Feature Pipelines in Production with Hopsworks
Code, Deployment & Monitoring
In this post, we will look at how to put feature pipelines into production using Hopsworks.

Introduction
In this post, we will look at how to put feature pipelines into production using Hopsworks. Feature pipelines are code segments responsible for creating features and registering them with feature stores. Feature stores make these features available for data scientists to train models or for production models to make predictions.
Productionizing these pipelines regularly refreshes features so new models can retrain and production models make sharper predictions. As we've seen in previous posts, Hopsworks supports various frameworks like Pandas, Spark, and Flink for building pipelines. It also allows us to create external pipelines with Snowflake. Now let's focus on the productionization sequence - deployment and monitoring.
Managing Codebases
Code for generating features typically resides in repositories like GitHub, GitLab, or BitBucket. Hopsworks integrates with these tools to automatically pull our repositories into its environment for execution.
For example, once GitHub credentials are configured, a cloned repository containing feature pipelines is available in Hopsworks. We can directly run jobs from this codebase with a single click.
Executing Pipelines
Hopsworks offers flexibility in where pipelines execute. It provides native compute for Spark, Flink, or Python pipelines. Alternatively, we can use existing infrastructure like Databricks or custom Python environments.
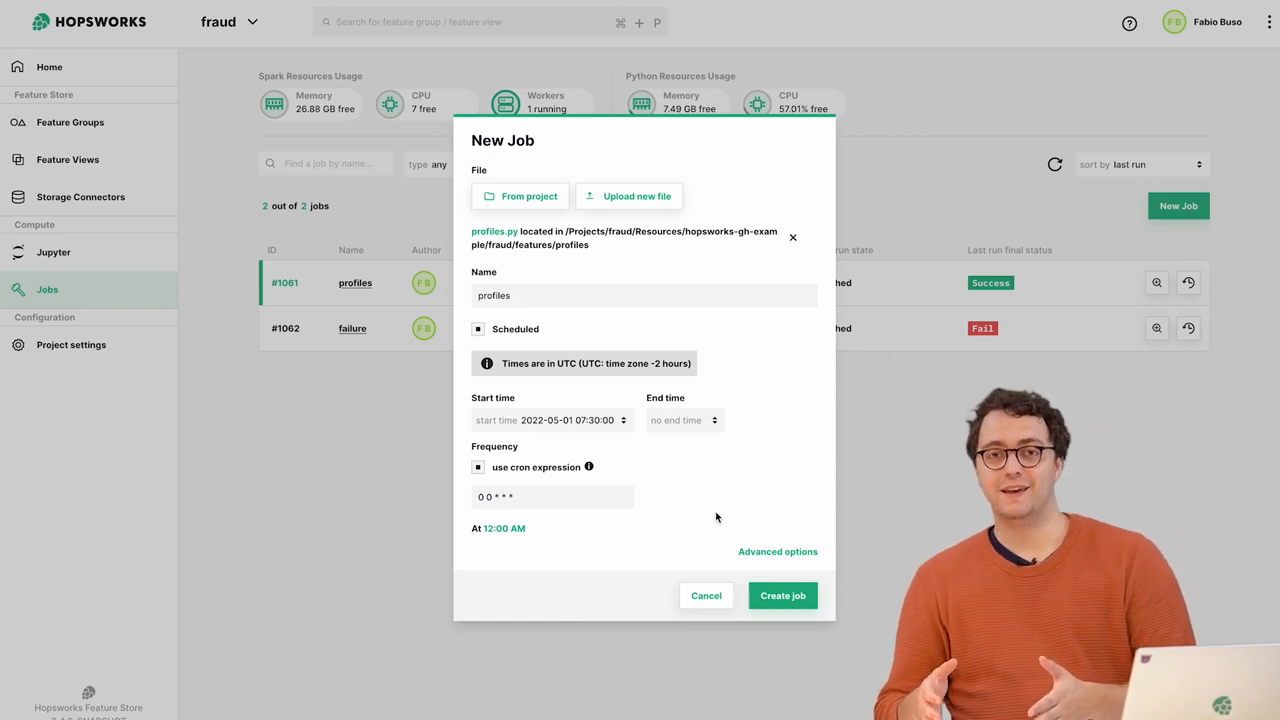
We will focus on executing pipelines natively within Hopsworks by queuing jobs and monitoring them. We can create jobs via UI or APIs:
The scheduler supports cron expressions for advanced scheduling. An interesting capability is time travel - we can set start times in the past to backfill historical data. Hopsworks will execute jobs serially as if they ran on schedule earlier. This helps us create training data or warm up production models with past behaviors.
Monitoring Failures
It's critical to monitor if production pipelines fail unexpectedly. Hopsworks has alert integrations with email, Slack, and Kafka for this purpose.
For example, with Slack alerts:
- Hopsworks admin configures webhook
- We define "receivers" per project - who gets notified for which events
- On pipeline failure, a critical Slack alert is sent with metadata
More advanced data and quality monitoring is also available in Hopsworks but not covered here.
Summary
In summary, we looked at end-to-end productionization of feature pipelines with Hopsworks - managing code, deployment, scheduling and monitoring. This keeps features fresh for improving models daily through a reliable, observable pipeline.
Watch the full video on how to productionize feature pipelines with Hopsworks: