAST 2030” report
To determine the place of machine learning in the automotive industry, we’ve listed some use cases that apply machine learning in products and solutions:
Predictive Maintenance
We’re used to cars notifying us with alerts and lights to check-engine or oil. Connected vehicles can do more than that. Machine learning monitors all the sensors detecting potential problems before they occur and drivers can get a prescriptive alert of what is going on with their vehicles.
Driverless cars
Autonomous vehicles are a much-discussed topic in the automotive industry. Most manufacturers have announced timelines for introductions of self-driving cars. Providing vehicles with artificial intelligence could make them smart enough to become driverless.
Tesla is in the lead in developing a self-driving car. Waymo by Google has been tested on roads in the US for a while now. A large advantage that AI provides autonomous vehicles is learning and adjusting based on new data. Also, all the data a vehicle collects is available to the rest of the fleet, creating network-effects whereby as more cars collect more data, the AI used for self-driving can become trained to be more accurate. The limiting factor here is the ability to work with increasing volumes of data and develop an AI platform that scales to process massive volumes of data.
Driver Assistance
As it may still take a while before autonomous vehicles arrive, a more popular AI feature to use now is driver assistance. Mercedes-Benz and others have introduced their driver assistance packages and implement them in their newest vehicles to improve the driver’s experience.
Insurance
Trying to predict the future is vital to Insurance companies. Embracing AI-technology will improve that capability by doing risk assessments in real-time and the ability e.g. for customers to file claims when accidents occur.
The collaboration between insurance companies and machine learning technology has created Insurtech. Insurance companies want access to speed, acceleration, and navigation data to provide more accurate premium estimates for individual users, and usage-based insurance ML-technology creates drivers’ risk profiles based on individual risk factors and then predicts drivers’ behaviour based on previous actions.
Successful applied ML plays a vital role in making new initiatives and automotive data product programs a success. Data engineering is a vital and time-consuming part of this process and has to solve the complex challenge of working with local, global, and event-based data that will be consumed from different data sources and with varying cadences. Instead of increasing data engineering headcount to solve these complex problems, an alternative solution is to start sharing data features across multiple models and across multiple teams and lines of business.
The need of a feature store for data management
Depending on where you are in your journey of managing data pipelines, ML-platform integration and successfully taking ML-models into production in intelligent apps, data complexities and related risks of technical debt and inefficiencies will increase.
Looking at best practices of hyperscale AI companies such as Uber, Twitter, and Airbnb - they all had a common need to build a feature store, a central repository/data warehouse for machine learning. The feature store facilitates an operating model that accelerates ML-projects by making ML-features reusable, cost-effective, verifiable, governed, and searchable.
To give an idea of possible pain points in your current operations we illustrate what happens during the model development stage of a typical model ML-model lifecycle. The data scientist will build common features and features that are specific to the model. This process can cause a couple of pain points such as:
- feature engineering and computation is repeated for the same features with each iteration of the model;
- every model has a customized pipeline which is hard to manage when numbers of models in training and production increase;
- it’s not trivial to monitor and track the lineage from data to feature to model when features and their metadata are not centrally stored;
- automated ML-frameworks for rapid model development such as for feature engineering and hyper-parameter tuning are limited to specific models and make them less reusable.
A feature store facilitates reusability of features across the organisation as features are visible by search to all potential users in multiple business domains. In model development teams and in model serving teams it becomes possible to discover, store and manage their diverse feature sets. The table below highlights automotive models where common features are created and used in different models
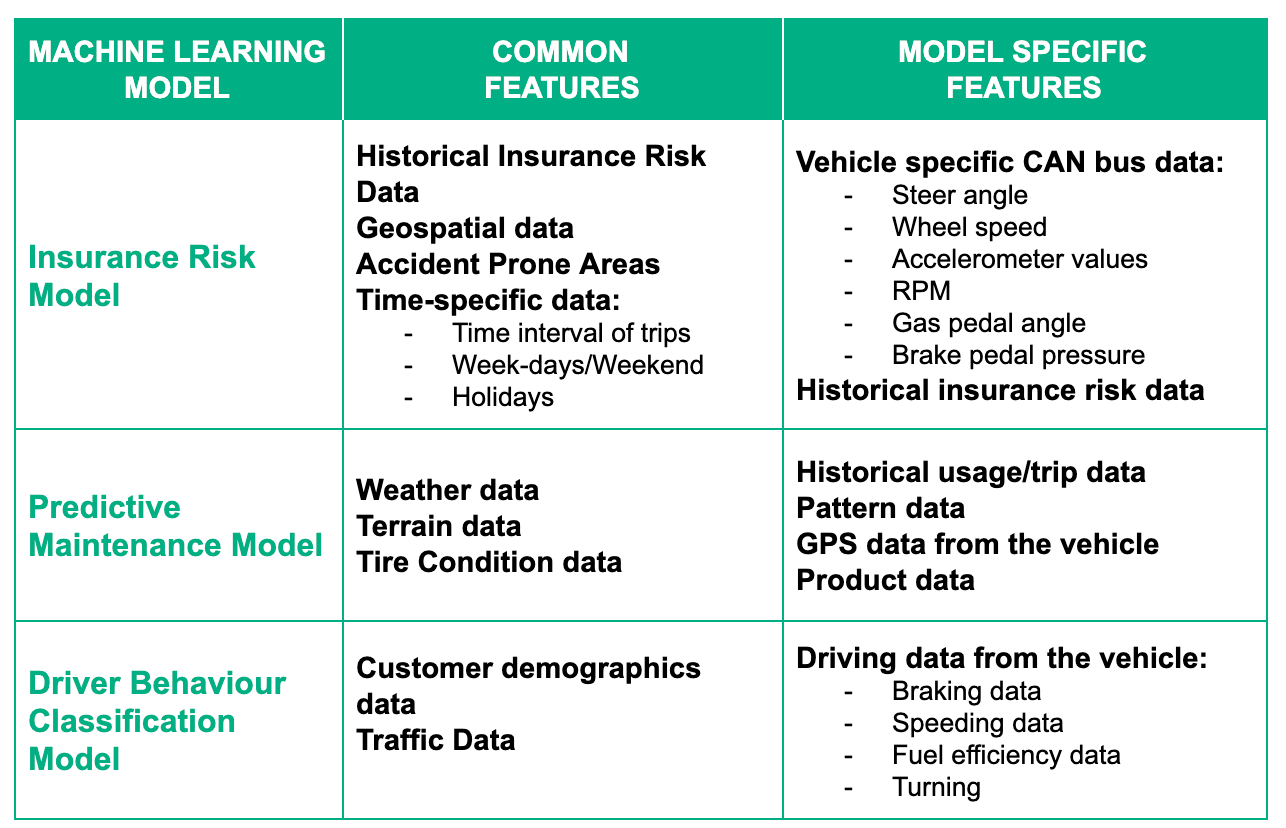
The table illustrates how some of the features are commonly used across different models and if stored properly can be reused and provide faster time-to-market and operational gains.
Should you build or buy a Feature Store?
Uber, Twitter, Airbnb, and others that spearheaded the development of the feature store for training and serving their models have made this data layer for AI the basis for their industrialised ML deployments.
Deciding between building and buying will depend on your strategy and we have recently published an article “How to build your own Feature Store” that I recommend you to read if you’re interested in building one yourself. But, in general one could say: “build what differentiates you, and buy what accelerates your ML-projects”. In different presentations from companies that have built their own feature stores, we have seen that feature store projects can take up to a year to complete and longer.
In case you choose to buy an enterprise-ready feature store then it’s vital that you figure out how to integrate the feature store into your data pipelines and current machine learning operations. We wrote another interesting article “MLOps with a Feature Store” that will help you understand some of the challenges for automating and integrating machine learning into your operational IT environments.
Hopsworks Feature Store
The Hopsworks Feature Store enables teams to work effectively together , sharing outputs and assets at all stages in machine learning (ML) pipelines. In effect, our Feature Store:
- acts as an API between Data Engineering and Data Science, enabling improved collaboration between Data Engineers, who engineer the features, with Data Scientists, who use the features to train models.
- enables features to be registered, discovered, and used as part of ML pipelines, thus making it easier to transform and validate the training data that is fed into machine learning systems.
- meets traditional Enterprise Computing requirements with support for access control, feature versioning, governance (e.g., terms of use), model interpretability, privacy, and auditing.
- is horizontally scalable and highly available.
- fits seamlessly into both development environments and ML pipelines – whether you are in the Cloud or on-premises, with integrations for Databricks, AWS Sagemaker, and Kubeflow.
In addition, Hopsworks provides a data processing and model training platform that makes it easy to do deep learning with very large datasets at scale on tens or hundreds of GPUs in parallel. We have a number of automotive customers using Hopsworks on-premise and public cloud for their deep learning projects related to autonomous vehicles.
Hopsworks AB is a specialist in data for AI and large scale distributed deep learning. Funded by leading European VC’s such as Inventure and Frontline Ventures. The company has offices in Stockholm, London, and Palo Alto.