Introducing the Serverless Feature Store
Hopsworks Serverless is the first serverless feature store for ML, allowing you to manage features and models seamlessly without worrying about scaling, configuration or management of servers.

Why Serverless?
If you build an operational application in the cloud, you are probably using some data and compute services (that is, infrastructure) to support it. You would probably like your service to be highly available, elastic (scale up and down resource usage in response to demand), and meet performance SLAs. Serverless infrastructure, from serverless databases to lambda functions, enables developers to build such operational and analytical applications without having to install, configure, and operate the infrastructure that powers them.
Until now, Data Scientists have not had the same possibilities to use serverless infrastructure as application developers. The ML (machine learning) infrastructure space has moved very fast in recent years, with new platforms such as feature stores, model serving, and vector databases becoming indispensable building blocks for operational and analytical AI-enabled applications. Serverless notebooks, such as Colab, and experiment tracking, such as W&B, have already shown the demand for serverless ML infrastructure.
Now, we are launching Hopsworks serverless with support for hosted features and models. Hopsworks Feature Store provides offline and online storage of features for both creating training data and serving features to models. Hopsworks also provides a model registry and model serving, based on KServe. If you are building AI-enabled applications, you can now focus your energy on your pipelines and modeling, not the ML infrastructure.
The benefits of Hopsworks Serverless for Data Scientists and ML Engineers are:
- Rapid start - get a project environment ready in seconds
- Python-centric experience
- Automatic operation and upgrades
- Always on environments
- Time unlimited access
- Always free tier - your features and models will always be available.
A Python centric feature store
Apache Spark dominated as the feature engineering platform of choice for the first generation of feature stores, including Hopsworks. Hopsworks 3.0 is now also the first Python centric Feature Store that provides a library and Python APIs for seamlessly transferring data to/from your feature store. Serverless makes sense now we have a Python native feature store. We have developed a number of new tutorials on fraud, churn, surfing!, and for well-known ML datasets to help show you how to build production ML systems using Python. Hopsworks Serverless manages your features and models and provides API access to them using Python.
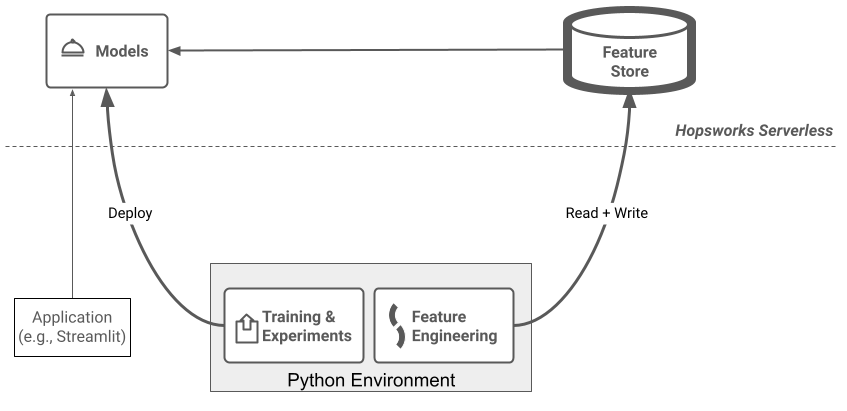
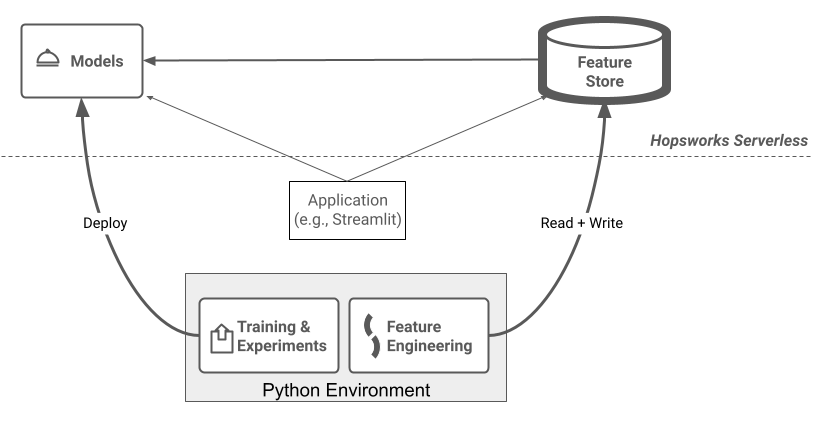
Figure 1. Hopsworks Serverless manages your features and models and provides API access to them using Python.
Build Prediction Services, not just Models
In our new tutorials, we show you how to build a complete prediction service with feature pipeline(s), a training pipeline, and a user-interface - all in Python. Minimal functioning prediction services add huge value in communicating the value of ML projects to stakeholders. So, as a Data Scientist or ML Engineer, in your sprint, instead of just showing the expected benefits of your model using a spreadsheet or a report, you can now develop a fully functioning prediction service in Python. You can show how your new prediction service will plug into your data infrastructure to power its features, how your service or application will behave when it is AI-enabled, and how you can feed back feature logs and prediction logs to build a Data-for-AI Flywheel (also here). And you can do it all with Python on serverless ML infrastructure.
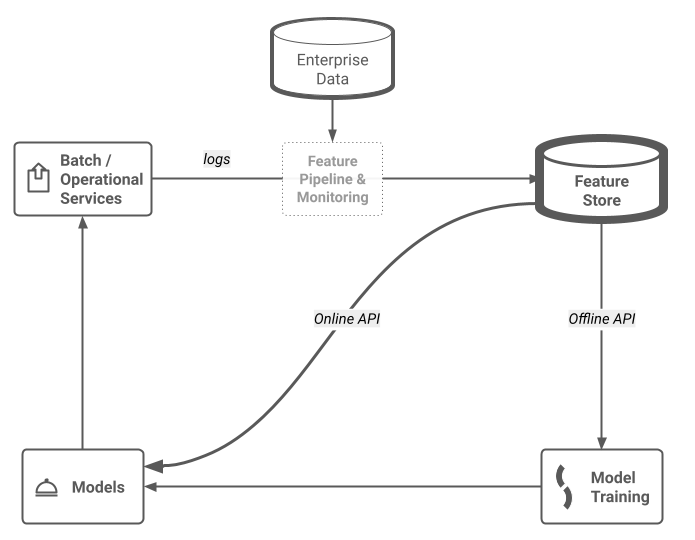
Figure 2. Data-for-AI Flywheel: feeding back logs to the feature store produces more training data, better models, attracting more users, generating more logs, and so on.
Tightening the ML Product Feedback Loop
Serverless ML is part of the MLOps paradigm. MLOps is a set of automated software development processes to version and test ML software systems. MLOps should help improve iteration speed for developers, increase confidence in the correctness of ML software artifacts, and make ML pipelines reproducible and explainable. With serverless ML, new possibilities arise for how to make incremental changes to AI-enabled products that are continuously built, tested, and deployed to customers. By building a complete prediction service in your initial development cycle, instead of just fitting data to your model, you can more quickly get feedback on the system and iterate faster on making changes.
Modular Serverless ML Systems
Hopsworks Serverless is a modular platform that can easily be plugged together with other serverless ML services to build analytical or operational ML-enabled applications. Hopsworks can manage your features and models, but does not provide general purpose compute. (Note, Enterprise Hopsworks still provides Spark/Python/Flink compute).
You will also need compute to run your Python feature pipelines and training pipelines, and you may also want to manage your ML experiments and use notebooks for prototyping (or production!). Other serverless ML services that integrate seamlessly with Hopsworks Serverless include notebooks (Colab), experiment tracking (W&B, DVC, CometML, Neptune, ClearML, Valohai), and orchestration tools (Github Actions, Anyscale, Sagemaker, Databricks, Outerbounds, Heroku, Dagster, Astronomer), streaming pipelines (Decodable, Bytewax), and model monitoring (Arize, Gantry, Evidently, Superwise, WhyLabs). Hopsworks plugs in seamlessly with services such as these, to help you build entire operational or analytical ML systems on serverless infrastructure.
To Serverless or not, that is the question
Hopsworks Serverless offers many advantages to both smaller organizations who need to build something quickly to larger Enterprises, where developers want to accelerate building a proof-of-concept. Hopsworks Serverless is currently in beta, and is not yet available as a paid service.
Hopsworks Serverless may not be suitable for all Enterprises - there are both performance and resource quotas, and data ownership may be a blocker for some Enterprises, as the data is managed in our Hopsworks cloud account. Luckily, for those of you who like Hopsworks, but cannot use Hopsworks Serverless, you can use our cloud managed platform, where Hopsworks runs entirely in your cloud account (AWS, Azure, GCP) or on-premises.
Try out Hopsworks Serverless today and let us know in our community forum what you think.